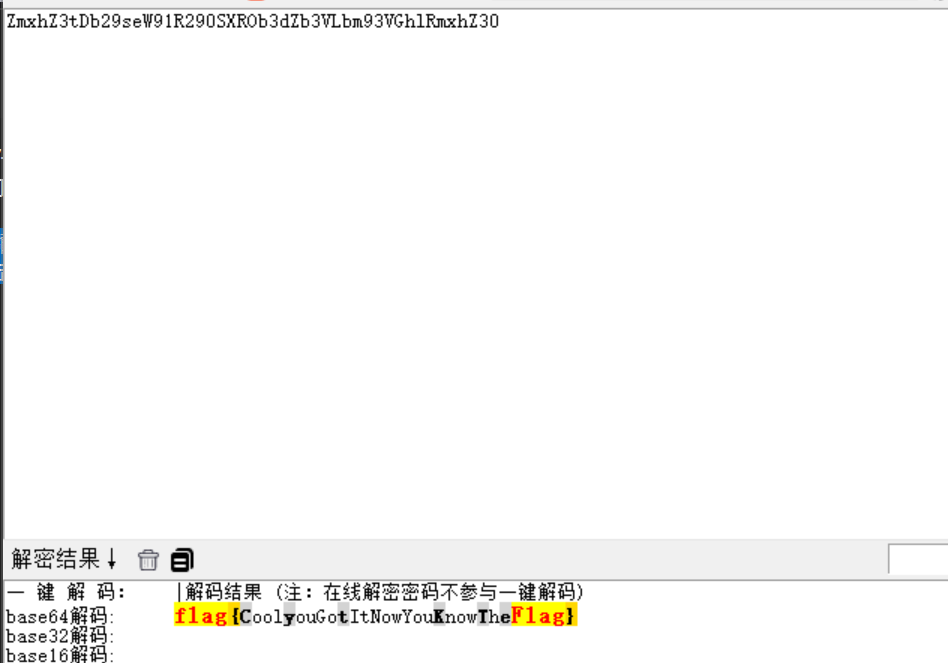
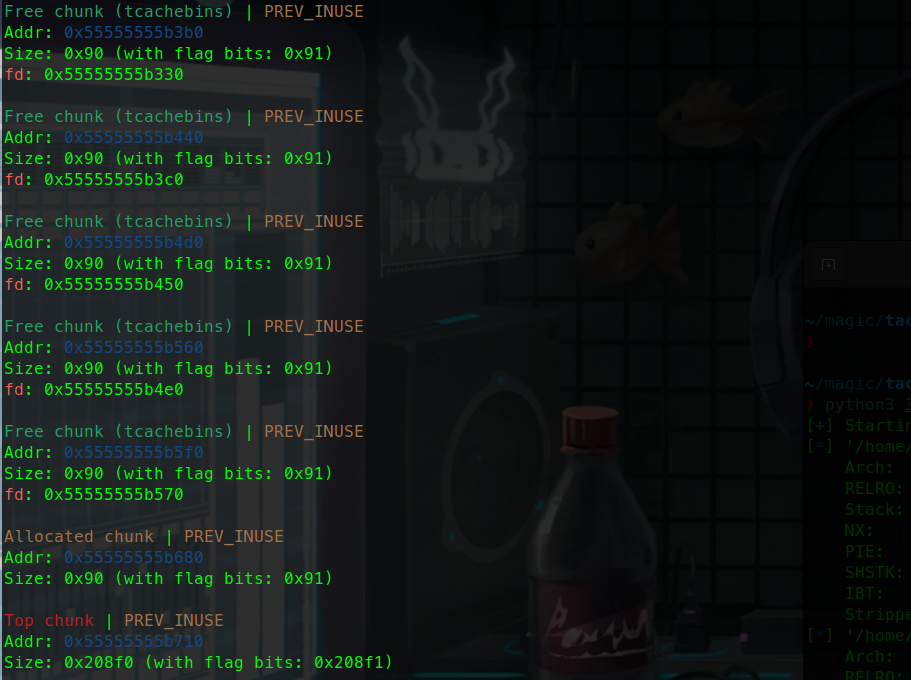
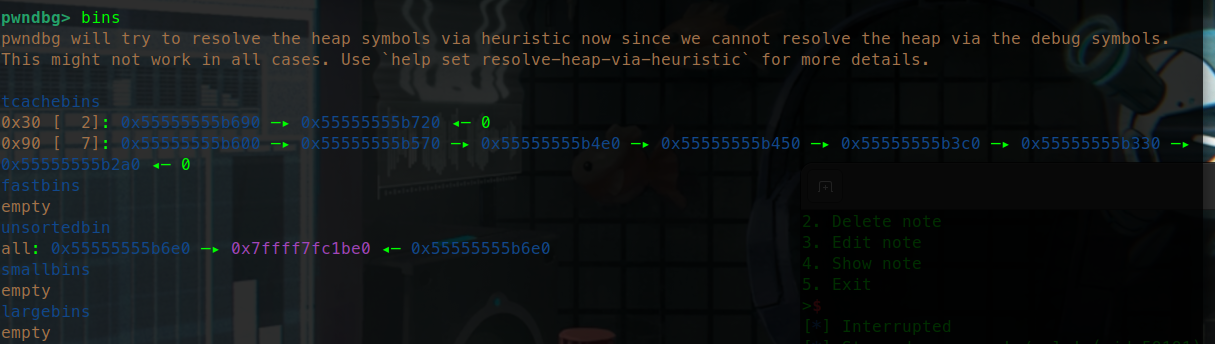
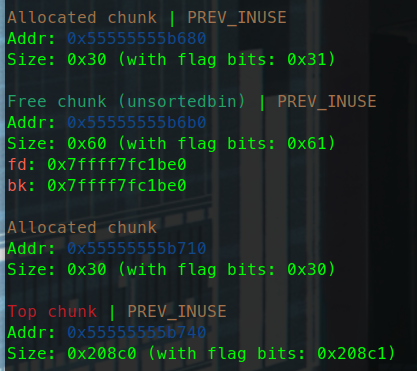
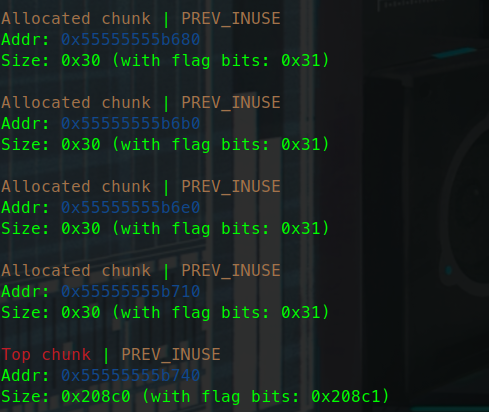
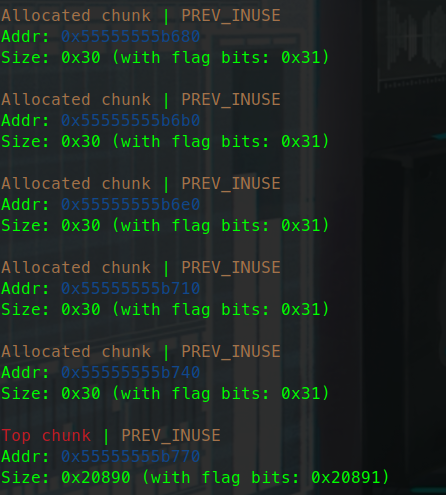
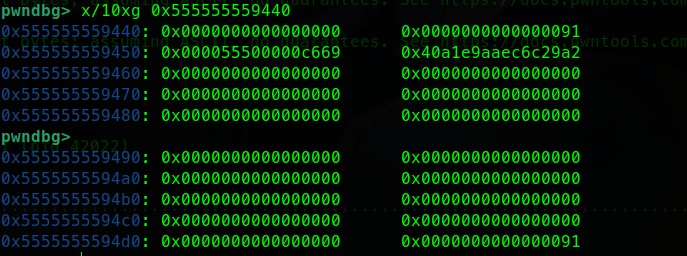
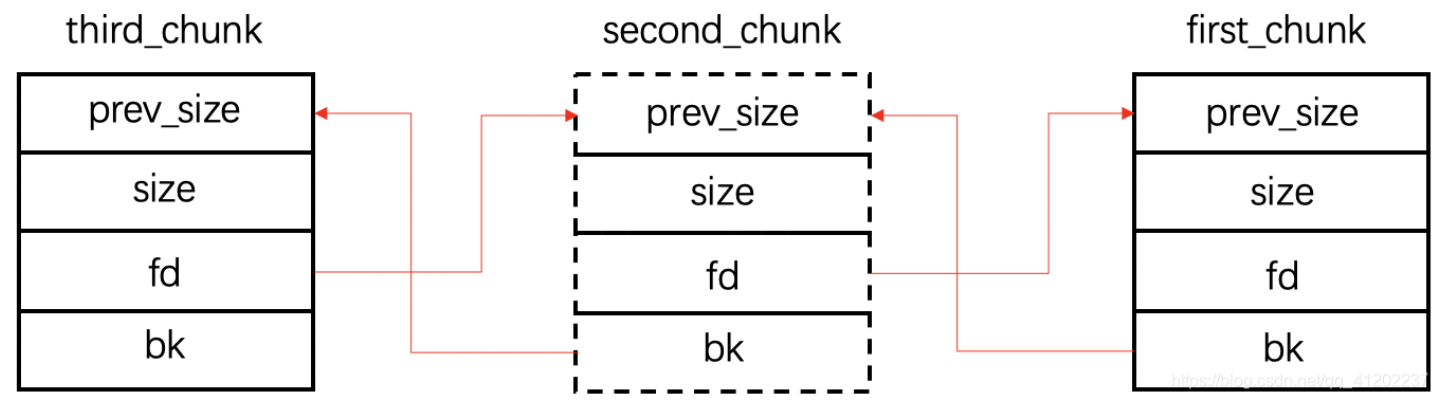
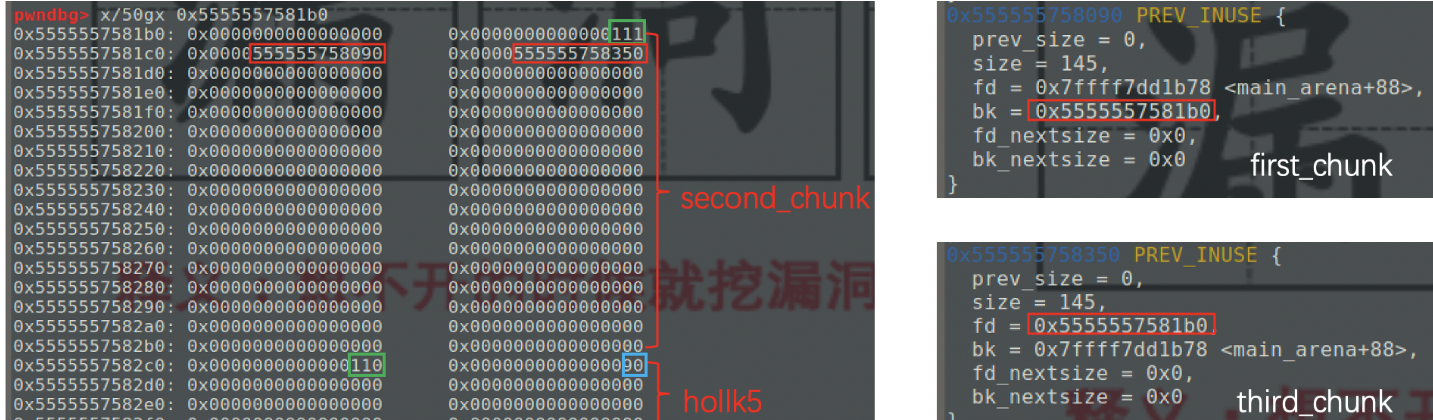
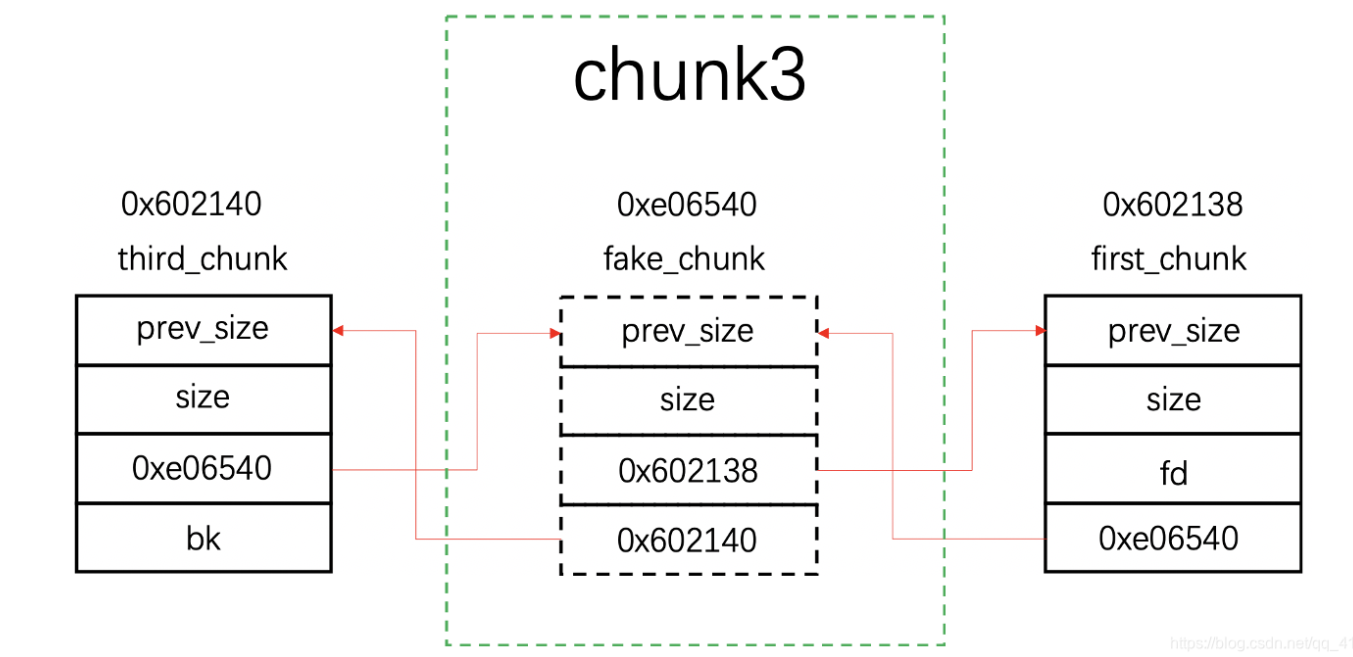
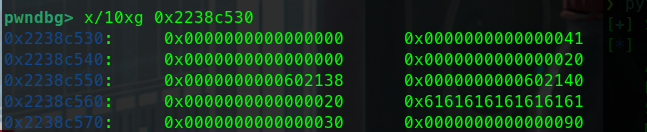
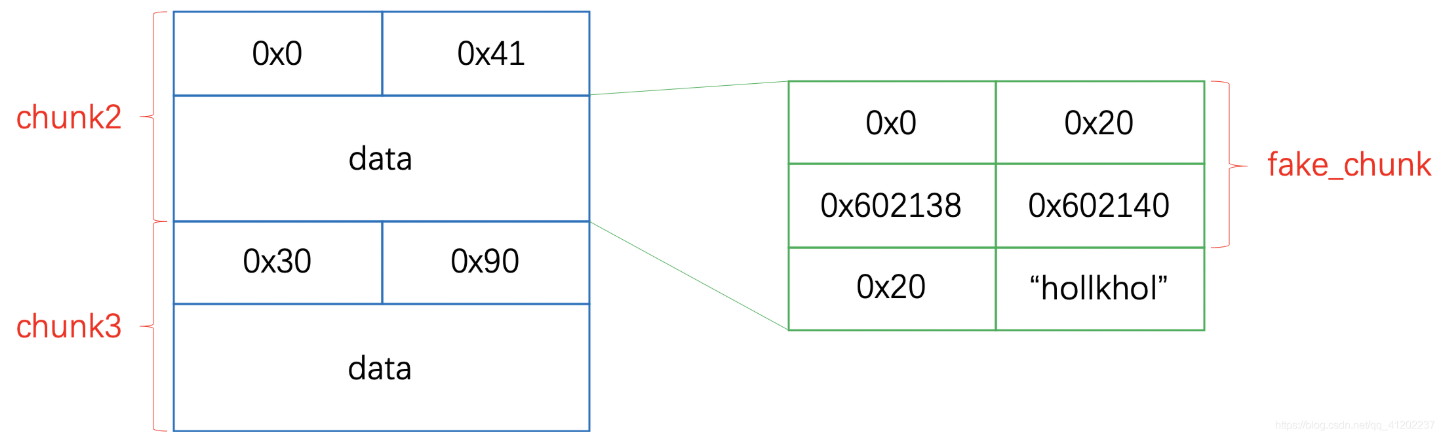
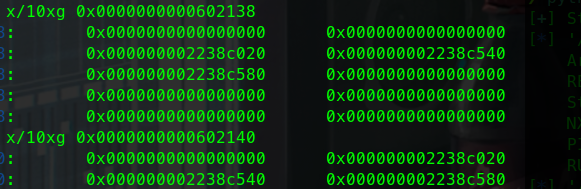
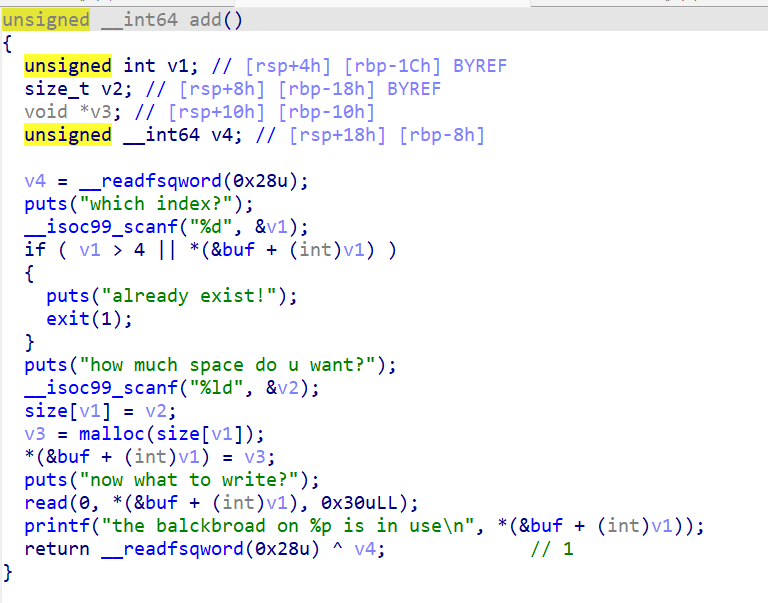
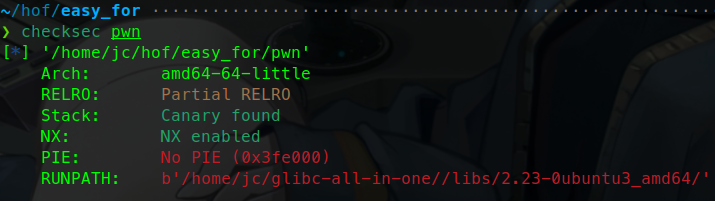
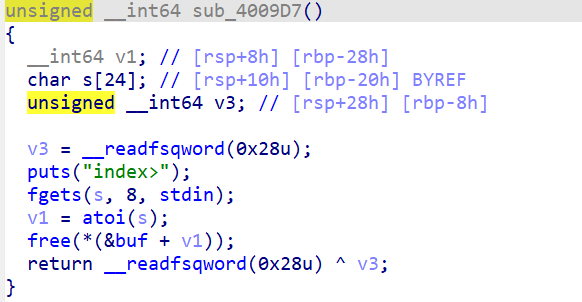
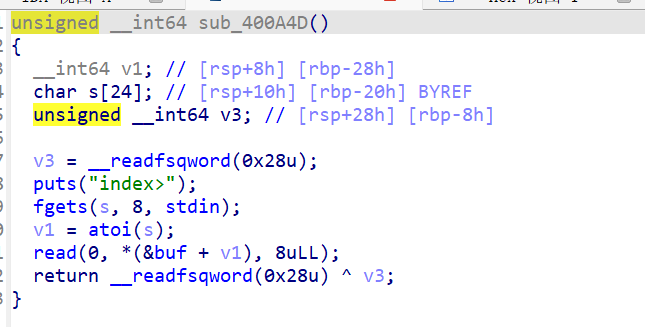
更换glibc版本
1.下载glibc_all_in_one
步骤 1:安装依赖工具
bash: sudo apt install patchelf git
步骤 2:下载 glibc-all-in-one
bash: git clone https://github.com/matrix1001/glibc-all-in-one.git
cd glibc-all-in-one
2.下载对应版本的glibc(2.23为例)
./update_list
cat list | grep 2.23
./download 2.23-0ubuntu3_amd64
问题:

出现sudo: unable to execute ./update_list: No such file or directory错误,看似矛盾(ls明明显示文件存在),实际是因为update_list脚本的解释器路径无效或脚本本身存在损坏。具体解决步骤如下:
1.检查update_list脚本的头部解释器
# 查看脚本首行 head -n 1 ./update_list
正常输出应为:
#!/bin/bash
3.更换
❯ patchelf –set-interpreter /home/jc/glibc-all-in-one/libs/2.23-0ubuntu3_i386/ld-2.23.so
–set-rpath /home/jc/glibc-all-in-one//libs/2.23-0ubuntu3_i386/
./pwn160

注意路径!!!
4.检查

5.换回去

1.patchelf –remove-rpath ./hacknote
清除之前通过--set-rpath指定的 glibc 库路径
2.patchelf –set-interpreter /lib/i386-linux-gnu/ld-linux.so.2 ./hacknote
恢复系统默认的动态链接器
64 位程序的默认链接器是/lib64/ld-linux-x86-64.so.2,但 32 位程序必须使用 32 位链接器/lib/i386-linux-gnu/ld-linux.so.2(若路径不同,可通过dpkg -L libc6:i386 | grep ld-linux查询)。
另一种方法
编译不同版本的glibc
首先要使用不同版本的glibc,我们需要有不同版本的 glibc 可执行文件,也就是 libc.so 和 ld.so。这两个文件是程序运行时所需要的文件按。
当然也可以在网上找已经编译好的libc,但是找不到时自己编译的步骤如下:
glibc-all-in-one:是一个开源项目,里面有各种版本的glibc 源码。
然后编译glibc 的命令如下:
git clone https://github.com/matrix1001/glibc-all-in-one
cd glibc-all-in-one
chmod 777 build download extract
sudo ./build 2.29 amd64 #编译glibc
sudo ./build 2.27 amd64
sudo ./build 2.23 amd64
加载glibc
对于一个可执行文件,可以通过 LD_PRELOAD 来指定其使用 对应版本的 glibc。但是这里需要注意,还得指定一个对应版本的 ld.so,不然 可能会出现问题。
使用方法如下,我习惯将 ld.so 和 libc.so.6 放到与程序同目录下。也可以自己改变路径。
p = process([“ld.so”, “./test”],
env={“LD_PRELOAD”:”libc.so.6”})
通过上面的操作,我们就可以指定 test 加载对应版本的 glibc。
更换动态链接库











.jpg)